|
Jean-Claude DEROUBAIX°
Les déclarations gouvernementales se suivent et se ressemblent. Exploration d'une chronique textuelle
Les corpus de discours politiques émis successivement sur d'assez longues périodes présentent souvent un aspect particulier du point de vue lexical: les déterminations du vocabulaire par les conflits, idéologies et approches partisanes semblent subordonnées à un phénomène de proximité lexicale entre discours, liée à la proximité temporelle. Ce constat a suscité plusieurs approches en vue de comprendre et de disséquer en quelque sorte ce phénomène chronologique. André Salem propose une extension des méthodes d'analyse des "spécificités" au cas chronologique. Pour chaque forme lexicale suffisamment attestée dans le corpus, il peut définir soit les périodes regroupant plusieurs parties où elle apparait trop ou trop peu souvent que ne le laisserait supposer une répartition moyenne, soit les moments d'accroissement ou de décroissance sensible de l'emploi de cette forme. L'immense intérêt de cette méthode réside dans la possibilité d'étudier finement comment une forme apparait et disparait dans un vocabulaire en évolution. Cependant, de même que la méthode des spécificités se complète souvent par des analyses plus globales des corpus, il faut pouvoir définir des méthodes globales d'analyse de la "chronologicité" des séries textuelles. Dans ce domaine, les travaux de Dominique Labbé ne peuvent être passés sous silence, car son approche du renouvellement met en évidence, dans ces séries, l'existence d'un vocabulaire général et de vocabulaires spécialisés qui s'introduisent, selon les nécessités du moment, dans le discours politique. Nous nous proposons d'exposer ici une tentative de décomposition de l'aspect chronologique basée sur des méthodes de classification automatique à partir d'une chronique textuelle composée de l'ensemble des déclarations gouvernementales belges (dg dans la suite de ce texte) prononcées entre 1944 et la fin de l'État national, soit 1992. Le corpus comprend les trente-huit déclarations faites à cete époque devant le Parlement. Dans le système politique belge de type bicaméral, la formation du Gouvernement se déroule suivant un processus qui doit plus à la coutume parlementaire qu'au droit constitutionnel proprement dit. Cependant, quel que soit le processus poursuivi par le Roi pour composer un gouvernement - consultations, nomination d'informateurs, d'un formateur, désignation de l'équipe ministérielle - la dernière étape consiste en l'obtention obligatoire de la confiance des deux Chambres du Parlement, le Sénat et la Chambre des représentants. Cette confiance n'est accordée que sur la base d'une déclaration faite au nom du Gouvernement par le Premier ministre devant chacune des Chambres. Cette déclaration contient les éléments du programme du nouveau cabinet et permet aux parlementaires d'exprimer un jugement politique sur l'équipe qui se présente à eux. Le système électoral du pays durant la période étudiée est de type proportionnel; cela rend relativement difficile la constitution de gouvernements homogènes mais favorise la constitution de coalitions; la scission des partis nationaux - sociaux-chrétiens, libéraux et socialistes - en partis homogènes linguistiquement (Parti socialiste et Socialistische partij, Parti de la Liberté et du Progrès et Partij voor Vrijheid en Vooruit, Parti social-chrétien et Christelijke Volkspartij) a encore renforcé cette tendance à la dispersion des partis représentés au Parlement. La conjugaison de ces éléments avec la création de partis dits "communautaires" aboutit à la constitution de cabinets pouvant comporter jusqu'à six partenaires. Dans la période qui nous occupe, il n'y eut en fait que quatre gouvernements homogènes, tous sociaux-chrétiens entre 1950 et 1954, et en 1958. Il faut aussi souligner qu'à l'exception de deux courtes périodes (1945-1947 et 1954-1958), le ou les partis sociaux-chrétiens ont été en permanence au pouvoir, seuls ou associés soit aux socialistes soit aux libéraux. La Belgique est donc gouvernée au centre, car c'est là que se situe la famille sociale-chrétienne, parfois au centre gauche avec les socialistes, parfois au centre droit avec les libéraux. C'est cette césure gauche/droite, certes édulcorée par les nécessités du pouvoir et les compromis inhérents à la constitution de coalitions, que nous pensions a priori retrouver dans l'étude lexicométrique des déclarations gouvernementales. Mais l'analyse du vocabulaire des trente-huit déclarations prononcées devant le Parlement depuis la seconde guerre mondiale nous a surtout permis de mettre en évidence la conjonction de deux sources de structuration des choix lexicaux: une évolution chronologique du vocabulaire et une certaine opposition entre discours volontariste et discours de gestion. L'aspect chronologique est dominant et se marque dans les analyses factorielles des correspondances (AFC) du tableau des formes.
