
UNE NORME ENDOGÈNE
POUR LE CALCUL STYLISTIQUE DU VOCABULAIRE
Jean-Marie Viprey
Groupe de Recherche en Linguistique, Informatique, Sémiotique (GRELIS)
Université de Franche-Comté
30 Rue Mégevand, 25030 Besançon, France
Summary
What is a vocable ? For classical stylometry, it remains a mass of occurrences to be compared to an exogenous norm. But if we consider textuality as a network of thin mutual relations between recurrent units, a vocable is rather a field, a discontinuous cotext, which rules its own endogenous norm for the distribution of its cooccurrents. Vocabulary (for instance the one of Les Fleurs du mal) can be seized as a dynamic whole, by the means of Correspondance Factorial Analysis, and projected in two dimensions as a continuum of associative zones. Such lexical maps draw elaborate interpretative tracks, which are cleared of projective apriorisms.
1. Problématique de la norme endogène
La statistique lexicale (Guiraud, 1954) a eu tendance à se développer comme branche auxiliaire d’une stylistique de norme exogène, qui déterminait le style comme ensemble d’écarts de fréquence par rapport à un corpus externe de référence. La liste des mots-clés, formes surreprésentées, résultat essentiel de cette méthodologie, ne donne accès qu'à des spécificités massives, et non à la textualité proprement dite.
Muller (1973 et 1977) et surtout Brunet (1985) modifient déjà la perspective en prenant comme arrière-plan de chaque pièce de Corneille, de chaque roman de Zola l'ensemble respectivement de l'œuvre dramatique de Corneille, et des Rougon-Macquard. La partie et le tout sont pertinemment comparables et la dynamique propre de l'œuvre n'est plus écartée.
Cependant la constitution la plus fine du texte reste hors de portée d'une approche par comparaisons de masses. Comme tout autre niveau d'analyse, le vocabulaire est d'abord un réseau de relations spatiales où se combinent micro- et macrostructures. Un vocable est une série d'occurrences distribuée dans le tissu des autres séries ; il est donc caractérisable par ses collocations (Peytard, 1970), autrement dit son cotexte discontinu (Massonie, 1986). Et le vocabulaire, comme l'engrenage complexe de ces cotextes. Si elle est possible sous cet angle, la quantification se fera au plus près de la qualification en valeur, elle sera en relation étroite avec la construction d'une signifiance. Le modèle sémiotique ne s'appuiera plus sur un échafaudage d'a priori projectifs et rigides, comme c'est le cas chez Greimas (1970/1986), mais il épousera la plasticité et la complexité des engagements naturels des vocables.
La dynamique du vocabulaire sera donc recherchée à travers des relations distributionnelles d'affinité (surreprésentation d'un vocable dans le cotexte d'un autre vocable du même ensemble) : ce n'est plus une fréquence de corpus qui servira de norme, mais la fréquence du vocable cooccurrent dans les limites du texte. Rendre compte du vocabulaire, ce sera donc analyser la cooccurrence généralisée au moyen de méthodes statistiques jaugeant la correspondance.
On attend ici de l'Analyse Factorielle des Correspondances (A.F.C.) une saisie globale de ces relations de cooccurrence généralisée (Q-occurrence pour Massonie, 1986), par projection du vocabulaire en zones de profils associatifs voisins. Les matrices analysées sont typologiquement carrées (vocables en lignes et en colonnes), contrairement à celles, rectangulaires, de l'Analyse de Discours (vocables en lignes, instances de discours en colonnes).
2. Expérience du vocabulaire des Fleurs du mal
Nous avons choisi comme terrain d'expérience le texte, éminemment balisé, des Fleurs du mal de Baudelaire. Lemmatisé selon la norme lexicologique en vigueur, le texte est soumis à l'indexation suivante : chaque mot successif est considéré comme occurrence, à l'exclusion des hapax et des catégories non-lexicales; dans les limites d'un empan donné, on relève tous ses cooccurrents, et un index de position (n° de poème et n° de vers) qui servira pour le retour au texte. On obtient ainsi un tableau à quatre colonnes qui peut être adressé linéairement, ou trié alphabétiquement.
