GOUVERNER PAR LES SONDAGES ET ANALYSER PAR LA PARAPHRASE
"MÉTHODE TIAD"
Ismaïl Timimi
Connaissances, Recherche d'information, Interfaces
& Systèmes du Traitement Automatique des Langues
Équipe : CRISTAL - Laboratoire GRESEC
Université : Stendhal, B.P. 25, 38 040 Grenoble Cedex 9, France
Abstract
To contribute to the development of discourse analysis methods, the method TIAD (Computer Processing in the Discourse Analysis) has been elaborated as a tool of corpus deprivation combining the linguistic analysis (derivational morphology, semantic) and the algebraic mathematics (distances theory between statements). Given a discourse corpus produced in homogeneous conditions socio-linguistics (inquiries, archives of a party, leaflets on a social problem, ...), the aim is to extract classes of statements linked by paraphrase relationship. After an account of method generalities (localisation, partners, objects, hypothesis), we itemise the mathematical tools and the linguistic formalism that contribute to a new method of the discourse analysis. This new method has been translated into an algorithm witch leads to a new software called TIAD (Traitement Informatique de l'Analyse du Discours).
1. Localisation de la méthode TIAD
1.1 De la statistique vers la linguistique
Source d’embarras dans le dépouillement des sondages, questionnaires, enquêtes et observations sociologiques, les réponses aux questions ouvertes ont suscité un intérêt très particulier vu les difficultés qu’elles engendrent pour le traitement. Les premières recherches ont eu recours aux seuls outils statistiques en se basant sur le critère des occurrences des mots et des segments répétés. Peu après, il est apparu plus judicieux de conjuguer ces outils avec ceux de l’analyse linguistique (Lallich et Rouault, 1995), en l'occurrence, les composantes morpho-syntaxiques et sémantiques. En fait, les méthodes statistiques, utilisées seules, ne rendent pas compte des aspects linguistiques d’un corpus qui sont très utiles pour l’analyse de son contenu, ce qui infère explicitement des résultats incomplets et imparfaits. Par exemple, à défaut d'une analyse morpho-syntaxique, des formes comme "prendre, prise, preneur, prends" seront dépourvues de tout lien entre elles et seront scrutées indépendamment. Idem pour des formes comme "pirater, cambrioler, voler" qui seront sondées distinctement à défaut d'une analyse sémantique. Ce traitement linguistique en langage naturel permet alors de localiser les différents points de parenté entre les mots du corpus, d'augmenter leurs occurrences, et d'extraire par suite les énoncés considérés "proches" au sens sémantique.
1.2 De la linguistique vers les métriques
Or, la définition des relations sémantiques entre énoncés a également engendré des difficultés. Plusieurs écoles ont préféré alors le recours à la notion de la paraphrase et deux grands concepts se sont succédés historiquement (Fuchs, 1994). Un concept qualifié de pré-linguistique : c’est l’approche traditionnelle rhétorico-littéraire et pragmatique qui a utilisé le terme de paraphrase pour désigner la reformulation ; mais le manque de propriétés d’équivalence (symétrie, transitivité) dans ce concept d’une part et la difficulté de sa modélisation et de son automatisation d’autre part, l’ont conduit à des impasses. Ensuite, est apparu le second concept dans les travaux de Z. Harris et M. Pêcheux : c’est l’approche classique de la linguistique qui a défini la paraphrase dans un cadre étranger à son terrain d’origine : dans un cadre mathématique associant l’algèbre relationnelle (matrices) à l’analyse métrique (distances entre énoncés). Il s'agit de la paraphrase comme relation d'équivalence, dont la modélisation et l'automatisation sont mises en œuvre dans TIAD.
2. Fonctionnement de la méthode TIAD
2.1 Partenaires
Dans le cadre des travaux de recherche de l'équipe CRISTAL concernant le traitement automatique des langues, plusieurs programmes ont été développés pour des objectifs bien indépendants. Trois d'entre eux se sont trouvés soudainement en parfaite collaboration pour permettre de passer d'une analyse de mots à une analyse de structures d'énoncés, puis à une analyse de discours orientée paraphrase. D'abord, un logiciel dit CRISTAL a été réalisé pour donner en sortie une analyse morphologique des mots d'un corpus. Ensuite, un autre logiciel dit GAG a été conçu pour la recherche d'information dans les énoncés d'un corpus ; il consiste à en extraire les énoncés qui répondent à une structure syntaxique précise. Enfin, un troisième logiciel, dit TIAD et qui fera l’objet principal de cet article, a été élaboré pour extraire d'un corpus les énoncés en relation de paraphrase.