Les déclarations gouvernementales se suivent et se ressemblent
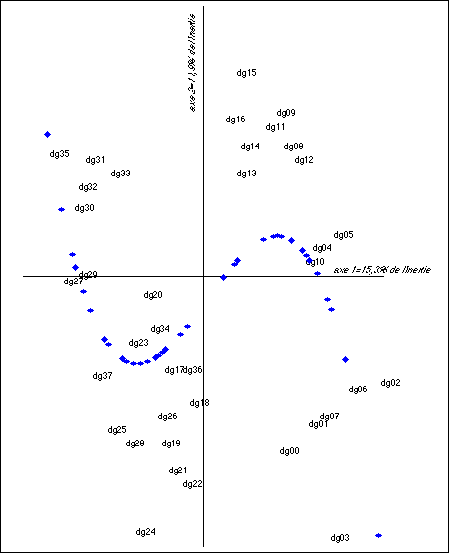
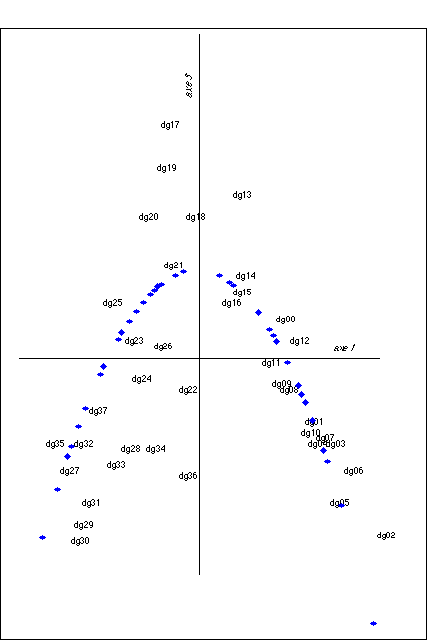
La structuration du corpus par le temps se manifeste tout d'abord massivement dans la bipartition de l'ensemble des déclarations visible sur le premier plan factoriel issu de l'analyse des correspondances du tableau des formes simples [voir Figure 1]. Les déclarations antérieures à 1965, c'est-à-dire celles qui ont été prononcées de 1944 (Pierlot-dg 00) à 1961 (Lefevre-dg 16), se regroupent toutes dans la partie droite de l'axe horizontal tandis que les déclarations les plus récentes se situent toutes dans la partie gauche. On sait combien, pour les historiens de la vie politique belge, il est une césure importante de cette vie, qu'ils situent au début des années 1960. Els Witte et Jan Craeybeckx, par exemple, ne distinguent que deux grandes périodes dans l'après-guerre belge: de 1944 à 1960 et de 1961 à 1987.D'une certaine façon, cette coupure se justifie par de nombreux éléments politiques. 1961 voit s'exacerber les tensions linguistiques, qu'on ne nomme pas encore communautaires, entre Wallons et Flamands; 1959 est l'année de la mise en application de la paix scolaire qui fige les positions entre les partisans de l'école laïque et ceux de l'école catholique et rend possible, entre autres, la création d'un nouveau parti libéral (PLP) sur la base d'une ouverture du parti libéral à une partie du centre droit catholique; 1960 marque aussi la prise de conscience du redéploiement industriel qui s'opère globalement de la Wallonie vers la Flandre, des régions de vieille industrialisation vers des régions, il y a peu, encore rurales. Évidemment, a posteriori, nous savons bien que ces années-là marquent aussi le début d'une période de croissance économique dont les effets sur les plans sociaux, politiques, éducatifs et culturels ne seront pas à négliger. Il parait logique de retrouver une césure d'une telle importance dans le vocabulaire des déclarations gouvernementales. Cependant, nous devons constater que le premier gouvernement de la nouvelle période de l'histoire de la Belgique (dg 16 - Lefèvre-Spaak - 1961) voit sa déclaration continuer à se rattacher à l'ensemble précédent. Comme si ce gouvernement, qui inaugure les "Golden sixties", le processus de transformation de l'État unitaire en État fédéral et le désengagement du système colonial (le Congo est indépendant depuis 1960, le Ruanda-Urundi le deviendra en 1965), faisait tout cela avec le vocabulaire et les préoccupations du passé, sans anticiper le parler politique à venir! Au-delà de cette fragmentation des déclarations en deux blocs successifs, le temps structure plus fortement et de manière plus fine l'évolution du vocabulaire des programmes gouvernementaux. En effet, si l'on classe l'ensemble de nos déclarations suivant, d'une part, leur succession naturelle dans le temps et, d'autre part, suivant leur ordonnancement le long de l'axe 1 (horizontal) de l'AFC, nous pouvons mesurer la similitude entre ces deux ordres et, par exemple, calculer le coefficient de corrélation de rang de Spearman; une valeur de rs de 0,814 indique une forte association entre les rangs des déclarations dans les deux séries, association qui s'intensifie lorsqu'on exclut du calcul quatre déclarations trop spécialisées ou très courtes (dg 26, dg 28, dg 34 et dg 36); nous obtenons dès lors un rs égal à 0,938 [Annexes Tableau 7 en annexe].D'un point de vue heuristique, on doit aussi constater la forme caractéristique prise par la projection des points correspondant aux déclarations sur les plans formés par le premier axe avec respectivement l'axe deux et l'axe trois de l'AFC. Sur le premier de ces plans, le nuage épouse la forme d'une courbe du troisième degré en S couché [voir figure 1 en annexe] et sur le deuxième, on distinguera l'esquisse d'une parabole [voir figure 2 en annexe]. Pour faciliter la lecture, nous avons superposé à la figure 1 une courbe représentant un polynôme du troisième degré obtenue par ajustement des moindres carrés à partir des coordonnées des déclarations actives uniquement.yi = -6,48.xi3 + 0,28.xi2 + 0,73.xi -0,05 Les yi sont les valeurs prédites des coordonnées sur l'axe 2 étant donné les xi, coordonnées sur l'axe 1. De même nous avons superposé une courbe représentant une fonction du second degré des coordonnées sur l'axe 1 obtenue par ajustement par les moindres carrés zi = -2,700901.xi2 -0,01,191073.xi + 0,1626254 Les zi sont les valeurs prédites des coordonnées sur l'axe 3 étant donnés les xi, coordonnées sur l'axe 1. On sait que ces formes en S couché et paraboliques sont la représentation factorielle de tableaux qui présentent une structure avec une bande diagonale chargée, du moins si l'on ordonne les lignes et les colonnes de ces tableaux suivant l'ordre de leurs coordonnées sur l'axe 1 [Benzécri 1976, Salem 1988]. Comme cet ordre est proche de l'ordre chronologique dans lequel ces discours ont été rédigés, il y a là le signe indubitable d'une influence du temps sur le choix et l'emploi du vocabulaire. Nous conviendrons dès lors qu'il existe une forte composante "chronologique" associée au premier axe de l'analyse factorielle. Cependant, l'examen attentif du AnnexesTableau 7 nous rappelle que cet effet n'est pas strict mais fonctionne plutôt par sous-ensembles. Aussi la coupure est-elle remarquable entre dg 15 et dg 16, dont le rang dans les deux séries - naturelle et factorielle - est identique, terminant bien la première des deux périodes articulées autour de 1960. La mise en évidence de cet aspect chronologique amène à s'interroger sur la caractérisation de cet axe du "temps" par les formes associées.
