L'ANALYSE DES DONNÉES TEXTUELLES DANS
LA CARACTÉRISATION DU PERSONNAGE ROMANESQUE
Ana Maria Vilhena
Ministério da Educação - Lisboa
Av. Independ.Colónias, 17-1°E, 2900 Setúbal, Portugal
Abstract
The list of "repeated segments", achieved by running Alceste on three literary writings of a Portuguese author, shows out a high frequence of a "negative form+verb" pattern. A statistical analysis of the distribution of these patterns in the lemmatized corpus, namely with Hyperbase and Tree model, reveals a particular negative perception of the world, wich is typical of characters in the three writings as well as of the author himself.
1. Le corpus
Bien que peu traduite en France, l'œuvre poétique et de fiction de Manuel Alegre jouit d'une grande notoriété et d'une vraie reconnaissance au Portugal depuis 1965. Le profond engagement de cet écrivain contemporain contre toute forme d'oppression s'exprime notamment par un emploi extrêmement fréquent de formes négatives. Cet emploi s'avère être beaucoup plus important dans ses textes de poésie que dans la prose, ainsi que j'ai démontré dans une analyse statistique que j'ai effectuée sur le corpus constitué par les textes littéraires qu'il a publiés entre 1960 et 1993 . Ce corpus ne comprenait alors que deux ouvrages en prose — un roman et un recueil de contes — tous deux parus en 1989.
Depuis, l'écrivain a publié, fin 1995, un troisième ouvrage de fiction : un roman inspiré de son enfance. Le but de ce travail est de comparer ce dernier aux deux textes en prose précédents afin d'observer l'usage que l'auteur fait, dans ce seul genre, des formes négatives qu'il employait de façon assez remarquable en poésie. Compte tenu de l'étendue assez différente des trois ouvrages, j'ai pris la décision de diviser chacun des romans en deux, de façon à obtenir une partition plus équilibrée. Le nouveau corpus sur lequel porte maintenant mon observation a été lemmatisé. Il est donc constitué de cinq parties : les deux premières, Jorn1 et Jorn2 (ou J1 et J2), regroupent les trente-cinq chapitres du roman de guerre Jornada de África ; la troisième, PAzul (ou PAz), comprend les dix contes qui composent le recueil O Homem do País Azul ; les deux dernières, Alma1 et Alma2 (ou A1 et A2), correspondent aux vingt-trois chapitres du dernier roman de Manuel Alegre, Alma.
|
|
Jorn1 |
Jorn2 |
PAzul |
Alma1 |
Alma2 |
Total |
|
Occurr. |
21 740 |
26 536 |
20 091 |
29 663 |
24 697 |
122 727 |
|
Formes |
2991 |
2959 |
2607 |
3438 |
3008 |
7743 |
2. La méthode
2.1. La méthode suivie initialement a été celle employée dans l'étude que j'ai achevée en 1996, c'est-à-dire la statistique lexicale. Comme précédemment, seules les formes négatives préalablement observées dans l'analyse lexicale de la totalité de l'œuvre en vers et en prose de l'auteur ont été prises en compte ici. Il s'agit, plus précisément, des formes qui correspondent, en portugais, aux négatives non, ne… pas ou pas (não) ; rien (nada), sans (sem), ni (nem), contre (contra), jamais (nunca), nul ou personne (ninguém). Le résultat du calcul de l'écart réduit effectué sur ces formes est présenté dans le tableau n° 1 (cf. Annexes).
Ce calcul a permis de découvrir que l'évolution dans l'emploi que l'écrivain faisait des négatives dans ses textes en vers se confirme dans la prose, c'est-à-dire que la forme não, quoiqu'elle ne soit jamais excédentaire, est plus significative dans le premier roman, avec un écart réduit positif de 1,9. Ensuite, dans les contes, ce sont les négatives nada et nunca qui deviennent les plus importantes. Mais c'est le dernier roman qui a le plus grand nombre de valeurs positives significatives de l'écart réduit, avec les formes nem, nunca et ninguém.