L'index génère ensuite une matrice carrée de cooccurrence ; en pratique, notamment pour des raisons logicielles, nous n'avons retenu dans l'expérience que les 181 vocables les plus fréquents (effectif-seuil : 13 occ.) et, pour éliminer les effets de marge dûs à cette sélection, nous avons substitué à la cooccurrence brute l'écart-réduit à sa norme endogène.
Nous ne présenterons ici en graphe que l'A.F.C. d'une matrice dont les données sont la synthèse des résultats obtenus dans les empans 2, 4, 8 et 16.
On a laissé "en blanc" les points les plus proches des origines, dont la distribution n'est pas interprétable.
Les valeurs d'inertie constatées sur les trois premiers axes semblent significatives, rapportées aux valeurs théoriques très basses compte tenu de la présence de 181 axes.

3. Isotropies et exploration thématique
Surtout, le graphe présente une lisibilité satisfaisante. On y distingue nettement des zones de vocabulaire qui ont un double caractère statistique : (1) les unités qui les constituent ont nécessairement des profils associatifs voisins, (2) leurs groupements forment autant de saillies dans la distribution généralisée des vocables. On peut donc affirmer que cette projection renvoie à des traits saillants de la macrostructuration des microstructures, ce qui nous semble être une assez productive définition du style comme réalité endogène.
Ces zones présentent, de plus, l'avantage d'être sans rupture de continuité (surtout si l'on fait un peu abstraction du tracé positif des axes) ; l'interprétation en sera là aussi plus proche de la plasticité textuelle que, par exemple, ce n'est le cas pour les classes hiérarchiques produites par Alceste, la procédure la plus proche de la nôtre à ce jour.
Nous nommerons les relations de proximité observés sur la carte isotropie, par référence critique au concept d'isotopie dans la sémiotique de Greimas. L'isotropie (trepein) est une relation d'orientation mutuelle dans la configuration textuelle, seul fait objectivable par des procédures explicites et non projectives. La sélection d'éventuels pivots n'intervient dès lors que sur l'indication des lignes de force de l'analyse explicite.
Nous pouvons donc envisager une exploration thématique qui ne soit pas amorcée par des a priori atemporels, comme c'est souvent le cas dans la tradition critique. Les vocables thématiques d'une part s'imposent d'eux-mêmes (on peut d'ailleurs constater, sur ce texte volontairement choisi pour sa haute fréquentation, maint élément de confirmation croisée de notre méthode et des intuitions des grands lecteurs), et d'autre part ne se présentent pas isolément, mais déjà en groupements thématiques endogènes. Un thème n'est plus alors une liste toujours déjà prête à l'emploi, mais un donné construit du texte particulier.
L'exploration thématique exige le dialogue des cartes, des index et du texte linéaire. Autour du vocable mer, par exemple, nous allons chercher les cotextes de cooccurrence de ses isotropiques dans la zone "est". On peut ainsi repérer une distribution du thème dans les poèmes du recueil, certainement plus pertinente que la distribution d'un vocable isolé, et par ailleurs la seule qui justifie et récompense la complexité des procédures statistiques.
Si l'on fige provisoirement quatre zones isotropiques polaires, aux quatre "points cardinaux" de la carte des vocables, on peut même, par analyse des distributions, agencer une carte des poèmes en tant que cotextes cooccurrentiels (donc, thématiques de ce point de vue). Les poèmes impliqués sélectivement dans une isotropie (avec un écart-réduit >2) figurent au pôle de cette isotropie ; ceux dont l’écart-réduit >5 sont dans un cartouche. Ceux qui sont impliqués dans deux isotropies figurent au pôle intermédiaire (ex : nord-est), et les poèmes tri-isotropiques sont mis en exergue au centre du schéma.
