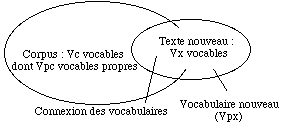
LA CONNEXION DES VOCABULAIRES
|
Dominique Labbé CERAT-IEP, BP 45, F 38402 Saint Martin-d'Hères Cedex email : cerat@iep.upmf-grenoble.fr |
Pierre Hubert Ecole Nationale Supérieure des Mines de Paris - Centre d'Informatique Géologique 77.305 Fontainebleau Cédex email : hubert@cig.ensemp.fr |
Summary
The "vocabulary connection" analyses similarity between vocabularies of several texts. Firstly, we calculate the theoretical size of commun vocabulary and the number of peculiar words that each text should have if they were all from the works of one author. Secondly, we count the specific words actually appearing in each text. The "index of texts vocabularies connection" is the ratio between theoritical number and actually observed values. It measures the degree of similarity of one text compared to the others. Applied to the plays of Corneille and Racine, this calculation shows that – except in the two last Racine's tragedies – the vocabularies are very similar. This example suggests that vocabulary differences do probably not fit well to authorship attribution.
La comparaison d'un corpus connu et déjà dépouillé avec un texte nouveau – que son auteur soit ou non identifié comme étant celui du corpus de référence – est un problème classique de la statistique lexicale. A quelles conditions, peut-on affirmer que le second s'écarte significativement du premier ou, à l'inverse, qu'ils appartiennent probablement à un même ensemble ? L'une des manières les plus classiques d'aborder le problème consiste à se demander quelle proportion du vocabulaire de l'un doit se retrouver dans l'autre. Il y a trente ans, C. Muller avait donné une première réponse avec la notion de "connexion lexicale" (C. Muller, 1967 et 1977) mais la voie ainsi ouverte n'a guère été explorée après lui. Nous proposons ci-dessous le calcul d'un indice mesurant la proximité des vocabulaires à partir d'une démarche inspirée des travaux de C. Muller. Puis nous exposons les résultats obtenus sur le théâtre de Racine et de Corneille.
Calcul de la connexion des vocabulaires
On pose que le corpus (C) de référence contient Nc mots dont Vc vocables différents et le texte discuté (X) : Nx mots dont Vx vocables différents. Et l'on accepte l'hypothèse selon laquelle le vocabulaire des deux textes est apparenté. Leur réunion comptera N mots (Nc + Nx) et V mots différents dont Vi de fréquence i. Ce vocabulaire total peut être décomposé en cinq sous-ensembles :
Quelle devrait être la taille de chacun des sous-ensembles si l'hypothèse d'une oeuvre unique est exacte ? La démarche suggérée par C. Muller consiste à considérer que, dans le cas d'une oeuvre unique, tout doit se passer comme si le corpus et le texte discuté résultaient de tirages successifs et exhaustifs, de Nc puis Nx mots, au sein d'une seule urne dont le contenu N sera épuisé avec le dernier tirage. Dans ce cas, la probabilité pour qu'un mot de fréquence f dans N apparaisse f ' fois dans l'un de ces sous-ensembles contenant N' mots, s'écrit :
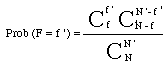
Un cas intéresse tout particulièrement les analystes : celui des mots "nouveaux" apportés par le texte X (Vpx ou "vocabulaire propre à X"). C'est l'une des pistes privilégiées dans l'attribution d'auteur (voir à ce sujet le travail classique de R. Thisted et B. Efon, 1987, discuté par L. Lebart et A. Salem, 1994. Et pour une revue d'ensemble du problème de l'attribution d'auteurs : D. Holmes, 1994). Dans le cas d'un mot absent dans le corpus connu (Nc, f '=0), tout en ayant une fréquence de f dans Nx (et donc dans N), la formule ci-dessus s'écrit :
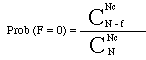
![]() En tenant compte de ce que Nx = N - Nc et en posant u = , il vient :
En tenant compte de ce que Nx = N - Nc et en posant u = , il vient :
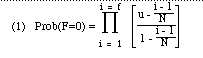 Dans un corpus en langue naturelle, quelle que soit f, nous aurons toujours : N>>f. La valeur sera donc toujours très petite et l'on commettra une erreur négligeable en la supprimant (démonstration dans P. Hubert - D. Labbé, 1988a). Ce qui permet de substituer à (1), l'expression suivante, que nous noterons Pf(u) :
Dans un corpus en langue naturelle, quelle que soit f, nous aurons toujours : N>>f. La valeur sera donc toujours très petite et l'on commettra une erreur négligeable en la supprimant (démonstration dans P. Hubert - D. Labbé, 1988a). Ce qui permet de substituer à (1), l'expression suivante, que nous noterons Pf(u) :
![]() Sachant qu'il y a, dans N, Vi vocables de fréquence i, l'effectif attendu des mots nouveaux de fréquence i dans Nx sera donc : Vi * ui. En réitérant ce calcul sur les n classes de fréquences de V, le total des mots nouveaux attendus dans le texte discuté sera :
Sachant qu'il y a, dans N, Vi vocables de fréquence i, l'effectif attendu des mots nouveaux de fréquence i dans Nx sera donc : Vi * ui. En réitérant ce calcul sur les n classes de fréquences de V, le total des mots nouveaux attendus dans le texte discuté sera :
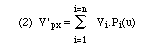 On pourra alors comparer cette valeur théorique avec le nombre réel de vocables neufs apportés par le texte (Vpx), ce qui permet de mesurer l'écart entre les valeurs attendues et celles effectivement constatées.