Grâce aux calculs effectués par le logiciel Hyperbase de M. Étienne Brunet (dans sa version 3.0), on peut vérifier que, pour un seuil de 5% et un degré de liberté de 3, la corrélation chronologique n'est significative qu'à 0.87. Cependant, cette nouvelle opération, dont les résultats sont résumés dans le tableau n° 2 (cf. Annexes), traduit de façon évidente l'évolution constatée dans l'emploi des formes négatives en question.
L'observation des concordances établies par le logiciel, pour le corpus en vers, avait déjà montré que quelques-unes de ces formes portaient, souvent, sur des verbes. Le corpus composé par les seuls ouvrages en prose s'avère moins abondant que le précédent, ce qui apparaît clairement dans les tableaux 3 et 4 (cf. Annexes). Il s'agit surtout des négatives não, nada, nunca et ninguém et le décompte (manuel cette fois) a permis d'effectuer de nouveau calculs. Ceux-ci montrent que la séquence não+verbe est excédentaire dans la deuxième et dans la troisième partie du corpus, alors que, dans la partie finale du dernier roman, nada+verbe atteint un écart réduit de 2,6 et on observe aussi une valeur assez élevée pour la séquence nunca+verbe. Seule la séquence ninguém+verbe apparaît comme la moins significative.
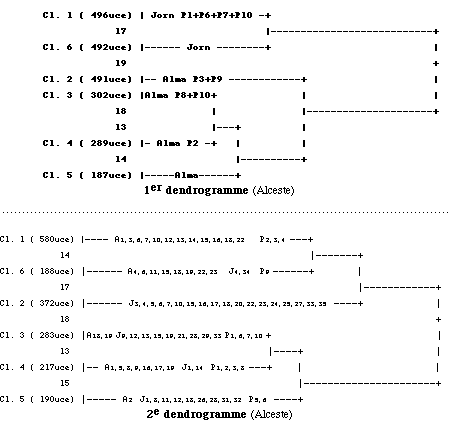
2.2. L'occasion s'est alors présentée de soumettre ces trois ouvrages au logiciel Alceste de M. Max Reinert (dans sa version 3.0). Un premier essai a été effectué sur la version lemmatisée du corpus, mais en respectant sa division naturelle en chapitres et en contes. C'est-à-dire que l'analyse a tenu compte des soixante-huit parties qui le constituent. Les chapitres du roman Jornada de África y sont identifiés par J1… J35, ceux du roman Alma par A1… A23 et les dix contes par P1… P10. En dépit de l'inexistence, à ce moment-là, des dictionnaires de langue portugaise dont le logiciel a besoin pour le classement, Alceste a tenu compte de 82,4% d'occurrences analysables et il a regroupé le vocabulaire en six classes. Le nombre d'u.c.e. classées était alors de 2 257, soit 96.87% du corpus.
Ces six classes correspondaient grosso modo aux deux romans, les contes étant éparpillés entre les classes relatives aux deux autres ouvrages. La décision de conserver la partition naturelle des textes avait pour but d'identifier les thèmes communs aux différentes parties, à partir de ce que M. Max Reinert considère comme les " mondes lexicaux " qui les caractérisent. Il fallait naturellement s'attendre à une opposition presque totale entre les deux romans, compte tenu de leur thématique particulière. En effet, Jornada de África est un roman de guerre, inspiré des combats entre l'armée portugaise et les nationalistes africains en Angola, au cours des années soixante et au début des années soixante-dix. L'action du roman Alma, en revanche, se situe vers la fin de la Deuxième Guerre Mondiale et le narrateur y raconte ses souvenirs d'enfance, dans une petite ville de province, au Portugal. Pour ce qui est des contes de O Homem do País Azul, ils couvrent des thèmes assez différents les uns des autres et ils deviennent, dans un corpus ainsi constitué, une sorte de " lest " ou d'élément modérateur.
Au premier dendrogramme (cf. Annexes), construit par le logiciel Alceste, et qui montre la constitution des six classes stables de vocabulaire du corpus lemmatisé, j'ai ajouté la distribution des contes et des deux romans.
