RECHERCHE D'INFORMATION ET CARTOGRAPHIE DANS DES CORPUS TEXTUELS A PARTIR DES FRÉQUENCES DE N-GRAMMES
Alain Lelu*, Mohamed Halleb*, Bruno Delprat**
*Université Paris 8, Département Hypermédias
2 Av. de la Liberté, 93200 Saint Denis
**Supélec, Service des langues et de la communication -
Plateau du Moulon, 91192 Gif sur Yvette
e-mail : lelu@cnam.fr
Abstract
Textual data analysis systems suffer from severe limitations : 1) for scaling up to very large text corpuses, 2) for generalizing to other languages and writing systems. We present here a method for synthetizing large text databases, relying upon a n-grams frequency vectors coding scheme, hence language independant and writing system-independant. Examples are shown in French, Rossian, Chinese and ancient glyphic Maya writing.
1. Introduction
1.1. Rappel
Toute méthode d'analyse de données textuelles se décompose en deux processus principaux :
1) Transformer un ensemble de textes en autant de vecteurs : en règle générale chaque vecteur est constitué par les fréquences de chaque mot du texte, la notion de "mot" pouvant prendre des acceptions diverses - formes lexicales fléchies, c'est-à-dire chaînes de caractères, pour SPAD/T [Lebart, Salem 94], lemmes pour Le Sphinx/Lexica [Baulac 95], formes simples et composées (Lexico),... et mots édités manuellement pour la plupart des logiciels de traitement de questions ouvertes. Cette opération est l'équivalent de l'opération dite d'"indexation" dans notre domaine d'application aux corpus documentaires textuels, où l'attribution de mots aux textes se fait de façon ou bien manuelle, ou bien automatique (le plus souvent par la technique triviale du "texte intégral", ou après lemmatisation par un analyseur morpho-syntaxique).
2) Appliquer à cet ensemble de vecteurs une méthode d'analyse de données choisie par le concepteur, ce qui revient à faire le choix d'une métrique, d'une pondération et d'un algorithme de traitement. Par exemple Alceste [Reinert 86] utilise une classification descendante hiérarchique s'appuyant sur l'analyse factorielle des correspondances (a.f.c.), SPAD/T utilise l'a.f.c. pour une analyse d'ensemble, suivie d'une classification à centres mobiles dans l'espace des premiers facteurs, certains testent des algorithmes plus récents, comme la cartographie associative.
Nous avons nous-même développé une méthode d'analyse, de représentation et de parcours de corpus textuels [Rhissassi, Lelu 97] consistant à appliquer notre algorithme des K-means axiales [Lelu 95] à des vecteurs (transformés et pondérés) de fréquences de lemmes.
1.2. Limites de la représentation de textes par des vecteurs de fréquences de mots :
En ce qui concerne les écritures, le plus souvent occidentales, où les formes des mots sont isolées par des séparateurs triviaux (espace, ponctuation, ...), quand on désire analyser de gros corpus comme ceux désormais présents sur Internet, on tombe de Charybde en Scilla : si on se base sur les formes fléchies (texte intégral), le nombre de celles-ci croît très vite vers plusieurs centaines de milliers, voire millions, pour des corpus importants (par exemple : près de 200 000 pour une année du quotidien Le Monde), et il devient irréaliste d'en tirer des formes composées. Si on se base sur les formes lemmatisées, leur nombre est plus raisonnable, on peut en déduire des formes composées, mais leur extraction est spécifique de chaque langue, et fait appel à des traitements informatiques lourds.
Pour les langues où les formes des mots sont moins évidentes à isoler, comme les langues agglutinantes (turc, russe, allemand dans une moindre mesure), et les écritures asiatiques où seul le contexte permet de séparer les mots, les traitements à appliquer seraient encore plus lourds et spécifiques de chaque langue. Peu de travaux d'analyse de données textuelles existent à notre connaissance dans ces langues.