On pourra alors comparer cette valeur théorique avec le nombre réel de vocables neufs apportés par le texte (Vpx), ce qui permet de mesurer l'écart entre les valeurs attendues et celles effectivement constatées.
Puisque le raisonnement est probabiliste, il est logique d'associer à Vpx une variance théorique :
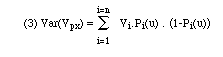 L'" indice d'écart normalisé et réduit " s'écrira :
L'" indice d'écart normalisé et réduit " s'écrira :
![]() En acceptant un risque d'erreur inférieur à 5%, trois situations sont envisageables.
En acceptant un risque d'erreur inférieur à 5%, trois situations sont envisageables.
Un indice inférieur à -2 indique que le vocabulaire de X est significativement très proche de C, plus proche que le laisserait attendre la diversité moyenne dans C. Dans ce cas, on devrait conclure que X appartient au même univers que C et, si X est d'un auteur inconnu, qu'ils sont probablement de la même main. Si l'indice est compris entre ± 2, il n'y a pas de rupture significative entre X et C : on ne peut rejeter l'hypothèse selon laquelle les textes appartiennent à une même oeuvre. Si l'indice est supérieur à 2, ce qui est assez fréquent, les conclusions sont plus difficiles à tirer comme nous le verrons plus loin.
Ce calcul appelle un certain nombre de remarques préalables.
1. Il est évident que le raisonnement n'est valable que lorsque la taille du corpus est nettement supérieure à celle du texte discuté (afin que la fusion des deux ne modifie pas sensiblement la structure de la distribution des fréquences par rapport à celle du corpus). D'ailleurs, lorsque Nc>>Nx, l'utilisation de la distribution des fréquences de Nc pour le calcul donne une bonne approximation de V'px (avec une sous-estimation d'autant plus faible que Nc sera grand par rapport à Nx). En tout état de cause, l'expérience ne peut être menée que sur de vastes corpus, comprenant au minimum plusieurs dizaines de milliers de mots, comparés à des textes de faible étendue relative par rapport à N.
2. Le raisonnement repose sur le postulat d'une urne unique : tous les mots ont la même probabilité d'occurrence en n'importe quel point du corpus. Sauf dans des textes peu étendus et possédant une unité thématique – ou une forte dose de généralité –, cette manière de voir n'est pas recevable. Dans un corpus de grande taille, même avec un auteur unique, il existe une certaine spécialisation du vocabulaire. Cette spécialisation peut être estimée grâce au modèle de partition du vocabulaire (P. Hubert - D. Labbé, 1988b). En notant p la proportion des vocables "spécialisés" dans le corpus et, avec l'hypothèse que cette spécialisation est également en oeuvre dans le texte discuté, la formule (2) devient :
![]() Le vocabulaire spécialisée est une fonction linéaire de N. Le raisonnement " probabiliste " ne porte plus que sur le vocabulaire général (second membre de (4) ). On peut donc restreindre le calcul de la variance à ce seul vocabulaire général. La formule (3) devient :
Le vocabulaire spécialisée est une fonction linéaire de N. Le raisonnement " probabiliste " ne porte plus que sur le vocabulaire général (second membre de (4) ). On peut donc restreindre le calcul de la variance à ce seul vocabulaire général. La formule (3) devient :
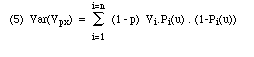 3. Le raisonnement suppose que, quelle que soit f, nous avons toujours Nx>f. En effet, dans le cas contraire, le vocable sera nécessairement présent dans Nc et Prob(F=0) sera rigoureusement nulle. En toute rigueur, il faut donc arrêter le calcul à la dernière classe des vocables dont la fréquence est immédiatement inférieure à Nx. Soit "limf" cette valeur : dans les formules (2) à (5), on pourra substituer "limf" à "n". En pratique, les itérations n'ont pas besoin d'être poussées aussi loin car les effectifs concernés sont extrêmement faibles et les valeurs de uf deviennent vite infinitésimales.