Après la constitution des dictionnaires nécessaires au logiciel Alceste, une première tentative de lemmatisation automatique du corpus a montré qu'il s'avérait indispensable de les perfectionner. Il a fallu également procéder à un codage particulier des nombreux Noms Propres présents dans le corpus. Cependant, les particularités et les exigences de ces dictionnaires de lemmatisation dépassent le cadre de ce travail et je ne m'en occuperai pas ici.
Le deuxième essai d'analyse par Alceste, sur les textes non lemmatisés, a abouti alors à un classement du vocabulaire un peu différent du corpus préalablement lemmatisé à la main, mais avec un nouveau regroupement en six classes, en dépit d'une distribution distincte des soixante-huit parties qui le composent. On le voit d'ailleurs nettement sur le 2e dendrogramme, où les chapitres sont également signalés sur la ligne correspondant à chacune des classes (cf. les Annexes).
3. Les segments répétés
L'aspect le plus important, du point de vue qui nous intéresse ici, est pourtant le nombre de segments répétés (SR) relevés par Alceste, dans lesquels figurent des formes négatives. À partir de la version non lemmatisée du corpus, le logiciel a établi une liste de 6322 SR, dont 619 contenaient les formes en question, soit 9,79% des segments identifiés. La version lemmatisée, vu que la flexion verbale y a été supprimée de façon à mieux cerner les séquences recherchées, a fourni une liste de 5478 SR, dont 607 contiennent les mêmes formes négatives, soit 11,08% des segments retenus par le logiciel. La liste des seuls segments comprenant des négatives s'étend sur dix longues pages, dont la première est présentée en annexe.
3.1. À partir de ce listing, il a été alors possible de repérer avec plus de facilité les séquences recherchées, formées par " négative+verbe ". Parmi les plus nombreuses se trouvaient évidemment celles formées par não ter [ne pas avoir] et não ser [ne pas être], qui comprennent la totalité des temps composés. Leur traitement aurait pourtant exigé un codage particulier de ces temps, ce qui dépasserait largement le cadre de l'observation prévue. Elles ont donc été exclues de l'analyse. Beaucoup d'autres séquences " négative+verbe ", extrêmement intéressantes du point de vue du discours, n'avaient pourtant pas un nombre d'occurrences assez important pour une approche statistique. Le seuil de fréquence a donc été fixé à 20, à une seule exception près : não ver [ne pas voir], qui a 19 occurrences. À cause de ce seuil de fréquence, deux autres séquences négatives assez courantes ont été ajoutées à la liste, quoiqu'elles ne comprennent aucun verbe : il s'agit de nunca mais [plus jamais] et de nem sequer [même pas]. Les séquences négatives retenues figurent dans le tableau n° 5, qui contient le total des occurrences, leurs effectifs dans chacune des cinq parties du corpus et les valeurs respectives de l'écart réduit. Les valeurs les plus intéressantes, dans la mesure où il s'agit de séquences excédentaires, correspondent à não ir [ne pas aller] dans Jorn1, não poder [ne pas pouvoir] dans Jorn2, não gostar [ne pas aimer] dans Alma1 et nunca mais [plus jamais] dans Alma2.
3.2. C'est grâce à Hyperbase qu'il a été possible de reconstituer et de travailler la liste des chaînes qui intéressent dans cette observation du corpus. Le graphique de l'analyse factorielle, qui constitue le tableau n° 6, présenté en annexe, permet de mieux visualiser leur distribution dans les ouvrages.