2.2 Objectifs
Pour dépouiller un corpus formé de discours, qui eux-mêmes sont découpés en énoncés, le TIAD s’est démarqué des méthodes classiques de l'analyse de contenu et s'est spécialisé dans l'extraction des énoncés supposés en relation de paraphrase. On admet que les énoncés d'une même classe paraphrastique ont un Noyau Informatif (NI) en commun, appelé parfois invariant commun, ou pivot paraphrastique. Ceci ressemble un peu au concept des segments répétés dans la théorie des statistiques textuelles. D'autres fonctionnalités en matière d'analyse textuelle (indexation lexicologique et lexicographique, degré de stéréotypie, etc...) peuvent être déduites lors des phases préliminaires du progiciel (Timimi et Rouault, 1997).
2.3 Hypothèse de base
Le corpus d'étude doit être formé de discours produits dans des conditions socio-linguistiques homogènes comme une série de questionnaires, des articles sur un même événement, ou des résumés d'un même document, etc... En principe, cette contrainte d'homogénéité assure une répétitivité dans le vocabulaire du corpus, une stabilité du sens dans le lexique employé, une cohérence relative dans le contenu des énoncés, ce qui garantit par conséquent la présence des noyaux informatifs, objets des classes paraphrastiques. Les corpus produits par des enfants répondent pleinement à cette particularité contraignante vu que le vocabulaire employé est très restreint et que les structures syntaxiques ont une certaine ressemblance.
Les exemples cités ci-dessous, sont empruntés tantôt d'un corpus formé de textes d'enfants répondant à la question ouverte : "Aimeriez-vous la ville ou la campagne et pourquoi ?" tantôt d'un corpus formé de récits de rêves d’enfants (Zlotowicz, Les cauchemars de l'enfant, PUF).
Pour ne pas alourdir, on présentera certains de ces exemples sous leur forme de surface.
3. Outils mathématiques
3.1 Synthèse
Pour les non familiarisés avec les formules mathématiques, il suffit de retenir que lorsqu'on agit sur un énoncé par le biais d'une opération élémentaire (déplacer un mot, effacer un mot, insérer un mot, substituer un mot à un autre), cet énoncé se transforme en un autre, et cette opération a un coût qui dépend du mot en jeu. Quand on efface un "verbe central" ça doit coûter cher car l'information dans l'énoncé change amplement. Pour passer d'un énoncé à un autre, on applique une suite d'opérations dont le coût global sera la somme des coûts des opérations constituantes. Comme le nombre de possibilités pour transiter entre deux énoncés est illimité, on retient la suite dont le coût est minimal et on l'appelle distance de transition. Deux énoncés sont dits en paraphrase si cette distance est relativement petite.
3.2 Généralités :
Soit V un vocabulaire fini et V* le monoïde libre engendré par V. On note l l'élément vide.
Les éléments de V (resp. de V*) seront appelés abusivement des mots (resp. des énoncés).
Définition : Une opération de transition élémentaire (OTE), notée a® b, est un couple (a, b) de V* x V* hormis (l, l) dont la longueur des éléments est nulle ou égale à 1. On l'appelle :
* une règle de Déplacement D(a) si a = b on note a® a
* une règle d'Effacement E(a) si a π l et b = l on note a® l
* une règle d'Insertion I(b) si a = l et b π l on note l® b
* une règle de Substitution S(a, b) si a π l et b π l on note a® b
Étape 1 : Le coût d'une opération de transition élémentaire est un nombre réel positif qui vérifie : g (a∆b) = g (b∆a) et g (c∆c) = 0 " a, b, c
Étape 2 : Une suite de transition w entre deux énoncés A et B, notée w = R1...Rn est une séquence d'OTE qui permet de transiter de A vers B. Son coût global, noté cost (w), est la somme des coûts des OTE.
![]()
Étape 3 : Soit W(A, B) l'ensemble infini des suites de transition de A vers B. La distance de transition de A vers B, notée cost (A, B), est le coût de transition minimal dans les suites de transition de A vers B (il s'agit bien d'une distance au sens mathématique du terme) :
![]()
Théorème : Soient A et B deux énoncés de longueur respective n et m. L'algorithme récurrent suivant (Sellers, 1974) permet de calculer cost (A, B). Soient A(i) le ième élément de A, et Ai la séquence formée des i premiers éléments de A, Ai=A(1)...A(i). Il en résulte que An=A et A0=l
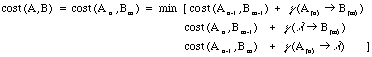
Étape 4 : Soit a une borne numérique fixée par l'utilisateur, dite seuil de distorsion ou limite de tolérance de déformation (Fuchs, 1994). A et B deux énoncés du corpus.