Les méthodes d'analyse d'une série textuelle chronologique Si l'étude des déclarations conduit à faire l'hypothèse d'une tendance à l'évolution chronologique dans l'emploi et la "création" du vocabulaire politique, c'est assurément du côté de la régularité de la répartition des formes que nous trouverons des indications sur la signification de cette dérive temporelle. L'examen des projections des points représentant les formes sur le premier plan factoriel nous donne une image de cette évolution, dont nous avons donné une première interprétation [Deroubaix-Gobin 1987]. Cette première approche, qui met clairement le phénomène "chronologique" en évidence, nous incite cependant (et surtout) à affermir nos conclusions et à affiner l'analyse plus qu'à fournir des assurances. L'analyse factorielle des correspondances joue ici pleinement son rôle de méthode heuristique. La méthode utilisée repose sur une certaine modélisation floue de ce que peut être le processus chronologique sous-jacent. De la même manière que Dominique Labbé [Labbé 1990], nous supposerons qu'il provient du renouvellement plus ou moins permanent du vocabulaire politique suivant les problèmes du moment, qu'il y a donc apport, "invention" de nouveaux mots et concomitamment disparition de certains d'entre eux. Mais ces mots ne forment pas tout le vocabulaire; il subsiste à leur côté un vocabulaire général du corpus comportant tous les mots régulièrement utilisés par tous les textes avec des fréquences assez régulièrement distribuées [Deroubaix 1992]. Mais ce modèle, nous pensons pouvoir le développer sans recourir à l'image des réservoirs multiples, l'un pour le vocabulaire général, les autres pour les vocabulaires spécialisés, mais simplement en cherchant à distinguer, parmi des classes de formes dont la fréquence d'emploi est similaire, celles dont le profil indique un vocabulaire "spécialisé" au sens de D. Labbé et celles dont le profil les rapproche d'un vocabulaire général. En choisissant de créer ces classes de vocabulaire comme partition de l'ensemble des formes lexicales, nous décomposons en quelque sorte le vocabulaire en autant de paquets qu'il y a de vocabulaires spécialisés, plus un consacré au vocabulaire général. Parmi les vocabulaires spécialisés, nous pouvons alors tenter de repérer ceux qui sont de type chronologique. En pratique, la méthode que nous avons utilisée consiste à opérer une classification ascendante hiérarchique (CAH) sur les lignes du tableau lexical (c'est-à-dire sur les profils d'emploi des formes), à choisir une bonne partition et à consolider la partition par une méthode de "centres mobiles". Le principe de la classification ascendante hiérarchique consiste à considérer tout d'abord la partition de l'ensemble des éléments à classer en autant de classes qu'il y a d'éléments, soit N, chaque classe comportant un et un seul élément; à fusionner ensuite les deux classes qui soient telles que de toutes les paires de classes envisageables ce soient celles dont la fusion crée la classe la plus homogène, la moins dispersée. En poursuivant le processus de fusion de proche en proche on obtiendra, à chaque itération, une nouvelle partition de l'ensemble initial, successivement en N, N-1, N-2,…, 3, 2, 1 classes. Pour opérer le choix d'une bonne partition parmi cet ensemble, nous prendrons comme critère la valeur de l'indice d'homogénéité et élirons une partition dont la fusion de deux classes induit la plus grande augmentation de l'inertie intra-classe, autrement dit fait perdre le plus en homogénéité des classes. La partition en six classes correspond à ce critère. Cependant, la méthode de constitution de la partition par une CAH nous garantit que cette partition en six classes est la meilleure de toutes les partitions en six classes que l'on peut obtenir à partir de la partition en sept classes; elle ne nous assure nullement que cette partition est la meilleure en six classes. Nous aurons recours alors à une autre technique de classification automatique afin d'améliorer la partition obtenue. Pour chacune des classes de la partition initiale en six classes (P0) nous allons calculer le profil des centres de classe (qui est une moyenne pondérée des profils des formes incluses dans la classe). Nous allons engendrer une nouvelle partition en six classes (P1) en affectant chaque forme à la classe agrégée autour du centre d'une des classes de la partition P0. En calculant les centres des classes dans la nouvelle partition P1, en affectant les formes aux classes agrégées autour des centres de cette partition P1 pour créer une partition P2 et en réitérant la procédure, nous finirons par arriver à une partition stable qui ne se modifie plus. On peut montrer que la partition obtenue est identique ou meilleure à la partition P0 de départ. La répartition du vocabulaire du corpus en six classes fournit une première indication sur le processus sous-jacent à l'aspect "chronologique" de la distribution du vocabulaire. En effet, nous voyons apparaitre deux types de classes particulières: une classe "stable", relativement bien répartie dans les discours (et donc dans le temps), cinq classes caractérisées chacune par une fréquence d'emploi plus élevée dans une des périodes du corpus; les périodes pouvant se chevaucher (cf. Tableau 1). L'aspect croissant puis décroissant de ces fréquences se lit dans les six colonnes du tableau, à l'exception de la classe 1, que nous avions qualifiée de stable, et de la classe 3, dont la décroissance en bas du tableau est tronquée.Répartition du vocabulaire en six classes (% dans chaque déclaration)