2. Représentation de textes par des vecteurs de fréquences de n-grammes
Une lignée de travaux s'affranchit de cette notion de mot, donc de toute analyse morpho-syntaxique, qu’elle soit rudimentaire ou élaborée : chaque texte d’un corpus y est caractérisé par le vecteur des fréquences de ses n-grammes, c'est-à-dire de toutes les chaînes de longueur fixe de n caractères qui s’y trouvent.
Cette approche, déjà utilisée pour l’identification de la langue d’un texte ou d’une portion de texte [Greffenstette 95], peut servir de matière première à une analyse exploratoire multidimensionnelle ultérieure de ce corpus - à la condition que n soit suffisamment grand (4 à 6, soit la taille moyenne d'un mot), ce qui implique en pratique que l’espace des trop nombreux n-grammes possibles (Mn si M est la taille de l'alphabet considéré) soit réduit par une technique de hachage. L’expérience a montré [Damashek 95] que le processus d’analyse exploratoire filtrait le bruit engendré par le caractère non univoque de la fonction de hachage et pouvait donner des résultats interprétables.
Pour les langues comme le français et l’anglais, l’avantage, en plus de l’inutilité d’une analyse morpho-syntaxique, est la tolérance aux coquilles et fautes d’orthographe, la prise en compte sans analyse complexe les adjonctions de préfixes et autres constructions fréquentes dans la création de néologismes, ainsi que les formes idiomatiques fléchies ou non. Mais c’est surtout pour les langues agglutinantes (ex : turc, russe) et les écritures asiatiques (chinois, japonais, coréen) où notre notion de mot (en première approximation : unité de sens élémentaire encadrée par des séparateurs triviaux, comme l'espace ou le point), n’existe pas, que la codification de textes sous la forme de vecteurs de fréquences de n-grammes est prometteuse.
La phase d'extraction des différents n-grammes d'un texte est précédée par une phase préliminaire de "réduction" des caractères rencontrés en des caractères choisis par l'utilisateur. Ne pas perdre de n-grammes significatifs tout en minimisant leur nombre est un objectif de base : en français, des séquences de plusieurs espaces consécutifs seront réduites à un seul espace, tous les signes de ponctuation seront reportés sur le point ; celui-ci arrêtera le balayage courant par la fenêtre de n caractères, puis le réinitialisera. Les n-grammes de fréquence faible (1 et 2 pour notre corpus français, soit 46% des occurrences) seront éliminés.
Une fois les n-grammes réduits, une méthode de "hash-coding" sera appliquée (un "hash-code" est une valeur entière affectée à chaque chaîne de caractères, ici de longueur n, et qui constitue son codage). Dans une première phase, nous avons choisi la fonction de hachage suivante : H (n-gramme) = modulo M : S [asc(Ci)]n
i=1,n
où asc(Ci) est le code ASCII du i-ème caractère du n-gramme à coder, et M le nombre maximum de hash-codes différents désiré.
La nature et le nombre de caractères de l’alphabet, la longueur n de la séquence de n-gramme, ainsi que le nombre maximum de hash-codes à retenir sont choisis de façon empirique. Nous avons conservé les caractères accentués du français, reporté les majuscules sur les minuscules, ce qui porte à 56 la taille de notre alphabet, et suivi l'avis de Damashek, qui recommande n=5 pour les langues comme l'anglais ou le français ; 4 a été retenu pour les caractères chinois ("bigrammes" chinois). Afin de limiter le déséquilibre entre nombre de documents et taille des vecteurs descriptifs, on a choisi un nombre de hash-codes égal à 800 pour notre corpus textuel français contenant 320 documents, et 200 pour les corpus chinois, russe et maya, plus restreints. Un filtrage supplémentaire a été effectué sur le corpus français, par élimination des hash-codes dont la répartition est la plus uniforme, sur la base du critère que nous avons dénommé "khi-deux plus", à savoir la part du c2 de chaque hash-code due aux écarts positifs à l'hypothèse d'indépendance (élimination des hash-codes dont le c2+ est inférieur au tiers de sa valeur maximale).