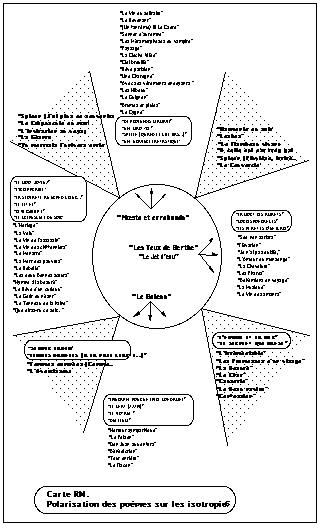
On affinera donc chaque thème par le parcours des cotextes, guidé dans leur réseau inextricable par une surveillance constante des macro-aperçus offerts par les cartes.
Ainsi, la thématisation ne s’appuie pas plus sur la simple récurrence de vocables, comme le suggèrent la statistique lexicale classique et, subtile convergence, l’analyse thématique dominante, qu’elle ne se développe sur des occurrences autonomes, voire étanches, comme l’impliquent parfois les formulations de Riffaterre (1971), souvent reprises comme argument contre toute saisie d’ensemble, notamment statistique
Les Fleurs du mal sont un texte particulièrement propice au déploiement d'un mode de parcours où il n’est guère de vers, de syntagme qui ne soit l’amorce évidente d’un glissement vers un contexte semblable et nécessairement altéré. Alors que le vocabulaire du recueil ne manifeste pas en tant que tel une tendance particulière à la répétition (Guiraud, 1954 : 41 à 53), l’organisation textuelle de ce vocabulaire est une réticulation si dense qu’on pourrait la dire obsédante. Mais l’intérêt de notre approche est peut-être de confirmer cette impression (qui ne peut de toute façon naître que d’une lecture assidue), et surtout d’en condenser le substrat textuel : l’extraction statistique des isotropies, c’est-à-dire de configurations thématisantes (donc récurrentes dans leur variation même), permet de "tomber" plus sûrement sur des nœuds pertinents, que l’on aurait peut-être négligés parfois, et qui plus sûrement auraient risqué d’être noyés dans le faisceau de nos propres projections.
4. Le filtrage de la cooccurrence par le mètre
Nous pouvons aussi, dans le cadre ainsi posé, calculer précisément dans quelle mesure le critère d’appartenance au même vers filtre la cooccurrence : il suffira de diviser la cooccurrence dans les limites du vers par celle à empan 6 ; le vers comportant en moyenne 6 mots, le quotient théorique sera évidemment 0,5 ; on pourra ainsi obtenir une matrice de quotients que l’on étudiera sous l’angle booléen : nous parlerons essentiellement de quotients>0,5, (Q>0,5), dont l’observation sera,
•pour chaque couple de vocables,
•pour chaque vocable en ligne ou en colonne,
•dans la matrice totale ou
•dans un secteur considéré du vocabulaire,
•déterminé à partir de la lecture de la carte ou
•de la matrice,
•pour une zone entière de la matrice
le critère et l’unité de compte (cellule chargée ou non) de la contribution spécifique et supplémentaire de la structure métrique à la structuration lexico-sémantique.
On compare alors la densité en Q>0,5 des matrices partielles constituées par les zones isotropiques (par exemple, les 20 points les plus proches de mer), à la norme de la matrice totale. Les écarts-réduits sont constamment >1,5, et ils atteignent des valeurs >3 pour les groupements extrêmes du premier axe. Avec les 100 vocables les plus au centre, l'écart-réduit négatif est considérable : -2,67.
Ces résultats nous indiquent sans équivoque que l'isotropie (endogène) est bien un fait engagé dans la condensation textuelle, ici proprement poétique. L'empan fixe est un standard, mais le véritable espace relationnel est celui où s'investissent les niveaux constituants du plus élémentaire au plus étendu. Les résultats sont analogues si l'on compare la strophe à son étalon dans les empans fixes.