L'examen à l'œil nu de ce tableau nous permet de distinguer facilement les cinq classes en forme de cloche. Il importe cependant de formaliser la démarche, afin d'être à même d'observer des classes de type chronologique parmi un ensemble plus grand de classes. Nous proposons la méthode suivante. La définition que nous avons donnée des classes chronologiques suppose, au sens strict, que les parties du corpus qui recourent plus fréquemment que la moyenne au vocabulaire inclus dans une classe de type chronologique soient connexes dans le temps. D'une manière générale, cela signifie que la droite du temps se subdivise en trois parties: celle qui contient des discours où le vocabulaire spécifique à cette classe est suremployé, et deux parties caractérisées par le sous-emploi, la première précédant la zone de suremploi, la deuxième suivant cette zone. Si l'on représente les zones de sous-emploi par un signe "-" et les zones de suremploi par un signe "+", une classe chronologique, au sens strict, se dessine ainsi: -----------(…)----++++++++(…)++++++-------------(…)------- On peut évidemment essayer de définir la "chronologie" de manière moins forte en admettant aussi des patrons tronqués soit au début du corpus, soit en fin de corpus et accepter ceci: -----------(…)----++++++++(…)++++++ ou ++++++++(…)++++++-------------(…)------- Dès lors que l'on accepte ces modèles de chronologie, nous dirons qu'une classe est chronologique si la succession des zones où le vocabulaire de cette classe est en excès et celles où il est en déficit définissent une bipartition ou une tripartition de l'axe du temps, bipartition ou tripartition ordonnées des déclarations gouvernementales. En représentant nos six classes selon cette technique, nous obtenons les suites: Classe 1 +---+----+-+-+++-+-+++-+-+-+--++++++-+Classe 2 -----------------+-++++++---++----+-+-Classe 3 --------------------+--+-+++++++++++++Classe 4 --------+---+++++-+-+-----------------Classe 5 +-+-+++++++++-+---------------------+-Classe 6 ++++-+++--+-+-----++-++-+-+-+-------+-Aucune des classes ne correspond exactement à un des patrons de classe chronologique; certaines (les classes 2, 3, 4, 5) s'en approchent d'assez près. Nous pouvons mesurer l'écart entre le patron chronologique le plus proche et la structure réelle d'une classe, en comptant le nombre de parties du corpus mal classées. Ainsi, la comparaison de la classe 2 à une tripartition idéale donnerait: Classe 2 : -----------------+-++++++---++----+-+-Idéal en trois : -----------------++++++++-------------Mal classés : 1 11 1 1
Cinq textes apparaissent mal classés. Le nombre de mal classés nous servira de mesure pour la qualité de la partition idéale proposée. Une adaptation de la méthode de Fisher de partitionnement sous contrainte d'ordre total nous permettra de trouver la meilleure des partitions de l'ensemble des déclarations en k classes suivant le critère du nombre des mal classés.
Le découpage optimal de la séquence des sur- et sous-emplois. Méthode Il n'existe pas de stratégie qui nous garantisse dans le cas général de trouver la partition optimale sauf dans le cas particulier de recherche d'une partition en k classes connexes d'objets d'un ensemble dans lequel il existe un ordre à respecter. Cela signifie qu'il est possible de chercher une partition en k classes de l'ensemble des discours du corpus telle que chacune des classes ne soit composée que d'éléments connexes dans le temps tout en étant assuré que cette partition est la meilleure. En effet, cette possibilité est la conséquence de la réduction très importante du nombre de partitions possibles. Sans la contrainte de contigüité des objets dans chaque classe, nous savons que le nombre de partitions possibles de N objets en K classes, nombre de Stirling, a une croissance approximative de l'ordre de KN; sous cette contrainte, le nombre de partitions en K classes devient égal à Pour que l'algorithme puisse être appliqué, il faut que l'indice d'homogénéité W d'une partition P soit la somme des indices d'homogénéité des classes de cette partition P. Autrement dit, une bonne partition est une partition où la somme des "disparités" à l'intérieur de chaque classe de déclarations est minimale. Définissons notre critère des "mal classés" de la manière suivante: pour une classe donnée, la présence majoritaire de "+" correspond à un patron idéal de classe composé uniquement de "+"; réciproquement, une présence majoritaire de "-" correspond à un patron idéal de classe composé exclusivement de "-". Le nombre de "mal classés" est la somme des discordances entre le patron idéal de la classe et sa composition actuelle. Dans le cas d'une classe composée d'un nombre pair d'éléments et où il y aurait égalité du nombre de "+" et de "-", le choix du patron idéal est indifférent, le nombre de discordances étant évidemment égal à la moitié du nombre des éléments de cette classe. Ce critère varie donc de 0 correspondant à une classe identique à son idéal, c'est-à-dire à une classe strictement homogène, jusqu'à 0,5 multiplié par le cardinal de la classe (si ce cardinal est pair) ou à 0,5 multiplié par le cardinal de la classe moins 1 (pour une classe composée d'un nombre impair d'éléments). Une classe composée d'un seul élément est toujours homogène, le critère valant dans ce cas toujours 0. Si nous nous intéressons aux n1 premiers objets de l'ensemble à classer, leur partition en k1 classes est nécessairement composée d'une partition optimale de n2 objets (n2<n1) en k1-1 classes et d'une classe supplémentaire composée des n1-n2 objets restants. Si l'on connait toutes les partitions optimales en k1-1 classes de n2 objets, n2 variant de k1 à n1 et la valeur du critère pour les séquences supplémentaires, il suffit de choisir comme partition optimale en k1 classes de n1 objets celles qui minimisent la somme du critère pour la partition en k1-1 classes de n2 objets et du critère de la séquence formée par les objets de n2 à n1. Cette relation de récurrence permet de calculer de proche en proche la meilleure partition pour l'ensemble des objets en 2, 3,… k classes puisque nous pouvons aisément calculer la partition optimale en 2 classes de deux objets, les partitions en 2 classes de 3 objets et ainsi de suite arriver à classer l'ensemble des objets.