On y voit que les deux parties dans lesquelles le roman de guerre Jornada de África a été divisé restent ensemble dans le même secteur et elles attirent les séquences não haver [ne pas exister, ne pas y avoir], não poder [ne pas pouvoir] et não ir [ne pas aller]. La séquence não haver n'atteint pas une valeur positive significative du point de vue de l'écart réduit, quoiqu'elle monte à 1,8 dans la première partie du roman et à 1,7 dans la partie finale. Elle correspond à une expression de vide, d'absence de repères dans l'horizon d'attente du personnage, et elle est parfois renforcée par d'autres négatives : " il n'y a plus ", " il n'y a rien ", " il n'y a personne ". Ce sont pourtant les séquences não poder et não ir qui sont employées de façon plus significative dans ce roman, leur écart réduit atteignant 2,5 et 2,9, respectivement. Não poder traduit l'impuissance des personnages, leur incapacité à échapper à la mort, et parfois leur sentiment de révolte : " ça ne peut pas être vrai ", " ça ne peut pas se passer comme cela ". Não ir correspond surtout à des obstacles que les personnages n'ont pas surmontés.
Aucune des séquences négatives n'est significative dans le recueil de contes O Homem do País Azul lequel, sur le graphique, s'oppose au premier roman, même s'il reste assez proche du croisement des deux axes. Cela est dû, sans doute, à un emploi relativement important de l'une des séquences qui caractérisent le roman précédent, não haver. On ne voit pas beaucoup de séquences ayant le même poids dans ces contes et dans le dernier roman, en dépit de la valeur relativement élevée, mais non significative, de l'écart réduit de nunca mais [plus jamais]. Cette dernière séquence est plutôt caractéristique de la partie finale du dernier ouvrage du corpus. Dans le secteur des contes ne figurent que des séquences sans aucune spécificité : não dizer [ne pas dire], não ver [ne pas voir] et nem sequer [même pas], avec un écart réduit non significatif de 1,5. Le secret et le silence liés au refus du dire, dans ces contes, peuvent correspondre, soit à une forme de solidarité, soit à une profonde impression de solitude. La répétition de " ne pas voir " traduit l'impossibilité, pour les personnages, de trouver des repères. Quant à nem sequer, elle renforce toujours une négative précédente, comme si un dernier espoir avait été annihilé. Cette séquence apparaît une fois après " plus jamais " et " sans " et deux fois comme renforcement de " ne pas réussir ", " ne pas pouvoir ", " ne pas dire ". Elle est pourtant plus courante dans le dernier roman que dans les contes.
Le roman Alma, de son côté, semble être marqué par un emploi assez spécifique des séquences négatives, la première partie (Alma1) se trouvant installée dans le secteur opposé à celui où figure la deuxième partie, Alma2. Dans ce récit de souvenirs d'enfance il s'agit, au début, de não gostar [ne pas aimer], avec un écart réduit de 2,7, et de não querer [ne pas vouloir]. L'expression du rejet caractérisait en effet le comportement du narrateur lorsqu'il était enfant. Il refusait souvent l'autorité maternelle, tandis qu'il montrait une vive admiration à l'égard de ceux qui s'opposaient au régime totalitaire de Salazar. Dans la deuxième partie de l'ouvrage les séquences négatives sont plus variées et plus nombreuses, cinq d'entre elles se regroupant dans le même secteur que Alma2 : não saber [ne pas savoir] et ninguém saber [**personne ne savoir], não conseguir [ne pas réussir], nem sequer [même pas] et surtout, la plus significative, avec un écart réduit positif de 3,1, nunca mais [plus jamais]. Le savoir comble le vide, alors que " ne pas savoir " implique une insécurité et une incertitude dues à l'absence de repères. Le narrateur se souvient en effet que, souvent, " personne ne savait pourquoi, comment, vers où aller ". " Ne pas réussir " traduit un sentiment d'impuissance des personnages face aux événements, dans un monde que le narrateur n'a de cesse d'éprouver comme injuste. Par opposition au présent, le temps de l'enfance était celui du bonheur, qui ne reviendra " plus jamais ", car le départ du narrateur de sa ville natale a marqué une fracture par rapport au temps ultérieur. Il lui reste désormais la révolte et la nostalgie d'un passé perdu.
