proximités de comportement syntaxique entre les mots
|
Helka Folch |
Benoît Habert |
|
DER-EDF 1 avenue du Général de Gaulle, 92141 Clamart Cédex {folch,bh}@ens-fcl.fr |
ELI - ENS Fontenay St Cloud 31 avenue Lombart, 92260 Fontenay-aux-Roses {folch,bh}@ens-fcl.fr |
Résumé
Par leur diversité, les arbres fournis par les analyseurs syntaxiques robustes actuels résistent au comptage, alors même qu’ils fournissent des renseignements quantitatifs précieux sur le fonctionnement en discours des mots : place privilégiée comme opérateur, comme opérande, schémas syntaxiques préférentiels, etc. Nous utilisons une représentation logique pour définir avec précision certaines des relations qu’entretiennent les mots dans les arbres. Nous utilisons ensuite la classification automatique pour regrouper les mots qui ont des comportements syntaxiques proches. Nous montrons l’ensemble de la chaîne de traitement réalisée sur un jeu restreint de relations et un corpus de langue médicale.
1. Des contextes aux classes sémantiques propres à un corpus
Dans l’optique de donner un accès plus immédiat au "sens" des textes, de nombreux travaux, depuis une dizaine d'années, ont été consacrés à l'acquisition automatique des catégories sémantiques propres à un corpus ou à un domaine. Grefenstette (1994a) fournit un panorama de ces recherches. Cette acquisition se décompose généralement en trois étapes, selon Grefenstette (1994b). La première étape est l'extraction des cooccurrents de chaque mot. La seconde établit une distance entre les mots deux à deux en fonction des cooccurrents qu'ils partagent. La troisième regroupe les mots en catégories en fonction des distances observées à l'étape précédente. A chaque étape de cette acquisition sémantique automatique, les techniques employées varient.
Dans (Bouaud et al., 1997), nous avons appliqué une variante de cette démarche générale au corpus Menelas. Ce corpus a été rassemblé dans le cadre d’un projet de compréhension automatique de comptes rendus d’hospitalisation dans le domaine des maladies coronariennes (Zweigenbaum, 1994). Il se compose d’un extrait de manuel, de comptes rendus d’hospitalisation et de lettres de médecins hospitaliers aux médecins traitants. Il comprend 84 839 occurrences et 6 191 formes.
Les cooccurrents d'un mot peuvent être les mots qui apparaissent dans une fenêtre graphique constituée par les k mots avant et après le mot considéré. Dans la phrase suivante de Menelas : "Une sténose serrée du tronc coronaire gauche est responsable de l’angor d’effort", les cooccurrents de tronc, avec k = 4, forment l'ensemble : {une, sténose, serrée, du, coronaire, gauche, est, responsable}. Pour le logiciel dont nous nous servons, Zellig (Habert et al., 1997), les cooccurrents d'un mot sont ceux qui apparaissent dans le contexte d'un même syntagme nominal. Ces syntagmes nominaux sont fournis par des outils d'acquisition terminologique automatique. Pour la présente expérience, nous utilisons Lexter (Bourigault, 1993). Les syntagmes nominaux filtrés par Lexter dans la phrase donnée en exemple sont sténose serrée du tronc coronaire gauche et angor d’effort. En outre, Zellig retient seulement les relations binaires de dépendance entre une tête (un "gouverneur" dans la terminologie de Tesnière) et les mots qu'il régit, ses "dépendants" (ses modifieurs ou ses arguments). Dans le premier de ces syntagmes, Zellig sélectionne ainsi les couples : <sténose, serrée>, <sténose, tronc> (via la préposition de sous-jacente à la forme du), <tronc, coronaire>, et <tronc, gauche>. Dans le deuxième couple, tronc est un argument de sténose qui est la tête. Dans le troisième, la tête tronc est modifiée par l'adjectif coronaire. Les cooccurrents de tronc au sein des relations binaires des syntagmes nominaux dans lesquels il figure sont donc pour cette phrase : {sténose, coronaire, gauche}. Selon cette définition syntaxique restrictive de la cooccurrence, tronc n'est pas mis en relation avec des mots d'autres constituants syntaxiques (est et responsable n’en constituent plus des cooccurrents). Il n'est pas non plus mis en relation avec des mots qui figurent dans le même groupe syntaxique, mais qui ne dépendent pas directement de lui ou dont il ne dépend pas directement (serrée par exemple). Zellig dans un deuxième temps rapproche les mots qui entrent dans les mêmes contextes. C'est ainsi que tronc est rapproché de l'ensemble : {artère, branche, circonflexe, coronaire}. Tous ces mots sont en effet également modifiés par gauche et sont modifieurs de sténose. Dans un troisième temps, Zellig construit un graphe dont les nœuds sont les lemmes et dont les arêtes sont les contextes partagés par deux lemmes. Les liens au sein de ce graphe sont examinés pour isoler certaines des catégories sémantiques propres au corpus étudié.