Découpage optimal de la séquence des sur- et sous-emplois: résultats Nous effectuerons tout d'abord la recherche des partitions optimales des successions d'excédents et de déficits d'emploi du vocabulaire de la classe 2 (de la partition en six classes des formes lexicales) parmi les discours gouvernementaux pour appliquer ensuite la procédure à l'ensemble des six classes de vocabulaire. Partition optimale des déclarations en fonction de l'emploi du vocabulaire de la classe 2 (partition en six classes lexicales)
On y trouve l'ensemble des partitions optimales en 2, 3, …, 11 classes, les partitions en plus de onze classes n'apportant plus de gain en matière d'homogénéité des classes sont abandonnées. Le critère d'homogénéité décroit de dix à zéro lorsque s'accroit le nombre de classes. La différence entre les critères de deux partitions dont les nombres de classes diffèrent de 1 nous indique le gain d'homogénéité que procure la possibilité de disposer d'une classe supplémentaire pour répartir les objets (les déclarations gouvernementales). À priori, la partition en onze classes est idéale; il s'agit évidemment d'une solution triviale. Peut-on retenir une partition en deux ou trois classes comme un bon modèle? La partition en deux zones fournit 10 éléments mal classés. Or, sur 38 éléments, le maximum possible d'éléments mal classés est de 19. La création d'une classe supplémentaire permet cependant de faire un gain appréciable en passant de dix à cinq mal classés, soit un gain absolu de cinq mal classés ou un gain relatif de (10-5)/10 soit 50%. La distribution des gains relatifs nous incite à retenir la partition en trois zones comme un bon modèle pour la répartition des excès et des déficits des déclarations gouvernementales du vocabulaire de la classe 2 confirmant le diagnostic de chronologicité précédent. Le Tableau 3 reprend les mêmes éléments que le Tableau 2 mais pour toutes les classes de la partition en six classes de vocabulaire.
Tableau 3 Partition optimale des déclarations en fonction de l'emploi du vocabulaire des six classes d'une partition du vocabulaire
Découpage optimal de la séquence des sur- et sous-emplois: interprétation Conclure à la "chronologicité" d'une classe de vocabulaire à partir du Tableau 3 n'est pas chose aisée, du moins sans construction de règles. Plusieurs questions méritent d'être posées. La première est sans conteste la question de la classifiabilité des patrons de "+" et de "-" associés à chacune des classes de vocabulaire. Y a-t-il vraiment une structure dans ces séries? Un test classique de statistique non-paramétrique nous permettra de dire si la suite de "+" et "-" étudiée peut ou non être considérée raisonnablement comme non-aléatoire. Nous testons l'hypothèse que le nombre de séquences observé est inférieur à celui que l'on devrait attendre. Le Tableau 4 nous indique les probabilités d'observer sous l'hypothèse d'une répartition aléatoire des "+" et des "-" ce nombre de séquences. L'hypothèse que les séquences associées aux classes lexicales 1 et 6 ne sont pas significativement trop peu nombreuses ne peut pas être rejetée; par contre, si l'on se donne un niveau de signification de 5%, cette hypothèse doit être rejetée pour les séquences associées aux quatre autres classes. Celles-ci contiennent donc probablement un ordre parmi les "+" et les "-". Un diagnostic d'existence d'une structure des sur- et des sous-emplois de vocabulaire peut donc être tiré de ce test, condition nécessaire au diagnostic de chronologicité mais condition non suffisante.