Quelques éléments pour donner une idée des statistiques d'ensemble sur les n-grammes : on a dénombré 64104 5-grammes différents sur notre corpus de 320 documents (706ko). Un autre corpus, de 173 000 caractères et 51 documents, donne lieu à 56 1-grammes différents, 13087 4-grammes, 27460 5-grammes et 45 343 6-grammes. Faute de place, nous ne reproduisons pas le graphique log(rang) vs. log(fréquence) des 5-grammes pour ce corpus, qui confirme la loi d'Estoup/Zipf/Mandelbrot [Lebart, Salem 94] dont l'allure linéaire sur ce graphique est bien connue pour les fréquences de mots.
3. Métrique, poids et algorithme utilisés
La méthode d'analyse exploratoire multidimensionnelle que nous avons choisie, après comparaison [Halleb, Lelu 97] avec celle de Damashek, est celle que nous avons dénommée K-means axiales et avons déjà utilisée à partir des fréquences de mots [Lelu 94]. Rappelons-la brièvement :
Notations : soit un tableau décrivant I documents caractérisés par J h-codes de n-grammes. Un document i comprend les occurrences xij du h-code j. Le nombre total de h-codes de ce document est xi.. Le nombre total d'occurrences du h-code j dans le corpus est x.j.
Les K-means axiales opèrent sur des points-documents normalisés de façon particulière, c'est-à-dire ramenés à la surface de l'hypersphère-unité au moyen de la transformation de chacune de leurs coordonnées ˜(xij/xi.). Chaque point i est pondéré par xi., et l'analyse consiste :
1) à trouver une séparation des documents en K classes maximisant la somme des inerties de chaque classe le long de son axe (dans la variante K-means axiales non adaptatives.
2) à projeter chaque point-document sur l'axe de sa classe
3) à projeter chaque vecteur unitaire des J axes d'origine sur cet axe.
Les K-means axiales possèdent la même propriété d'équivalence distributionnelle que l'analyse factorielle des correspondances, ainsi que, au niveau local de chaque classe, la propriété de dualité. La prise en compte des données négatives est possible, contrairement aux méthodes opérant sur le simplexe. Cette méthode équivaut formellement à un réseau de K neurones dotés d'une fonction de transfert et d'une loi d'apprentissage simples, et les classes peuvent être visualisées dans deux dimensions sur une carte globale au moyen d'une analyse en composantes principales sur les profils des classes [Lelu 95], ou de toute méthode de "dépliage" non-linéaire.
Toutefois nous avons constaté empiriquement une amélioration des résultats, à savoir une diminution de l'importance des n-grammes correspondant à des mots grammaticaux et une conformité plus étroite avec les classes à base de de lemmes, en utilisant la métrique Diag(1/x.j), proche de la "pondération par l'inverse des nombres de documents" (i.d.f. en anglais) bien connue dans le monde de la documentation.
Par comparaison, dans la méthode décrite par [Damashek 95] chaque document i est ramené à son profil relatif xij/xi. d'occurrences de h-codes. On peut le représenter par un point dans le simplexe, c'est-à-dire dans l'hyperplan lieu des points i dont la somme des coordonnées Sj xij est égale à 1. Chaque point pèse le même poids, et la classification est effectuée sur les vecteurs-différence : profil relatif - profil moyen relatif, dont les coordonnées s'écrivent, pour le i-ème vecteur : xij/xi. - xj./x.. .
4. Expérience sur un corpus en alphabet latin : 320 biographies en français extraites du dictionnaire "Maîtron".
Nos expériences de classification ont porté sur une base documentaire de 706 ko contenant 320 documents, dont la taille varie entre 430 et 11800 caractères. Ces textes sont issus du dictionnaire "Maitron" (dictionnaire biographique du mouvement ouvrier) avec l'aimable autorisation des historiens du CRHMMS qui en assurent la réalisation. Les 6 thèmes principaux dégagés à partir de notre méthode basée sur des vecteurs de mots sont les suivants : congrès socialistes, élus socialistes, anarchistes, l'Internationale, syndicats, mouvement coopératif.
La classification issue de l'application de notre algorithme K-means axiales itératives sur des données produites à partir des n-grammes montre six thèmes distincts, souvent proches angulairement. Ceci est dû au fait que les documents du corpus sont souvent multi-thématiques, c'est-à-dire traitent de plusieurs sujets différents, liés chacun à un thème différent.