3.3. Un troisième logiciel a été employé dans cette observation des séquences négatives dans les textes de fiction de l'écrivain Manuel Alegre : celui de M. Xuan Luong, Analyse arborée. Malgré un calcul différent de ceux des deux logiciels précédents, il a pourtant confirmé presque totalement la distribution des douze séquences négatives retenues dans cette observation du corpus (cf. tableau n° 7). Dans ce dernier tableau, seule la séquence nem sequer [même pas], qui figurait sur le graphique de l'analyse factorielle dans le secteur des contes — où il atteint un écart réduit de 1,5 — figure maintenant sur la branche correspondant à Alma2. En effet, son écart réduit atteint ici une valeur un peu plus élevée, avec 1,8. Toutes les autres séquences se distribuent sur les branches de l'arbre, suivant les mêmes regroupements que sur le graphique tracé par Hyperbase. Cela confirme donc l'impression d'une relation négative au monde, propre aux protagonistes des ouvrages de fiction de Manuel Alegre.
4. Conclusion
Les données textuelles obtenues grâce aux analyses effectuées par les trois logiciels mis en application s'avèrent être complémentaires et, de façon heuristique, elles ont permis de mieux progresser dans l'observation de ce corpus littéraire.
Le nombre de séquences négatives présentes dans le corpus étudié, notamment les séquences " négative+verbe ", reflète nettement une certaine " vision du monde " caractéristique des personnages romanesques créés par l'écrivain. En fait, cette vision n'est autre que la sienne, compte tenu du caractère autobiographique qui marque ses ouvrages : de la révolte contre la fatalité de la guerre et de tout un univers adverse, présent dans le roman Jornada de África, on passe à la sensation d'impuissance et de solitude des contes de O Homem do País Azul, pour remonter avec nostalgie jusqu'à l'enfance du narrateur. Dans le roman Alma, on suit la formation de la personnalité d'un enfant qui, prenant conscience d'une altérité déplaisante, s'affirme déjà par le rejet et le refus. À mesure qu'il se construit un idéal de résistant, il conteste la fragilité et l'impuissance de l'homme face au monde environnant et cette rétrospective de son passé révèle dès le début un comportement caractérisé par la révolte et le combat contre toute forme de contrainte, s'exprimant dans des structures négatives.
Références
Brunet, É. (1997). Hyperbase, version 3.0. Nice : CNRS-INaLF, UPRESA "Bases, corpus et langage".
JADT (1993). Secondes journées internationales d'analyse statistique de données textuelles. Paris : Télécom.
JADT (1995). III Giornate internazionali di Analisi Statistica dei Dati testuali, Roma : CISU.
Luong, X. (1994). L'analyse arborée des données textuelles : mode d'emploi. In Travaux du Cercle Linguistique de Nice, 16, 25-42.
Maingueneau, D. (1993). Le contexte de l'œuvre littéraire. Énonciation, écrivain, société. Paris : Dunod.
Reinert, M. (1993). Les "mondes lexicaux" et leur logique. In Langage et société, 66, 5-39.
Reinert, M. (1996).VIIème Université d'été en Analyse des Données Textuelles, Cahiers 1 et 2. Carcassonne : Image.