2. Affiner les proximités de comportement syntaxique
Cet "écrémage" a pour objectif de dégager les associations les plus pertinentes pour rendre compte du fonctionnement en contexte d'un mot. Cependant, ce rapprochement des mots sur la base des dépendances binaires sous-jacentes aux arbres syntaxiques dans lesquels ils figurent n’exploite qu’une partie seulement des informations fournies par les arbres d’analyse. Les relations entre les dépendances binaires au sein d’un même arbre d’analyse disparaissent. Considérons les réalisations dans Menelas de la dépendance <sténose, tronc> :
1. sténose diffuse de tout le tronc commun de la coronaire gauche
2. sténose distale peu serrée du tronc commun de la coronaire gauche
3. sténose du tronc (3 oc.)
4. sténose du tronc commun de la coronaire gauche
5. sténose du tronc commun gauche (2 oc.)
6. sténose du tronc coronaire gauche aux alentours de 40 %
7. sténose du tronc de la circonflexe
8. sténose du tronc gauche (4 oc.)
9. sténose longue serrée et très calcifiée du tronc de la circonflexe
10. sténose non significative du tronc commun de la coronaire gauche
11. sténose serrée du tronc coronaire gauche
12. sténose serrée du tronc de la cx
13. sténose sévère du tronc commun de l’artère coronaire gauche
14. sténose sévère du tronc commun gauche (2 oc.)
15. sténose significative distale du tronc commun de la coronaire gauche
16. sténose très serrée du tronc de la coronaire gauche
17. sténose tubulaire de 60-70 % du tronc commun
18. sténoses du tronc commun de l’artère coronaire gauche
19. sténose du tronc commun de la coronaire gauche sévère
20. sténoses serrées du tronc de la coronaire gauche
Tronc y est toujours déterminé (par commun et gauche, voire par un syntagme prépositionnel dont la tête est un nom d’artère : coronaire, circonflexe, etc.). En outre, le "site" syntaxique préférentiel de réalisation d’une dépendance binaire est significatif. Tronc, qui est la tête des dépendances <tronc, commun>, <tronc, gauche>, <tronc, artère>, etc., dans les exemples, n’occupe ce rôle que comme dépendant d’une autre tête, ici sténose. Dans les groupes nominaux complexes où il s’insère, tronc est toujours dans une position de dépendant. Sténose, par contre, est généralement la tête du groupe nominal complet. Les noms qui occupent de telles positions de "gouverneurs" correspondent souvent en langue de spécialité aux notions essentielles du domaine et aux hyperonymes des séries paradigmatiques qui le caractérisent.