3. Le raisonnement suppose que, quelle que soit f, nous avons toujours Nx>f. En effet, dans le cas contraire, le vocable sera nécessairement présent dans Nc et Prob(F=0) sera rigoureusement nulle. En toute rigueur, il faut donc arrêter le calcul à la dernière classe des vocables dont la fréquence est immédiatement inférieure à Nx. Soit "limf" cette valeur : dans les formules (2) à (5), on pourra substituer "limf" à "n". En pratique, les itérations n'ont pas besoin d'être poussées aussi loin car les effectifs concernés sont extrêmement faibles et les valeurs de uf deviennent vite infinitésimales.
4. L'indice est évidemment très sensible au surgissement de quelques mots rares ou exotiques. Ceux-ci peuvent augmenter significativement le nombre des mots " nouveaux " mais, comme ce sont généralement des hapax, leur poids dans N reste négligeable. On peut donc préférer considérer les surfaces de texte concernées par la connexion et par l'écart entre les vocabulaires. Pour obtenir les valeurs théoriques, on pourrait pondérer, dans les formules (4) et (5), les effectifs théoriques de chaque classe de fréquence (V'i) par la fréquence Fi. Cependant les résultats obtenus sont relativement médiocres. D'autres voies devront donc être imaginées pour considérer non plus la connexion des vocabulaires mais le recouvrement des textes.
Application
La validité du raisonnement sera testée sur un corpus appartenant avec certitude à un seul auteur et à un même genre littéraire : les onze tragédies de Racine (ce corpus est présenté par C. Bernet, 1983) et sa comédie (Les plaideurs). Ces textes ont été dépouillés selon la norme dite " C. Muller ". On trouvera dans le tableau 1 ci-dessous, la connexion lexicale existant entre ces oeuvres puis les valeurs théoriques, l'écart type et l'écart normalisé calculées avec les formules (4) et (5) pour chaque tragédie comparée aux dix autres prises ensemble comme corpus de référence.
La dernière ligne permet de constater que le total des valeurs calculées excède très légèrement la somme des valeurs observées (écart inférieur à 2,5%). Cette relative précision d'ensemble suggère que le modèle s'ajuste assez bien au phénomène à décrire ou, du moins, à sa tendance générale mesurée sur l'ensemble du corpus grâce au modèle de partition du vocabulaire. En effet, dans le détail, on constate des écarts considérables entre les valeurs calculées et les valeurs attendues. D'une part, Les plaideurs n'appartient manifestement pas au même univers que les onze autres : près de 40% du vocabulaire de cette pièce ne se retrouve pas ailleurs dans l'oeuvre, ce qui est considérable. Ce premier constat montre l'importance du genre dans la structure du vocabulaire : la comédie et la tragédie n'utilisent pas les mêmes mots. Ce constat avait déjà été fait par C. Muller et E. Brunet (1988). Mais les tragédies elles-mêmes présentent toutes des écarts significatifs par rapport aux valeurs attendues. C'est le cas notamment des deux dernières qui, ensemble possèdent un vocabulaire très décalé par rapport au reste de l'oeuvre, Phèdre se situant manifestement à mi-chemin.
Tableau 1. Vocabulaire propre à chaque pièce dans l'oeuvre de Racine.
Valeurs observées (Vp) et calculées (Vp').