Les tableaux 1 et 2 représentent la liste ordonnée des n-grammes correspondants aux mots les plus significatifs des deux classes "anarchistes" et "l'Internationale" avec leur rang dans la liste complète des n-grammes de chaque classe, et leur degré de pertinence (somme de leurs nombres d'occurrences dans chaque document de la classe pondérés par la centralité du document). Ces mots sont voisins de ceux dégagés par l'autre approche. Il est à noter que les premiers n-grammes de toutes les classes correspondent à des mots grammaticaux - ce qui montre une forte relation entre la "forme" et le "fond" - mais que cela n'empêche pas un recouvrement de 32 documents communs sur 54 de la classe "anarchistes", et 46 sur 93 pour "l'Internationale" : les classes obtenues par les deux méthodes sont très proches, d'autant plus proches que, dans les méthodes à centres mobiles, la variabilité due au paramétrage de l'initialisation représente une part non négligeable de ce non-recouvrement (inférieur à 50%).
Après examen des 4 autres classes, il ressort que l'interprétation des axes relatifs aux six classes retenues, c'est-à-dire aux thèmes traités dans le corpus, semble aussi claire avec la méthode des n-grammes qu'avec nos méthodes à base de mots.
|
rang |
Ngr |
Mot |
Pertinence |
|
38,40,47,53,54,64,65 ,64, , |
soci |
socialiste |
1034 |
|
72,83,104 |
Paris |
Paris |
739 |
|
78 |
unine |
bakounine |
670 |
|
79,94,200 |
cont |
contre |
669 |
|
81 |
le 1 |
le 1 |
656 |
|
82,114,132,140,166 |
uvrie |
ouvrier |
643 |
|
84,106,109,113,170,177 |
cong |
congrès |
637 |
|
91 |
le 2 |
le 2 |
602 |
|
92,103,121,136,197,198,212 |
anarc |
anarchiste |
592 |
|
93,95,96,152 |
part |
parti |
592 |
|
108,111,123,125,128,131,135,147 |
ialis |
socialistes |
504 |
|
126,211 |
grou |
groupe |
457 |
|
143,213 |
guer |
guerre |
401 |
|
145,151,199 |
aint |
saint |
395 |
|
156,178,180,216, |
anarc |
anarchistes |
367 |
|
157,161,168,187,193,195,196 |
dérat |
fédération |
363 |
|
169,188,201,226 |
taire |
secrétaire |
348 |
Figure 1
|
rang |
Ngr |
Mot |
Pertinence |
|
21,22,24,26,27,29,34,45 |
soci |
socialiste |
3773 |
|
43,48,52,55,69,123,140,168,209,230 |
congr |
congrès |
2701 |
|
67,83 |
cont |
contre |
1933 |
|
75,80,92,191,200 |
part |
parti |
1810 |
|
84,93,110,116,121,136,127,129,130,202 |
ation |
fédération |
1680 |
|
94,118,173 |
Paris |
Paris |
1581 |
|
95,96,97,101,102,104,105,112,227 |
soci |
socialistes |
1575 |
|
108 |
le 1 |
le 1 |
1420 |
|
113,142,203 |
tion |
action |
1407 |
|
117,124,138,141 |
polit |
politique |
1338 |
|
126,135,149,158,163,193,225 |
ation |
internationale |
1227 |
|
143,165,214 |
sore |
Sorel |
1037 |
|
147 |
uvrie |
ouvrier |
1011 |
|
148,150,152,,161,162,175 |
ialis |
socialisme |
1009 |
|
153,180,233 |
ment |
mouvement |
971 |
|
155 |
i soc |
Parti socialiste |
968 |
|
156 |
voix |
voix |
965 |
Figure 2
5. Expériences sur des corpus en écritures non latines : russe, chinois et maya.
Les expérimentations ont porté sur 3 ensembles de segments de texte :
- un en russe (contenant 113 segments, total de 11600 caractères cyrilliques ou 2000 mots de russe) extrait de la version électronique du guide de l'utilisateur du correcteur orthographique JHaJ (ORFO) [Byajhvfnbr 94] et qui présente une grande homogénéité de contenu. La table de caractères russes utilisée comprend les 32 lettres de l'alphabet russe moderne plus les caractères latins non accentués.