5. Autres témoins de la densité textuelle
En outre, rien n'interdit, tout suggère de croiser aux données de vocabulaire, l'observation d'autres unités de structuration textuelle. Nous en avons exploré à ce jour deux sortes principales : (1) les marques de temps et de personne (2) les allitérations.
Nous présenterons ici la distribution sur la carte des vocables dans le cotexte desquels nous et le futur de l'indicatif sont surreprésentés (écart-réduit >2).
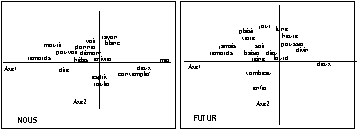
L'orientation est nette vers la zone dominée par le vocable loin, et la corrélation est très forte entre les deux propriétés. Voilà de quoi enrichir la thématique à base strictement lexicale, d'autant que par ailleurs ne et la seconde personne polarisent électivement la moitié "ouest", et je le quart sud-ouest. On a calculé le c2 de cette répartition sur les 4 secteurs des cooccurrents privilégiés de ces diverses marques ; les probabilités d'une répartition aléatoire sont dans l'ensemble faibles :

La contre-épreuve effectuée avec les unités les plus neutres (et, de, que) est positive :
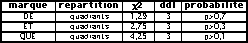
Quant aux allitérations, on constate qu'elles engagent de façon privilégiée les vocables les plus émergents sur le plan déjà exploré des profils associatifs : une corrélation positive est vérifiée entre les deux traits, ce qui confirme solidairement notre hypothèse de travail et la théorie du texte poétique comme lieu de condensation particulière. En revanche, on ne constate aucune distribution particulière des allitérations dans le vocabulaire cartographié, aucune affinité avec l'une des zones isotropiques. Cela n'a rien pour nous étonner, au contraire : on y verrait plutôt une infirmation supplémentaire de toute théorie tendant à conférer au phonème une valeur intrinsèque, expressive ou imitative ; l'allitération est un fait textuel, sa portée s'étend de place en place, mais elle demeure en tout lieu subordonnée à l'activité du vocable.
6. Conclusion
La norme endogène permet donc d'envisager une stylométrie où chaque unité de chaque niveau peut être observée dans la dynamique de sa récurrence, non pas comme masse indifférenciée, mais au contraire comme nœud relationnel discontinu, ramification élémentaire de la textualité.
Nous y voyons le terrain d'une renaissance des contributions mutuelles des sciences du langage et de la critique littéraire, qui a pu reprocher à bon droit à la statistique lexicale d'écraser la réticulation de l'œuvre d'art verbal sous la massivité de ses données.
Références
Brunet, É. (1985). Le Vocabulaire de Zola. Genève-Paris : Slatkine-Champion.
Greimas, A.-J. ([1970] 1986). Sémantique structurale. Paris : Larousse.
Guiraud, P. (1954). Les Caractères statistiques du vocabulaire. Paris : P.U.F..
Massonie, J.-P. (1986). " Q-occurrences libres ", in Brunet, Méthodes quantitatives et informatiques dans l’étude des textes. 611-623 Genève-Paris : Slatkine-Champion.
Muller, C. ([1973] 1992A). Principes et méthodes de statistique lexicale. Paris : Champion.
Muller, C. ([1977] 1992B). Initiation aux méthodes de la statistique linguistique. Paris : Champion.
Peytard, J., Genouvrier, É. (1970). Linguistique et enseignement du français. Paris : Larousse.
Ramos, J.-M., Reinert, M. (1995). " Les mondes lexicaux d’Arthur Rimbaud ", in Analisi Statistica dei dati testuali (J.A.D.T. 3, Rome). Vol 2 : 289-296. Rome : CISU.
Riffaterre, M. (1971). Essais de stylistique structurale. Paris : Flammarion.
Viprey, J.-M. (1997). Dynamique du vocabulaire des Fleurs du mal. Genève-Paris : Slatkine-Champion.