|
|
Nx |
Vx |
Vp |
Vp' |
Ecart-type |
Ecart normalisé |
|
1. Thébaïde (1664)* |
13 813 |
1 313 |
69 |
147 |
7,35 |
-5,31 |
|
2. Alexandre (1665)* |
13 864 |
1 372 |
70 |
148 |
7,37 |
-5,29 |
|
3.Andromaque (1667)* |
15 076 |
1 392 |
62 |
162 |
7,65 |
-6,54 |
|
4. Britannicus (1669)* |
15 387 |
1 637 |
126 |
165 |
7,22 |
-2,70 |
|
5. Bérénice (1670)* |
13 343 |
1 346 |
58 |
141 |
7,22 |
-5,75 |
|
6. Bazajet (1672)* |
15 297 |
1 507 |
81 |
164 |
7,70 |
-5,39 |
|
7. Mithridate (1673)* |
15 091 |
1 550 |
71 |
161 |
7,65 |
-5,88 |
|
8. Iphigénie (1674)* |
15 782 |
1 604 |
88 |
169 |
7,59 |
-5,34 |
|
9. Phèdre (1677)* |
14 394 |
1 931 |
190 |
154 |
7,49 |
2,47 |
|
10. Esther (1689)* |
11 147 |
1 353 |
157 |
118 |
6,67 |
2,92 |
|
11. Athalie (1691)* |
15 492 |
1 877 |
250 |
166 |
7,74 |
5,43 |
|
Esther+Athalie** |
26 639 |
2 381 |
478 |
325 |
9,25 |
8,27 |
|
Plaideurs (1668)*** |
8 041 |
1 312 |
513 |
98 |
6,50 |
31,92 |
|
Total 12 pièces |
166 727 |
4 322 |
1 736 |
1 793 |
|
|
* Le corpus de référence est constitué des dix autres tragédies à l'exclusion des Plaideurs (p=0,334).
** le corpus est constitué des neuf premières tragédies (131.946 mots, 3.349 vocables, p=0,312).
*** le corpus de référence est constitué des 11 tragédies (158.585 mots, 3.814 vocables, P=0,257).
Le tableau 1 suggère donc l'existence de deux sous-ensembles. Pour vérifier leur homogénéité relative, on a repris le calcul en constituant un corpus de référence constitué des 8 premières pièces : dans cet ensemble, les écarts entre les valeurs théoriques et les valeurs attendues se situent dans l'intervalle ± 2 confirmant ainsi ce qu'avaient déjà noté les critiques à propos de la césure entre les pièces " profanes " et les pièces " sacrées " de Racine, Phèdre occupant une place à part.
A l'époque où Racine (1639-1699) écrit ses premières tragédies – la première représentation de La thébaïde date de 1664 –, les oeuvres de Corneille (1606-1684) dominent le théâtre classique (présentation d'ensemble dans C. Muller, 1967). Il est donc logique d'étudier la connexion existant entre le vocabulaire les deux hommes (tableau 2). Le corpus de référence est constitué des six tragédies qui ont assuré la célébrité de Corneille. On compare successivement les onze pièces de Racine à ce corpus. La dernière ligne du tableau 2 indique que le modèle sous-estime nettement l'écart entre les vocabulaires (d'un cinquième environ). Ce constat est logique et confirme globalement l'existence de deux auteurs différents. Mais l'écart provient uniquement des trois dernières pièces de Racine : Phèdre, Esther et Athalie. En revanche, pour les tragédies profanes, seul Britannicus fait apparaître un écart significatif. Toutes les autres se situent en-deçà du seuil de 2. Curieusement même, le calcul surestime plutôt les valeurs attendues ce qui souligne la forte identité existant entre le vocabulaire du Corneille classique et celui du premier Racine (cette identité tient sans doute en partie au fait que les lieux, les personnages et les thèmes traités sont souvent les mêmes).
Tableau 2. Connexion entre le vocabulaire des tragédies de Racine
et celles de Corneille*.
|
|
Vp |
Vp' |
Ecart-type |
Ecart normalisé |
|
1. Thébaïde (1664) |
94 |
156 |
11,16 |
-2,78 |
|
2. Alexandre (1665) |
114 |
157 |
11,17 |
-1,92 |
|
3. Andromaque (1667) |
126 |
172 |
11,57 |
-1,99 |
|
4. Britannicus (1668) |
236 |
176 |
11,66 |
2,57 |
|
5. Bérénice (1670) |
130 |
149 |
10,96 |
-0,87 |
|
6. Bazajet (1672) |
173 |
174 |
11,63 |
-0,04 |
|
7. Mithridate (1673) |
158 |
172 |
11,57 |
-0,61 |
|
8. Iphigénie (1674) |
229 |
180 |
11,78 |
2,08 |
|
9. Phèdre (1677) |
294 |
163 |
11,35 |
5,77 |
|
10. Esther (1689) |
295 |
124 |
10,18 |
8,40 |
|
11. Athalie (1691) |
398 |
177 |
11,69 |
9,45 |
|
Total 11 pièces |
2 247 |
1 800 |
|
|
* Le corpus de référence est constitué de : Médée (1635), Le Cid (1637), Horace (1641), Cinna (1642), Polyeucte (1643), et Pompée (1644), soit au total : 96.518 mots, 3.507 vocables. Dans ce corpus, la spécialisation du vocabulaire est nulle (p=0).