Cette utilisation d'un test de séquence, pour logique qu'elle apparaisse dans ce contexte d'analyse du signe des écarts d'emploi du vocabulaire, n'aboutit pourtant qu'à poser un diagnostic qui ne prend pas en compte tous les éléments que fournit la méthode de classification optimale utilisée. En effet, nous disposons, pour chacune des classes de la partition en six des écarts, de son "profil" par rapport aux meilleurs patrons idéaux composés de 1, 2, 3… r séquences homogènes. Pour juger de la qualité de ces écarts, nous devrions en connaitre la distribution, ce qui permettrait de savoir si les séquences de "+" et de "-" qu'il est possible de répartir en trois zones homogènes et contigües en n'ayant que trois éléments mal classés sont très nombreuses ou rares, soit parmi l'ensemble des séquences composées de trente-huit éléments soit parmi l'ensemble des séquences composées de trente-huit éléments et comportant treize "+". Nous ne connaissons pas ces distributions. Pour pouvoir néanmoins juger de la qualité des écarts, nous avons calculé par simulation six tables de la manière suivante: 1 - Nous avons engendré un échantillon de 100 000 séquences et cinq échantillons de 10 000 séquences de trente-huit éléments chacun par tirage aléatoire avec remplacement. Le premier de ces échantillons est composé de séquences dont l'écart initial à une séquence homogène unique n'est pas fixé. Les cinq autres échantillons sont respectivement composés de séquences comportant 17, 15, 13, 11 et 8 "+", ce qui correspond aux écarts initiaux des six classes lexicales étudiées. 2 - Pour chacune des séquences de ces six échantillons, nous avons établi les différentes partitions optimales en 1, 2, 3,…38 classes et nous avons calculé à chaque fois les écarts. 3 - Enfin, nous avons dressé six tables qui reprennent les répartitions des séquences des six échantillons selon la taille de la partition optimale et la valeur de l'écart à cette partition optimale. Nous pouvons maintenant établir quelle est la proportion de séquences qui peuvent se diviser en deux zones homogènes en ayant seulement 6 mal classés. Pour émettre un jugement sur les valeurs trouvées dans le corpus divisé en six classes lexicales, nous avons calculé la fréquence cumulée des différentes valeurs de mal classés pour chaque taille de partition optimale. Il y a 31 séquences qui se partitionnent en deux avec six mal classées et 40 séquences qui se partitionnent en deux zones homogènes avec 6 ou moins d'éléments mal classés (31 + 5 + 4), ce qui conduit à une proportion de 40/100 000. Nous pouvons calculer cette proportion pour les valeurs observées dans la classification en six ensembles du vocabulaire, nous l'appellerons P1. Nous pouvons calculer de la même façon une proportion P2, en nous servant, cette fois, non du tableau général engendré par l'échantillon des 100 000 mais des tableaux construits sur l'échantillon de séquences de même nombre de mal classés par rapport à un patron homogène. La comparaison de deux partitions optimales pour une même séquence peut désormais se faire facilement: on désignera comme la meilleure partition celle pour laquelle P1 ou P2 atteint son minimum, puisqu'ainsi sera mise en évidence la partition dont la "probabilité" d'apparition était la plus faible.
Y a-t-il des classes "chronologiques"? Les indices P1 et P2 sont strictement concordants, en ce qui concerne la pose du diagnostic: leurs minimums coïncident parfaitement dans cet exemple. Nous pouvons aller au-delà du diagnostic du test des séquences pour les classes lexicales 1 et 6. En effet, en ce qui concerne la classe 1, nous voyons que la performance de la recherche de partitions optimales n'est pas extraordinaire; la partition en deux zones semble la meilleure. Ces deux classes ne déclenchent pas de diagnostic de "chronologicité". Par contre, la classe 2 en offre un bel exemple: elle se divise en trois zones, avec seulement 5 mal classés; seules quelques séquences de nos échantillons ont pu faire la même chose ou mieux (de l'ordre d'une sur dix mille — P1 — ou une sur onze mille — P2). Trois séquences homogènes, c'était la condition pour pouvoir qualifier une séquence de chronologique. La classe 3 est plus étonnante: la division en deux zones fournit une division quasi parfaite de la séquence (2 mal classés); dans nos échantillons aucune séquence n'a fait aussi bien ! L'aspect chronologique réside dans le déficit d'emploi du vocabulaire de cette classe durant la première partie du corpus, suivi d'un suremploi quasi permanent dans la deuxième partie. Au même type que la classe 2 appartient la classe 4 mais avec encore plus de netteté, les indices P1 et P2 étant très faibles pour la division optimale en trois zones. Enfin, la classe 5 se situe clairement dans le type de la classe 3: division en deux zones homogènes mais avec suremploi dans la première partie du corpus et sous-emploi localisé dans la fin.