A et B sont dits en relation directe ssi cost (A, B) £ a.
A et B sont en relation de paraphrase si $ une suite d'énoncés ![]() où
où
![]()
3.3 Application
Dans les règles d'écriture de TIAD, le corpus est formaté de sorte que les éléments A, B de V* soient les unités issues de la segmentation des discours (syntagmes, propositions ou phrases) et que les éléments a, b de V soient des couples (b>t) où b est la base lexicale lemmatisée de la forme de surface et t son trait morphologique. Par exemple, l'énoncé de surface (A) sera analysé, lemmatisé puis réécrit en format (A’) :
A : "je rêve des voleurs qui volent dans des armoires."
A’ : "(je >Y) (rêver >V) (des >D) (voler >F-nan) (qui >P) (voler >V) (dans >P) (des >D) (armoire >F-nom) (. >T)"
Dans ce cas précis, on parlera des OTE suivantes : déplacement D(b>t), effacement E(b>t), insertion I(b>t), substitution à bases égales S(b>t, b>t’), et substitution à bases différentes S(b>t, b’>t’). Or l’effectif des traits morphologiques (t) dans un corpus est plus petit que celui des bases lexicales (b), et par suite plus maîtrisable. Aussi, dans le but d'assouplir les calculs, les accessoires mathématiques vus ci-dessus ne seront appliqués qu’en fonction de deux questions : 1- Quel est le trait morphologique du mot ? 2- Dans le cas des substitutions, existe-t-il un lien de parenté entre les bases lexicales des mots en jeu ? Les coûts sont alors :
* Pour le Déplacement : g (b>t ® b>t) = 0
* Pour l'Insertion et l’Effacement : g (b>t ® l) = g (l® b>t) = CIE (t)
* Pour la Substitution à bases Egales : g (b>t ® b>t’) = g (b>t’ ® b>t) = CSE (t, t’)
* Pour la Substitution à bases Différentes : g (b>t ® b’>t’) = g (b’>t’ ® b>t) = CSD (t, t’)
Par exemple, soient les deux énoncés suivants :
A : (le >D) (garçon >F-nom) (attraper >V) (le >D) (sorcier >F-nan) (. >T)
B : (le >D) (garçon >F-nom) (croiser >V) (le >D) (sorcier >F-nan) (. >T)
Pour transiter de A vers B, on peut procéder, éventuellement, par la substitution à bases différentes de (attraper >V) par (croiser >V) dont le coût est CSD(V,V) ; ou bien par l’effacement de (attraper >V) suivi de l’insertion de (croiser >V) dont le coût est 2 CIE (V).
L'étape suivante du système est de chiffrer ces coûts. Or, la méthode TIAD se fonde sur le principe de comparaison et non pas d'évaluation, le but n'est pas de répondre à la question "combien coûte une telle transition ?", mais plutôt à la question "telle transition coûte-t-elle plus ou moins chère que les autres ?". De ce fait, on pondère chaque trait t d'un poids numérique p, et les coûts suivants répondront favorablement à l'objectif du système :
CIE(t) = 2p CSE(t, t’) = 2| p - p’ | CSD(t, t’) = max(p, p’) + | p - p’ |
Ils favorisent les regroupements des énoncés dont les bases lexicales sont égales. Par exemple, dans les formes de surface (rêver, rêveur, criminel), remplacer (rêver >V) par (rêver >F-nan) coûtera moins cher que de le remplacer par (crime >F-nan).
Ils assurent, entre autres, que deux énoncés ayant un même syntagme (verbe nom, par exemple), seront plus proches que ceux ayant seulement un verbe en commun.
4. Outils linguistiques
4.1 Dimension morphologique (Interface CRISTAL-TIAD)
Pour pouvoir confronter les énoncés entre eux, TIAD a besoin dans sa phase de prétraitement, d'une couverture lexico-morphologique du corpus qui permet d'en reconnaître aussi bien les bases lexicales b que les traits morphologiques t correspondants. Ensuite, tout le calcul sera basé sur le genre et le nombre d'OTE dans chaque transition. Cette couverture décèle les liens morphologiques qui peuvent exister entre les formes de surface telles que "rêveur, rêve, rêvons, rêvées, ..." et contribue ainsi à la détermination d’un éventuel noyau informatif (NI).