Vilhena, A. M. (1997). L'évolution du vocabulaire de l'œuvre littéraire de Manuel Alegre, de 1960 à 1993. Paris : Champion
Annexes
|
Total |
Jor1 écart |
Jor2 écart |
PAz écart |
Alm1 écart |
Alm2 écart |
|
|
não |
1491 |
270 0,4 |
353 1,9 |
267 1,6 |
314 -2,8 |
287 -0,8 |
|
nada |
127 |
18 -1 |
27 -0,1 |
29 2 |
23 -1,6 |
30 1 |
|
sem |
173 |
35 0,9 |
42 0,8 |
30 0,3 |
35 -1,2 |
31 -0,7 |
|
nem |
280 |
48 0,3 |
46 -2,1 |
40 -1 |
73 0,7 |
73 2,5 |
|
contra |
70 |
17 1,4 |
14 -0,3 |
11 0,1 |
17 0 |
11 -0,9 |
|
nunca |
171 |
13 -4 |
25 -2,2 |
41 3 |
47 1 |
45 2 |
|
ninguém |
161 |
27 0,3 |
31 -0,7 |
25 0,3 |
35 -0,7 |
43 2,1 |
Tableau n° 1
|
Corrélation r |
nada +0.28 |
|
sem -0.88 |
ninguém +0.64 |
|
contra -0.79 |
nem +0.76 |
|
não -0.59 |
nunca +0.83 |
Tableau n° 2
|
Séquences |
Total |
Séquences |
Total |
|
não ter |
77 |
nunca ter |
11 |
|
não haver |
93 |
nunca haver |
1 |
|
não saber |
150 |
nunca (se) saber |
7 |
|
não poder |
50 |
nunca poder |
2 |
|
não querer |
38 |
nunca ser |
8 |
|
não dizer |
21 |
nunca mais |
51 |
|
não ser |
222 |
ninguém ter |
6 |
|
não fazer |
11 |
ninguém saber |
22 |
|
nada ter, não ter nada |
7 |
ninguém poder |
6 |
|
nada saber, não saber nada |
4 |
ninguém querer |
8 |
|
nada poder, não poder nada |
5 |
ninguém dizer |
6 |
|
nada ser |
2 |
ninguém ser |
8 |
|
nada fazer |
1 |
ninguém fazer |
3 |
Tableau n° 3
|
Séquences |
Tot |
J1 |
écart |
J2 |
écart |
PA |
écart |
A1 |
écart |
A2 |
écart |
|
não+v |
643 |
119 |
0,5 |
160 |
2 |
124 |
2 |
124 |
-2,9 |
116 |
-1,3 |
|
nada+v |
21 |
4 |
0,2 |
4 |
0 |
2 |
-1 |
2 |
-1,6 |
9 |
2,6 |
|
nunca+v |
80 |
9 |
-1,5 |
18 |
0,2 |
15 |
0,6 |
15 |
-1,1 |
23 |
1,9 |
|
ninguém+v |
65 |
9 |
-0,8 |
12 |
-1 |
13 |
0,8 |
16 |
0,1 |
15 |
0,6 |
Tableau n° 4
|
total |
Jor1 |
écart |
Jor2 |
écart |
PAz |
écart |
A 1 |
écart |
A 2 |
écart |
|
|
não haver |
93 |
23 |
1,8 |
27 |
1,7 |
21 |
1,6 |
11 |
-3 |
11 |
-2 |
|
não saber |
150 |
20 |
-1 |
36 |
0,7 |
27 |
0,5 |
31 |
-1 |
36 |
1,2 |
|
não poder |
50 |
11 |
0,8 |
18 |
2,5 |
11 |
1,1 |
7 |
-2 |
3 |
-2 |
|
não querer |
38 |
5 |
-1 |
8 |
0 |
8 |
0,8 |
13 |
1,4 |
4 |
-1 |
|
não ir |
32 |
12 |
2,9 |
10 |
1,3 |
0 |
-3 |
7 |
0 |
3 |
-2 |
|
não conseguir |
28 |
4 |
0 |
6 |
0 |
5 |
0,2 |
6 |
0 |
7 |
0,6 |
|
não gostar |
23 |
6 |
1,1 |
1 |
-2 |
3 |
0 |
11 |
2,7 |
2 |
-1 |
|
não dizer |
21 |
1 |
-2 |
5 |
0,2 |
5 |
0,9 |
7 |
1 |
3 |
-1 |
|
não ver |
19 |
1 |
-1 |
5 |
0,5 |
4 |
0,6 |
6 |
0,8 |
3 |
0 |
|
nunca mais |
51 |
4 |
-2 |
10 |
0 |
12 |
1,4 |
6 |
-2 |