Notre objectif dans ces pages est d’enrichir la représentation des proximités entre mots par une prise en compte plus complète des relations syntaxiques dans lesquelles ils entrent au sein des groupes nominaux analysés. Pour cela, il nous faut disposer d’une représentation abstraite de ces relations qui nous permette de dépasser la diversité des arbres traités. Cette représentation doit permettre par exemple de signifier que sténose est la tête "principale" de l’ensemble des vingt groupes nominaux donnés ci-dessus, même si ces groupes diffèrent profondément les uns des autres en complexité (nombre de mots et structure) et en lexique. Pour cette raison, nous avons recours à un formalisme logique de description d’arbres.
3. Un formalisme logique de description d’arbres
Le formalisme que nous avons adopté (Folch et Habert, 1996), inspiré de la D-Theory (Marcus et al., 1983) et de son extension récente (Vijay-Shanker, 1992), est un langage de description d’arbres qui permet de raisonner sur les structures d’arbres annotées. Ce formalisme décrit les structures d’arbres en termes de trois relations primitives : la dominance immédiate (entre un nœud et ses fils éventuels), la précédence (l’ordre linéaire des fils d’un même nœud) et l’étiquetage (la catégorie non terminale ou le lemme du nœud).
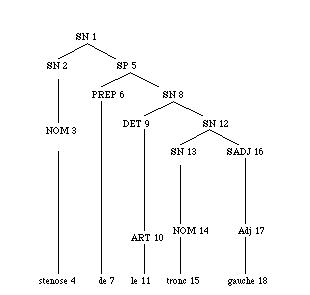
Soit l’arbre correspondant à sténose du tronc gauche (dont les nœuds sont numérotés pour qu’on puisse y faire référence) :
Cet arbre est décrit par les relations élémentaires suivantes :
|
Etiquette |
Précédence |
Dominance immédiate |
|
(Etiquette 1 SN) |
(Précédence 2 5) |
(DominanceImmédiate 1 2) |
Elles se lisent ainsi : le nœud 1 a pour étiquette SN, le nœud 2 précède le nœud 5, le nœud 1 domine immédiatement le nœud 2, etc. Les relations sont ici représentées par des listes parenthésées : le premier élément de chaque liste est le nom de la relation et les éléments restants sont les opérandes, les arguments de la relation.
4. Définition de relations plus fines
A partir de ces relations élémentaires, on peut définir des relations supplémentaires qui permettent de modéliser des liens syntaxiques arbitrairement complexes. Par exemple, la dominance stricte (entre un nœud ancêtre et un de ses descendants) est définie comme la fermeture transitive de la relation de dominance immédiate. Il existe entre les deux nœuds concernés une chaîne ininterrompue de nœuds se dominant immédiatement les uns les autres : (DominanceStricte 1 18), par exemple. (TêteDeSN <nœud1> <nœud2>) décrit une relation entre un <nœud1> d’étiquette SN et un <nœud2> qui correspond à une feuille terminale. Elle doit vérifier les contraintes suivantes : <nœud2> est dominé de façon immédiate par un <nœud3> intermédiaire d’étiquette N ; <nœud3> est dominé de façon stricte par <nœud1> ; il y a une séquence de nœuds d’étiquette SN entre <nœud1> et <nœud3>, mais il ne peut pas y avoir de nœuds d’autres catégories. L’arbre ci-dessous vérifie les relations (TêteDeSN 1 4), (TêteDeSN 8 15), mais pas la relation (TêteDeSN 1 15) : le nœud 5 porte l’étiquette SP et non SN et viole ainsi la 3ème contrainte. Cette nouvelle relation permet à son tour d’en définir d’autres. C’est ainsi que (TêtePrincipale <nœud1> <nœud2>) décrit une relation entre un <nœud1> d’étiquette SN et un mot, <nœud2>, telle que se vérifie la relation (TêteDeSN <nœud1> <nœud2>, donc que ce mot <nœud2> soit la tête d’un syntagme nominal, et que <nœud1>, la racine de ce syntagme, soit la racine de l’arbre tout entier. Ou encore pour les noms, les relations complémentaires (ModifiéParSyntagmePrépositionnel <nom>), (ModifiéParAdjectifAGauche <nom> <adjectif>), (ModifiéParAdjectifADroite <nom> <adjectif>). Dans notre exemple, (ModifiéParAdjectifADroite 15 18), par contre, le nœud 4 n’entre pas dans cette relation.