- un en caractères chinois (contenant 31 segments, total de 650 caractères chinois, codés en 650x2 octets) extrait de la plaquette de présentation [Metaleurop 94] du groupe industriel métallurgique Metaleurop. Le texte est d'un contenu assez varié, constitue un corpus limité mais adapté à de premiers essais d'adaptation de nos programmes à des systémes d'écriture dont le codage informatique de chaque signe se fait sur plusieurs octets. La norme informatique suivie est ISO-IR-65:1992 (comprend GB 2312-80 de la République Populaire de Chine) qui code plus de 8400 caractères chinois.
- un en glyphes mayas (contenant 30 segments, total de 303 formes glyphiques de base, composant 111 glyphes de texte en tout) compilation d'extraits déchiffrés de façon raisonnablement fiable [Knorozov 55] des Codex de Dresde et Madrid, livres sacrés des Mayas du Yucatán, almanachs divinatoires décrivant les activités de l'homme et leurs rapports avec les dieux. Comme pour le chinois, le corpus est limité, mais présente une large variété de contenus. Nous avons suivi l'édition critique des Codex et le codage informatique par numéros à 3 chiffres du catalogue [Tdhtbyjd, Rjcfhtd, et al. 61] de 617 formes glyphiques, réalisés par Evreinov de l'Académie de Sciences de Novosibirsk lors d'une première tentative d'application de l'informatique au déchiffrement de l'écriture maya.
5.1. Expérience sur un corpus russe en alphabet cyrillique
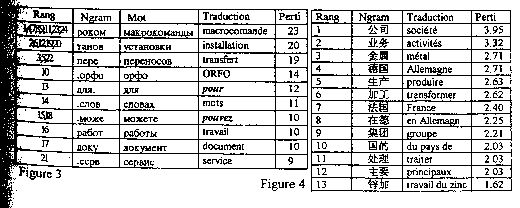
Les mots correspondants aux n-grammes de pertinence les plus élevés ne sont pas en russe, comme c'est le cas en français, des mots grammaticaux, mais à plus de 90% des termes caractéristiques du contenu du corpus, et ce quels que soient les paramètres choisis : 4 ou 5 classes, 5 ou 6-grammes, données brutes, pondération, filtrage, etc.
La figure 3, pour une expérience en données brutes avec 5-grammes et 4 classes, donne les 24 premiers mots selon l'ordre de pertinence décroissante : seuls 2 sont grammaticaux ou non signifiants. La méthode nous affranchit du bruit grammatical presque totalement dans le cas du russe. C'est également une observation valable pour le chinois et le maya.
5.2. Expérience sur un texte en caractères chinois
On constate, pour toutes les expériences et tous les axes, que le haut des listes de bigrammes chinois 1) ne comprennent quasiment pas de mots grammaticaux, 2) contiennent des bigrammes correspondant à des mots bi-syllabiques (en chinois moderne, les mots sont généralement bi-syllabiques et s'écrivent sur deux caractères chinois). La méthode rejette donc en queue d'axes les bigrammes à cheval sur deux mots et dépourvus de sens (cf. figure 4).
Les angles entre axes de classes sont élevés (28° à 41°), ce qui traduit des thématiques bien distinctes, mais parmi les 10 premiers bigrammes de chaque axe, seuls 30% ne se retrouvent pas sur les axes voisins ; il faut descendre plus bas pour différencier plus nettement le sens des classes, sens corroboré par le contenu des phrases correspondantes.
L'axe de la figure 4, interprétable comme "Métaleurop : géographie de la production" a été obtenu à partir de données brutes, et la signification des autres classes est la suivante : "Techniques et types de production des métaux spéciaux", et "Métaleurop : structure et organisation".