19 |
3,1 |
|
nem sequer |
26 |
0 |
-2 |
3 |
-1 |
7 |
1,5 |
7 |
0,3 |
9 |
1,8 |
|
ninguém saber |
22 |
3 |
-1 |
6 |
0,6 |
4 |
0,2 |
3 |
-1 |
6 |
0,8 |
|
Total |
553 |
90 |
-1 |
135 |
1,6 |
107 |
1,9 |
115 |
-2 |
106 |
-1 |
Tableau n° 5

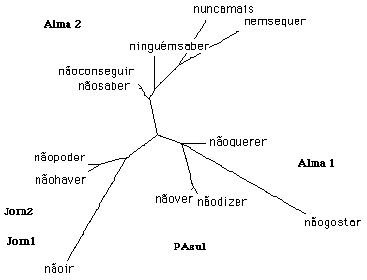
Tableau n¡ 7
Séquences négatives
nunca
2 34 nunca mais
2 11 nunca ninguém
3 8 e nunca mais
2 8 e nunca
2 6 que nunca
3 2 que nunca mais
3 2 nunca mais a
4 2 mais do que nunca
6 1 que nunca ninguém saber quem ser
4 1 o homem que nunca
3 1 de que nunca
4 1 porque ser que nunca
5 1 nunca ninguém saber ao certo
5 1 nunca mais a minha av–
4 1 modo que nunca mais
3 1 crer que nunca
3 1 baixo e nunca
3 1 ver que nunca
4 1 ver o que nunca
4 1 se e nunca mais
5 1 e nunca mais a tia
7 1 e eu n‹o saber que nunca mais
3 1 do que nunca
4 1 dizer lhe que nunca
ninguém
2 7 que ninguém
4 4 ninguém saber ao certo
2 4 ninguém saber
3 3 que ninguém saber
4 1 que ninguém saber que
4 1 que ninguém saber porque
5 1 que ninguém saber se ser
4 1 ninguém saber que ele
4 1 ninguém saber quem ser
5 1 ninguém saber como se chamar
6 1 ninguém saber como ele a hist–ria
3 1 ninguém saber como
3 1 coisa que ninguém
3 1 ser que ninguém
4 1 para que ninguém saber
5 1 ela ser a que ninguém
3 1 dizer que ninguém
nem
2 26 nem sequer
2 12 mas nem
2 11 nem o
2 9 nem a
2 6 nem se
4 2 nem a minha m‹e
3 2 nem se sentar
3 2 nem se saber
3 1 nem o que
4 1 nem o de do
5 1 nem o filho da m‹e
3 1 nem o alferes
3 1 nem o ver
4 1 nem o da m‹e
3 1 nem o da
3 1 nem a tropa
3 1 nem a guerra
3 1 nem a espera
3 1 nem a um
4 1 nem a minha av–
4 1 nem se o homem
5 1 nem se saber se ter
5 1 nem se saber ao certo
5 1 mas nem o nome de
3 1 mas nem o
nada
3 6 nada a fazer
3 6 n‹o dizer nada
2 4 dizer nada
3 2 nada a ver
2 2 nada a
4 1 n‹o me dizer nada
5 1 n‹o dizer nada ˆ m‹e
4 1 n‹o dizer nada a
4 1 mas n‹o dizer nada
3 1 lhe dizer nada
contra
2 19 contra o
2 10 contra a
3 2 contra o do
3 2 contra a ordem
3 1 contra o de
3 1 contra o tempo
3 1 contra o ritmo
3 1 contra o povo
4 1 contra a que no
4 1 contra a de tudo
3 1 contra a de
3 1 contra a sua
sem
2 5 sem o
3 3 sem o outro
3 1 sem o olho
3 1 sem o ver
3 1 sem o seu
3 1 sem o saber
n‹o
2 66 n‹o ser
2 52 n‹o haver
2 37 n‹o se
2 32 mas n‹o
2 30 n‹o ter
2 27 n‹o saber
2 27 n‹o poder
2 25 n‹o me
3 23 n‹o saber se
2 20 que n‹o
2 17 n‹o ir
2 17 e n‹o
2 16 n‹o querer
2 11 n‹o conseguir
2 9 eu n‹o
3 8 n‹o gostar de
3 8 n‹o ser poss’vel
2 7 se n‹o
2 7 para n‹o
3 7 n‹o ser preciso
2 7 n‹o dizer