Effectivement, cette procédure est du ressort de l'analyseur Cristal. Modulo quelques modifications d'adaptation, une interface de liaison est instaurée pour établir une coopération entre les deux systèmes, ce qui a rendu le prétraitement de TIAD quasi automatique. Les deux dimensions de la morphologie flexionnelle et dérivationnelle sont intégrées pour permettre de scruter le maximum de noyaux informatifs entre les énoncés. Néanmoins, cette analyse n'échappe pas aux difficultés dues aux ambiguïtés induites par les homographes et autres ..., Cristal utilise un filtre statistique fondé sur la théorie des chaînes de Markov, et qui affecte à chaque forme de surface du corpus le couple (b >t) le plus probable.
Les traits adoptés par TIAD sont principalement ceux de Cristal, répartis en deux séries :
* Série LEX de pondération forte : V verbe ; F(nom et/ou adj) ; W adverbe.
* Série GRAM de pondération faible pour les autres catégories dites grammaticales.
Pour une étude particulière, l'ajout d'un nouveau trait reste possible. Par exemple, pour avoir une classe formée de tous les énoncés pivotés par un invariant à très haute occurrence, il suffit de doter ce dernier d'un trait spécial et de le pondérer fortement. Si la composante temporelle est utile à étudier dans un corpus, il suffit de prendre avec le trait V sa variable temps etc...
Enfin, les corpus caractérisés par un nombre élevé de liens dérivationnels nécessitent une analyse plus rigoureuse. On ne peut admettre ni de regrouper dans une même catégorie (agi, agissements, agiter, agitation, réaction, action, actionnaire, actif, activité) en disant qu'ils sont tous à bases égales "agir", ni de les disperser en justifiant qu'ils sont à bases différentes. Autrement dit, s’il existe un lien dérivationnel entre deux formes, certes, elles ne seront pas scrutées à bases différentes, mais pas nécessairement non plus à bases égales. On introduit alors une matrice en option, dite Coût de Substitution à bases Lexicalement égales (CSL), elle prend en compte le nombre d'opérations suffixales séparant deux dérivés et évalue plus correctement le degré de proximité entre eux (Timimi, 1996). Si l'intégration de CSL réduit le nombre et le cardinal des classes de paraphrase, elle permet par contre de les générer plus pertinemment.
4.2 Dimension syntaxique (Interface GAG-TIAD)
Après la réécriture du corpus en codage morphologique, le système TIAD confronte les énoncés pour calculer le coût minimal parmi les différentes suites possibles de transition. L'utilisation de l'algorithme de Sellers (cf. 3.2) impose que les transitions ne s'effectuent que de la droite vers la gauche sans que leurs arcs représentatifs se croisent.
Exemple :
(a) : le sorcier a pu attraper l’enfant (b) : l’enfant a pu attraper le sorcier
(c) : nous avons fait un mauvais rêve (d) : nous avons fait un rêve mauvais
S'il est heureux que la distance de transition entre les deux énoncés (a) et (b) soit bien non nulle puisque l'algorithme tient compte de la position des éléments dans l’énoncé, il est regrettable que la distance de transition entre les deux énoncés (c) et (d) ne soit pas nulle alors qu'ils sont en parfaite relation de paraphrase. Ceci persistera dans tous les cas des allotaxies.
Pour pallier cette imperfection, on fait appel à l'OTE "déplacement" dont le coût est nul. Le principe consiste à reconnaître les énoncés qui nécessitent une modification dans la position de leurs éléments et demander à l’utilisateur, en mode interactif, d’approuver ou non une éventuelle transposition au sein de l’énoncé. Ceci permet d’avoir une certaine uniformité de syntaxe dans les énoncés du corpus. Pour ce faire, on intègre le programme GAG que nous avons réécrit en C et qui génère tous les énoncés répondant à une requête de structure précise (Antoniadis, 1984). Par exemple, on fixe un cadre à structure partiellement libre (ou partiellement déterminée) du style * F-nom F-adj * ; et le système donne en sortie tous les générateurs maximaux (ce sont les énoncés dans notre cas) contenant un adjectif précédé d'un nom ; puis on décide ou non l’application de l’opérateur "déplacement". Le couplage de GAG au système TIAD, a donné à ce dernier un nouvel élan associant à l’automatisation dans le prétraitement une amélioration dans le dépouillement.