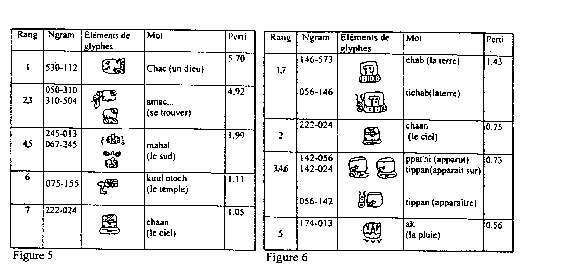
5.3. Expérience sur des extraits de textes en glyphes mayas
C'est pour notre plus petit corpus que nous avons obtenu les angles les plus élevés (55° à 78°). Un glyphe maya correspond à peu près à un concept, et comprend 1 à 6 éléments de base (formes glyphiques). Les associations de formes visibles sur les axes obtenus traduisent des concepts valides : l'axe 1 traduit l'association entre le dieu Chac, le Sud et le temple (figure 5) ; la classe 2 associe la femme et divers totems ; la classe 3 (figure 6) correspond à un autre aspect de la cosmogonie maya : la pluie apparaît sur la terre.
A titre d'illustration, voici la traduction en espagnol [Knorozov 1955] des 3 extraits les plus saillants de la classe correspondant à la figure 5 :
1. Chac se encontraba en el arbol amarillo en el Sur.
2. Chac Amarillo se encontraba en el Sur.
3. Chac Negro se encontraba en el Oeste.
Bien que des glyphes identiques ne se retrouvent pas souvent dans le corpus (4 fois au plus dans nos extraits), les associations obtenues sont cohérentes, résultat est d'autant plus intéressant que les sources en langue maya sont peu abondantes (autodafé des codex...).
5.4. Perspectives d'utilisation
Ces trois expériences ne sont que de premiers essais d'utilisation de la méthode aux langues non écrites en caractères latins. Les résultats obtenus, d'une qualité équivalente à celle pour un corpus français, nous permettront maintenant de passer à l'analyse de textes d'une longueur plus réaliste, pour des corpus de documents plus importants.
Dans le cas du chinois et du russe, notre but sera d'analyser des textes issus d'Internet, dans le cadre d'un éventuel moteur de recherche multilingue et multi-écritures.
Pour le maya, nous souhaitons appliquer la méthode au déchiffrement des glyphes des Codex, nombreux, qui ne sont pas lus ou dont la lecture reste très incertaine. En particulier, par la mise en parallèle des analyses des Codex avec celles des textes de même nature, en maya yucatèque romanisé d'après la conquête, des prophéties du Chilam Balam.
Références
Baulac, Y. (1995). Exploration de données textuelles avec le SPHINX. In Bolasco S., Lebart L., Salem A. (eds.) JADT 1995. Rome : CISU, II, 73-82.
Damashek, M. (1995). Gauging Similarity with n-Grams : Language-Independent Categorization of Text. Science, 267, 843-848.
Greffenstette, G. (1995). Comparing two language identification schemes. In Bolasco S., Lebart L., Salem A. (eds.) JADT 1995. Rome : CISU, I, 263-268.
Halleb, M., Lelu, A. (1997). Hypertextualisation automatique multilingue à partir des fréquences de n-grammes. In Balpe J.P. et al. (eds.) H2PTM'97. Paris : Hermès, 275-287.
Lebart, L., Salem, A. (1994). Statistique textuelle. Paris : Dunod.
Lelu, A. (1994). Clusters and factors : neural algorithms for a novel representation of huge and highly multidimensional data sets. In Diday E., Lechevallier Y. & al. (eds.) New Approaches in Classification and Data Analysis. Berlin : Springer-Verlag, 241-248.
Lelu, A. (1995). Hypertextes : la voie de l'analyse des données. In Bolasco S., Lebart L., Salem A. (eds.) JADT 1995. Rome : CISU, II, 85-96.
Reinert, M. (1986). Un logiciel d'analyse des données textuelles : ALCESTE. Cahiers de l'analyse des données. (a) ; 4 ; 471-484.
Références relatives aux exemples de textes en écritures non latines