En définitive, cette expérience amène quelques conclusions paradoxales. En effet, si nous ignorions les auteurs de ces pièces, nous serions amenés à attribuer à Corneille sept des huit premières tragédies de Racine tout en affirmant que, pour les trois autres, leur diversité semble si grande qu'elles n'ont probablement pas le même auteur. Toutes conclusions qui seraient évidemment fausses…
Autrement dit, jusqu'à Phèdre, le vocabulaire de Racine ne se distingue pas de celui de Corneille (à vingt ans de distance). Loin de s'accompagner de l'apparition d'un vocabulaire nouveau, la démolition du héros cornélien se fait avec les mots mêmes qui avaient servi à le magnifier. Mieux : Racine mène l'entreprise en portant à sa perfection la versification et le dépouillement des effets qui font de ses pièces l'apogée du théâtre classique régulier. Il est vrai que chez Corneille, déjà, l'amour de la gloire conduit régulièrement le héros à l'impasse (S. Doubrovsky, 1963) mais, pour Racine comme chez Cervantès, les passions héroïques ne sont que des errements ridicules et dégradants, voire dévastateurs et démentiels. Sans doute, était-il trop tôt pour substituer ouvertement l'idéal individualiste des lumières aux valeurs aristocratiques moribondes. Il ne restait donc que la crainte de la colère divine et la foi janséniste en la prédestination qui sont les thèmes dominants d'Esther et d'Athalie dont l'analyse statistique souligne l'étrangeté par rapport au reste du théâtre classique (pour le vocabulaire caractéristique de ces pièces, cf. C. Bernet, 1983).
Cette expérience amène deux conclusions plus générales :
– même lorsqu'il s'agit d'un seul auteur, on ne peut prévoir le nombre de mots nouveaux qu'un texte supplémentaire apportera à son oeuvre. Cette première conclusion n'est pas vraiment une surprise : puisque, dans la plupart des grands corpus connus, la croissance du vocabulaire est irrégulière – en ce sens que les fluctuations dans l'apparition des mots nouveaux dépassent ce que l'on peut raisonnablement attribuer au hasard –, l'ajout d'un texte supplémentaire reproduit cette irrégularité même si l'auteur ne change pas de genre et écrit avec les mêmes procédés littéraires. Les tragédies de Racine en fournissent une illustration éclatante…
– en conséquence, le décompte des " mots nouveaux " ou des " mots absents " n'est probablement pas le bon outil pour attribuer des textes inconnus ou douteux à des auteurs connus. Cette seconde conclusion est importante car une bonne partie des travaux classiques sur l'attribution d'auteur empruntent cette piste de recherche. Il est vrai que l'attribution d'auteur semble une question à la fois triviale et insoluble. Elle pose cependant une question intéressante : quels sont les invariants du vocabulaire et du style d'un auteur ?
En revanche, cette application suggère que le chiffrage de la connexion lexicale peut être utile pour la connaissance d'une oeuvre, du style d'un auteur et, au-delà, du vocabulaire d'un genre ou d'une époque.
Références
Bernet, Ch. (1983). Le vocabulaire des tragédies de Racine, Genève-Paris : Slatkine-Champion.
Brunet, E., Muller, Ch. (1988). " La statistique résout-elle les problèmes d'attribution ? ", Strumenti criticci, Sett., 1988, pp. 367-387.
Doubrovsky, S. 1963. Corneille et la dialectique du héros, Paris : Gallimard.
Holmes, D. I. (1994). " Authorship Attribution ", Computers and the Humanities, 28, pp. 1-20.
Hubert, P., Labbé, D. (1998a). " Note sur l'approximation de la loi hypergéométrique par la formule de Muller " in Labbé D., Thoiron P., Serant D. dir., Études sur la richesse et la structure lexicales, Genève-Paris : Slatkine-Champion.
Hubert, P., Labbé, D. (1988b). " Un modèle de partition du vocabulaire ", in Labbé D., Thoiron, P., Serant, D. dir., Études sur la richesse et la structure lexicales, Genève-Paris : Slatkine-Champion.
Lebart, L., Salem, A. (1994). Statistique textuelle, Paris : Dunod.
Muller, Ch. (1967). Étude de statistique lexicale, Paris : Larousse.
Muller, Ch. (1977). Principes et méthodes de statistique textuelle, Paris : Hachette
Thisted, R., Efon, B. (1987). " Did Shakespeare write a newly discovered poem ? ", Biometrika, 74, pp. 445-455.