5. Préparer le regroupement des régularités de comportement
L’ensemble des relations définies à partir des trois relations primitives permet de caractériser très précisément le fonctionnement de chaque mot dans chacun des arbres où il figure. L’étape suivante est de dégager les régularités globales pour chaque mot : apparaît-il plutôt en position de tête principale ou en position de dépendant ? Est-il lui-même modifié ?
∑
Dans un premier temps, pour chaque forme dans un arbre, on génère des vecteurs de n dimensions où chaque dimension correspond à un paramètre décrivant un aspect du comportement syntaxique de la forme dans cet arbre ;∑
Dans un deuxième temps, à partir des informations locales stockées dans les vecteurs, on construit des tableaux globaux qui intègrent tous les vecteurs correspondant aux différentes occurrences des mots du corpus ;∑
Ces tableaux sont alors exportés vers des logiciels statistiques afin de réaliser des regroupements de vecteurs sur la base d’algorithmes de classification.Pour la présente expérience, on construit un vecteur pour chaque tête nominale de chaque arbre. Chaque colonne du vecteur indique si le nom entre ou non dans la relation en question (ce qui est noté par un 1 ou un 0). Est-il modifié par un syntagme prépositionnel (colonne 2 - P), par un adjectif à gauche (colonne 3 - AG), par un adjectif à droite (colonne 4 - AD) ou n’est-il pas modifié du tout (colonne 5 - NOT) :
|
nom |
P |
AG |
AD |
NOT |
|
|
|
|
|
|
|
sténose |
1 |
0 |
0 |
0 |
|
|
|
|
|
|
|
tronc |
0 |
0 |
1 |
0 |
Les vecteurs cumulant les observations pour les 20 exemples de la section 2 sont les suivants :
|
sténose |
27 |
0 |
14 |
0 |
|
|
|
|
|
|
|
tronc |
13 |
0 |
19 |
3 |
On note par exemple, dans cet échantillon restreint, que tronc est proportionnellement plus modifié par des adjectifs à droite que sténose. Ces deux noms ne sont jamais modifiés par des adjectifs à gauche. Tronc se rencontre sans modifieur ni adjectival ni prépositionnel, ce n’est pas le cas de sténose.
6. Régularités observées
On a utilisé les méthodes de classification offertes par SAS pour regrouper les noms du corpus. Les cases des vecteurs correspondent ici aux expansions associés aux formes nominales, on retrouve donc dans les classes générées les noms qui ont un comportement similaire par rapport aux éléments qu’ils ont tendance à dominer. Tronc est ainsi rapproché de noms essentiellement modifiés par des adjectifs à droite et moins par des syntagmes prépositionnels, comme d’autres localisations : {réseau, branche, ventricule, territoire}, mais aussi des mots renvoyant à des affections ou des dysfonctionnements : {nécrose, cinétique, hypokinésie, évolution, syndrome}. Nous ne donnons que deux exemples de classes fournies par SAS. La classe 1 par exemple se caractérise avant tout par l’absence totale de modification (colonne NOT), tandis que la classe 7 manifeste une modification adjectivale à gauche.