Tableau 6 Diagnostic de "chronologicité"
Étude "chronologique" de la partition du vocabulaire en six classes Organisée autour des formes et, de, la, à, l, les, dans, le, des, d, en, au, un, Gouvernement, une, du, s, par, sur, son, avec, pour, politique, cette, plus, économique, ce, aux, pays, ces, la première classe se trouve ne pas montrer de caractère chronologique; la liste des formes ci-dessus constituée par les parangons de la classe, indique pourquoi. En effet, outre les morphèmes grammaticaux qui sont utilisés par tout texte écrit en français (de, le, à, un…), on retrouve un vocabulaire que nous pourrions considérer comme la marque générale du discours politique gouvernemental (Gouvernement, politique, État, Belgique, Parlement, mesures, économique…). Cette classe est celle qui contient le plus de formes (371) et qui couvre la plus grande surface du corpus en terme d'occurrences (64,51% des formes de fréquence supérieure à 9). Elle fournit la toile de fond lexicale sur laquelle vont pouvoir se déployer les discours particuliers de chaque gouvernement. Toutes les déclarations gouvernementales ne recourent pas dans les mêmes proportions à ce vocabulaire. De manière assez étonnante, en ordonnant les déclarations gouvernementales suivant leur recours plus ou moins grand au vocabulaire banal des déclarations gouvernementales, apparait un ordonnancement droite/gauche. En effet, tous les gouvernements à direction socialiste (à l'exception du premier gouvernement Leburton de 1973) font un emploi déficitaire du vocabulaire banal. Le vocabulaire de cette classe n'est pas composé uniquement de "mots-outils" communs à la plupart des usagers de la langue mais aussi de nombreux mots appartenant à la sphère de la politique gouvernementale, les deux sous-ensembles fournissant le ciment de toute déclaration gouvernementale en Belgique dans la période considérée. Le caractère chronologique de la deuxième classe se marque par un excès d'emploi des formes de cette classe dans une période qui court de la déclaration de Pierre Harmel (dg 17, 1965) à celle de Léo Tindemans (dg 23, 1974). Cette période se caractérise par l'utilisation d'un vocabulaire de réorganisation de l'État, sans qu'il soit encore vraiment question du démembrement de l'État mais plutôt d'un début d'autonomie culturelle et linguistique (autonomie, conseils, cultures, langue…), de la création d'organes régionaux (agglomération). Le vocabulaire de cette classe est encore utilisé en dehors de cette période, mais surtout dans des textes qui reviennent sur la réorganisation de la Belgique et particulièrement dans la déclaration de Léo Tindemans en 1974, quand, pour la première fois, sont associés à l'équipe ministérielle des ministres membres de partis "communautaires" ou dans la déclaration de Wilfried Martens de 1980 quasi entièrement consacrée à l'exposé d'une réforme transitoire de l'État. Le processus de réforme de la Belgique trouve ainsi à s'exprimer à travers un vocabulaire spécifique propre, qui émerge vers 1964, est employé de manière dense et constante de 1964 à 1974, puis revient sporadiquement à chaque nouvelle crise institutionnelle. Parangons de la classe 2 classés par distance croissante du centre de la classe: accord, conseil, Constitution, tenu, conseils, souci, culturel, article, élaborer, réalisations, matières, pris, autonomie, juillet, doute, perspective, mener, dernier, régionaux, parlementaire, ministres, concernant, culturels, conformément, culturelle, permet, agglomération, arrêté, partenaires. La classe 3 représente un type chronologique différent. En effet, l'utilisation des mots de cette classe découpe le corpus en deux zones, une période de sous-utilisation entre 1944 et 1973, une période d'utilisation en excès à partir de cette dernière année. Vocabulaire de la crise, de la crise de l'énergie, de la crise de l'emploi, de la crise budgétaire, les formes de cette classe montrent aussi la montée en puissance des problématiques de sécurité: sécurité publique et sécurité sociale. Le modèle de société basé sur la croissance et ce qu'il est convenu d'appeler le compromis "fordiste", c'est-à-dire un système de régulation sociale qui permet la redistribution d'une partie de la richesse sous forme de la Sécurité sociale et qui s'était développé grosso modo entre 1944 et 1972, se trouvent remis en cause au nom de la recherche de solutions au problème du chômage. On voit l'emploi devenir un thème important mais couplé à celui de la recherche d'accomplissement d'objectifs budgétaires et d'équilibre de la Sécurité sociale. À ces problématiques centrales de l'après 1974, sont associés des ensembles de préoccupations qui sont dérivées directement de la "crise" énergétique comme la prise en compte de l'environnement, ou bien sont simplement le développement de politiques longuement préparées comme l'intégration européenne, qui finit par fournir en fin de période un cadre aux préoccupations de libéralisation et d'affaiblissement de l'intervention publique dans le domaine social et économique. Le tout constitue le vocabulaire commun de la déclaration gouvernementale de l'après-crise pétrolière. Parangons de la classe 3: sociale, emploi, cadre, fiscale, grande, population, nouveau, coopération, également, confiance, base, niveau, européenne, entreprises, budgétaire, objectif, important, outre, publiques, Sécurité, réforme, promotion, manière, meilleure, solidarité, rôle, chacun, nombre, sécurité, décisions. La classe 4 est d'un type de classe "chronologique" particulier: le type négatif. La période mise en évidence (de 1954 à 1961) est caractérisée par un déficit d'utilisation des mots de cette classe. Il s'agit donc d'un vocabulaire qui, en usage au début de la période couverte par le corpus, subit une éclipse puis revient en excès dans les déclarations d'après 1965. On remarquera la dominance du lexique économique, planificateur (programme) et social. La période où se marque un déficit de ces formes est assez dominée par le parti libéral, qui est présent dans trois cabinets sur cinq ! Ici aussi, on constatera le retard du discours sur le travail politique: la coalition "travailliste" Lefèvre-Spaak de 1961, mise en place après la grande grève de l'hiver 1960-1961, quoiqu'elle ouvre une nouvelle période politique, celle de la gestion de la croissance, conforme son discours à ceux des gouvernements précédents, y compris dans ses déficits (travailleurs, social). Parangons de la classe 4: secteur, part, national, programme, objectifs, autre, action, travailleurs, efficacité, scientifique, secteurs, investissements, augmentation, social, indépendants, budget, structure, impose, responsabilités, marché, hommes, assurance, dépenses, ans, agricole, étroite, ressources, pension, méthodes, organismes. Vocabulaire de remise en route d'une société et d'un État profondément perturbés par le traumatisme de la guerre, l'ensemble des formes de la cinquième classe renvoie au processus de normalisation de la situation institutionnelle, de reprise de la production et de mise en place d'une organisation sociale. Elles ont donc été utilisées préférentiellement durant la période de reconstruction de l'immédiat après-guerre et plus encore dans la période de stabilisation des institutions qui la suivit. Le statut de l'enseignement (enseignement, technique) qui, avec la question royale, sera l'un des problèmes les plus aigus de la vie politique de cette période, se retrouve tout aussi naturellement inclus dans cette classe de vocabulaire. Parangons de la classe 5: nationale, toute, équilibre, situation, œuvre, conditions, intérêt, prises, organisation, fonctionnement, moyennes, poursuivra, services, technique, nécessaires, cours, loi, statut, enseignement, agriculture, étude, production, point, Chambres, améliorer, législation, fonds, financier, veillera, générale. Enfin, il reste une sixième classe de vocabulaire qui n'a pas déclenché de diagnostic de "chronologicité" dans le système de détection. La lecture du tableau des parangons de cette classe tendrait à conforter ce diagnostic: on y trouve, pour l'essentiel, des mots dont on attend l'utilisation dans tout discours (que, il, est…). Cependant, la distribution de ces formes incite à nuancer ce diagnostic. À l'exception des dg 4 et dg 5, nous avons un excédent d'emploi bien marqué durant les années 1944 à 1949 (près de 30% de la surface des textes sont des occurrences de formes de cette classe); on ne retrouve plus ensuite une telle concentration, même si des "pics" se présentent encore. Nous rencontrons là une limite de notre méthode de diagnostic. Celle-ci est peut-être trop rude, à ne retenir comme information pertinente que le signe de l'écart à la moyenne et à ne pas prendre en compte la valeur de cet écart. Limite et non contre-indication car, si l'on sent bien qu'il y a dans cette classe de vocabulaire quelque chose de "chronologique", on perçoit encore que cela ne suffit pas à rendre compte du pourquoi de la constitution de cette classe intermédiaire entre les "chronologiques" vraies, où les excédents et les déficits sont clairement le fait de périodes déterminées, et la classe 1, qui regroupe le vocabulaire bien réparti dans le corpus. Nous sommes face à un ensemble de formes qui combine deux types d'utilisation: un emploi commun à tout le corpus, certains des mots de cette liste étant difficilement évitables dans un texte politique, et un sur-emploi dans certains discours, particulièrement au début du corpus. Le mélange des deux types d'emploi brouille le caractère chronologique que pourrait avoir le deuxième type d'emploi. Il s'agit d'un cas limite. Parangons de la classe 6: que, il, est, qui, qu, n, se, pas, ne, y, sans, même, être, mais, ont, problèmes, tout, a, effort, elle, toutes, présente, faire, fois, fait, si, elles, c, aujourdhui, peut.
Périodisation? En somme, le découpage chronologique du corpus fait sens, mais il ne débouche pas vraiment sur une périodisation simple. C'est le glissement régulier vers de nouveaux vocabulaires, associés à de nouveaux problèmes politiques, qui engendre l'image chronologique vue sur le plan factoriel, et non une stricte périodisation. Les périodes que l'on peut définir à partir du renouvellement du vocabulaire se chevauchent et reflètent la multiplicité des sources du changement politique. Du point de vue des gouvernants, la politique internationale, l'économie, les tensions sous-nationalistes, etc., chaque domaine apporte son propre renouvellement lexical à un rythme qui lui est propre. Certes la tâche d'un gouvernement consiste à unifier ces discours (et les actions qui en découlent) en un ensemble politique cohérent, et c'est, en théorie, à cela que devrait servir l'idéologie partisane. Mais si l'on se veut le "président de tous les Français" ou plus simplement le Gouvernement de quatre, cinq ou six partis belges à programmes divergents, cette tâche devient difficile. Le discours des gouvernants se présente alors comme consensus et non comme rupture franche avec les prédécesseurs, du moins dans les corpus de discours de régimes démocratiques. Les contraintes de l'action gouvernementale, l'inertie de l'administration d'un État contribuent pour leur part au lissage de l'évolution. On le voit, la composante chronologique est la résultante de forces multiples. Donc, le temps - on devrait dire plus proprement les diverses temporalités politiques - structure de manière serrée le discours gouvernemental, mais il le fait en conservant un certain flou, sous lequel transparaissent les préoccupations les plus politiques, flou qui nous autorise à trouver des ressemblances entre les discours contemporains de la fatalité marchande et ceux tenus par les gouvernements catholiques des premières années de la guerre froide. Par leur production à l'avant-scène politique de préoccupations budgétaires qui imposent une discipline à l'ensemble de la population mais surtout à ceux qui pouvaient bénéficier de la Sécurité sociale, les discours de ces deux périodes ont en commun une certaine tonalité conservatrice qui perturbe le simple déroulement de la ressemblance chronologique. De même, il importe de remarquer la similitude de tonalité entre les discours volontaristes du redémarrage de l'immédiat après-guerre et ceux du redémarrage économique et surtout sociopolitique des années 1960 et 1975 [Deroubaix 1997, Deroubaix-Gobin 1989]. La cité est l'œuvre de l'imaginaire social des hommes. Il serait vain de penser que cette production de la société, et des discours qui en sont inséparables, puisse un jour être résumée par l'étude d'une courbe, d'une série chronologique, serait-ce même celle du vocabulaire de ceux que l'on désigne erronément par "nos" gouvernants. Tableau 7. Ordre selon l'axe1 et ordre "naturel" chronologique .
Figure 1. Plan 1 &2 représentation des déclarations et "cubique" approchée
Figure 2. Plan 1 &3 représentation des déclarations et parabole approchée
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||