4.3 Dimension sémantique (Dictionnaire Externe de synonymes)
La paraphrase soutenue par TIAD ne fait appel à aucun dictionnaire de synonymes externe, elle se base uniquement sur les NI en commun extraits des énoncés à l’issue de l’analyse morphologique. Ainsi, les formes "jouets, jeu, joueur, jouer, ..." sont en lien de parenté grâce au procédé morphologique. Néanmoins, la forme "s'amuser" qui est censée être proche de l'ensemble, dans le sens de paraphrase, sera reconnue à base différente et se trouvera par suite à la même distance que la forme "se laver" qui n’a aucun lien sémantique avec l’ensemble. Des imperfections surgissent et provoquent alors des classes incomplètes et/ou incohérentes.
Exemple 1 :
(a) : j’ai croisé un fantôme (b) : j’ai croisé un clochard
(c) : j’ai rencontré un sorcier (d) : j’ai acheté un cartable
Les énoncés (a) et (b) peuvent faire l’objet d’une même classe de paraphrase pivotée par le noyau "j’ai croisé". Par contre, (c) et (d) seront à la même distance de la classe bien que (c) se trouve plus proche de la classe que (d).
Exemple 2 :
(a) : je préfère la campagne (b) : je choisis la campagne
(c) : j’aime la campagne (d) : je déteste la campagne
Les quatre énoncés sont équidistants. Si l’un se trouve dans une classe, nécessairement les trois autres y seront aussi, bien que (d) représente un élément parasite et d'incohérence dans une éventuelle classe.
Exemple 3 :
(a) : les enfants redoutent les voleurs (b) : les gamins craignent les cambrioleurs
Bien qu'ils soient en parfaite relation de paraphrase, les deux énoncés (a) et (b) ne seront jamais dans une même classe car ils n'ont aucun invariant en commun selon la théorie TIAD.
Pour remédier à toutes ces failles, il s’est avéré judicieux d’intégrer un dictionnaire externe de mots synonymes. Ainsi les formes "jouer" et "s'amuser" ne seront scrutées ni à bases différentes, ni à bases égales, mais plutôt à bases synonymes. D’où l’introduction d’une nouvelle matrice de coût, dite Coût de Substitution à bases Synonymes (CSS) dont il suffit que les valeurs soient comprises entre celles de CSE et de CSD.
Conclusion et perspectives
Toujours dans le souci de rendre les classes plus pertinentes, on remarque que dans l'exemple "j'aime voir les collines de la campagne", le verbe modifieur et le verbe dépendant n’ont pas le même apport informatif, en raison de leur niveau dans les arbres syntaxiques ; il en va de même pour le nom centre du SN et le nom du SP attaché au SN. Alors ne serait-il pas judicieux de pondérer les formes aussi en fonction de leurs arborescences syntaxiques ? Ceci nous pousse à penser à évoluer du calcul de distances entre chaînes morphologiques formées de couples (b>t) vers le calcul de distances entre arbres syntaxiques, (Tanaka, 1988) formés des syntagmes du corpus ou représentés en Stemma de L. Tesnière. Ce changement permet de tenir compte aussi bien de la position que de la fonction des formes.
Références
Sellers, Peter, H. (1974). An algorithm for the distance between two finite sequences. Journal of Combinatorial Theory (JCT), Series A, vol. 16, N°2.
Antoniadis, G. (1984). Élaboration d'un Système d'Analyse morpho-syntaxique d'une langue naturelle, application en Informatique Documentaire, Cahiers du CRISS, N°5, pp. 58-100.
Tanaka, E., Tanaka, K. (1988). The tree-to-tree Editing Problem. International Journal of Pattern Recognition and Artificial intelligence, vol. 2, N°2, pp. 221-240.
Lallich-Boidin, G., Rouault, J. (1995). JADT'95 : 4th International Conference on the Statistical Analysis of Textual Data, Rome, pp. 45-54.
Fuchs, C. (1994). Paraphrase et énonciation, Paris : éditions Ophrys, pp. 58-67.
Timimi, I. (1996). L'approximation de l'analyse automatique du discours : modèle 3AD95. CLIM'96 : 1st Student Conference in Computational Linguistics in Montreal, pp. 17-23.
Timimi, I., Rouault, J. (1997). La paraphrase comme relation d'équivalence dans l'analyse automatique du discours, Taln'97, 4ème Conférence annuelle sur le Traitement Automatique du Langage Naturel, INPG-Grenoble, pp. 5-14.