-------------------------------------- Cluster=1 -----------------------------------------
OBS FORME P AD AG NOT DISTANCE
1 SEGMENT 20 57 13 67 23.8354
2 EJECTIO1 0 18 0 63 27.9844
3 JOUR 14 21 9 68 19.8274
4 AVAL 8 26 7 53 27.2695
5 REVASCU2 3 23 6 41 40.1201
6 DR 0 1 0 61 42.6688
7 RISQUE 11 30 2 51 27.5522
8 IVA 14 57 1 110 38.3031
-------------------------------------- Cluster=7 -----------------------------------------
OBS FORME P AD AG NOT DISTANCE
1610 ANTERO 4 36 30 0 11.1696
1611 ETAT 11 45 22 1 17.5773
1612 PONTAGE 7 29 19 25 27.8345
1613 RESULTA1 14 38 50 4 13.6806
1614 ANGIOPL2 21 43 20 17 23.6169
1615 DROITE 5 21 62 5 30.2417
7. Conclusion
Notre effort a porté dans l’immédiat sur la mise au point d’une chaîne de traitement qui "recycle" les arbres syntaxiques fournis par des analyseurs automatiques robustes (ici Lexter), qui examine les relations fines qu’entretiennent les mots dans ces arbres grâce au passage par une représentation logique de ces arbres comme de ces relations et qui synthètise ces notations dans des vecteurs passibles ensuite d’une analyse statistique. Nous avons testé l’intégralité de cette chaîne sur un ensemble restreint de relations, ce qui limite les conclusions qui peuvent en être effectivement tirées quant aux proximités des mots entre eux à cette aune.
L’étape suivant va consister à utiliser l’éventail complet des relations que nous avons dégagées (une trentaine) pour examiner le comportement des mots et à étudier, grâce en particulier à l’analyse factorielle, les corrélations entre les variables correspondantes (l’absence de détermination favorise probablement l’absence de modifieurs adjectivaux, par exemple). Nous comptons également noter dans les vecteurs les mots occupant telle ou telle position syntaxique, ce qui devrait permettre de dégager certaines préférences pour tel mot dans telle position syntaxique. Le jeu sur les gras, les italiques, les soulignés, dans les exemples de la section 2 entend "visualiser" ces préférences.
Nous espérons ainsi pouvoir avancer vers la mise en évidence automatique des opérateurs et des opérandes caractéristiques d’un domaine donné, dans la perspective de (Harris et al., 1989) et contribuer à mettre au jour des "grammaires de discours" au sens de Sueur (1982, p. 148). Ces grammaires doivent indiquer les connexions entre les préférences lexicales et les emplois syntaxiques : "Tel mot apparaît de manière privilégiée, mais, surtout, il apparaît de manière privilégiée à telle place et dans tel cadre".
Références
Bouaud J., Habert B., Nazarenko A., Zweigenbaum P. (1997). Regroupements issus de dépendances syntaxiques en corpus : catégorisation et confrontation avec deux modélisations conceptuelles. Actes Ingéniérie de la connaissance, Roscoff.
Bourigault D. (1993). Analyse syntaxique locale pour le repérage de termes complexes dans un texte. TAL, 34, 2, pp. 105-117.
Folch, H., Habert, B. (1996). Les quasi-arbres : un formalisme logique pour exprimer des requêtes en indexation structurée. Actes Informatique et Langue Naturelle, Nantes.
Gaussier, E., Habert, B. (1997). Langue spécialisée : des séquences observées aux noms possibles. Actes Mots possibles et mots existants, Lille, pp. 111-120.
Grefenstette G. (1994a). Explorations in Automatic Thesaurus Discovery. Dordrecht : Kluwer Academic Publishers.
Grefenstette G. (1994b). Corpus-derived first, second and third order affinities. Actes Euralex, Amsterdam.
Habert B., Bertrand-Gastaldy S., Nazarenko A., Dupuis F., Naulleau E., Lemieux M., Delisle C. (1997). Recyclage d'analyses syntaxiques automatiques pour le repérage de variantes de termes. Actes Coopération franco-québecoise en ingéniérie de la langue, Montréal, pp. 751-760.
Harris Z., Gottfried M., Ryckman T., Mattick P., Daladier A., Harris T.N., Harris S. (1989) The form of Information in Science. Analysis of Immunology Sublanguage. Dordrecht : Kluwer Adademic Publishers.
Marcus, M., Hindle, D., Fleck, M. (1983). D-theory : talking about talking about trees. Actes ACL’83, pp. 129-136.
Sueur, J.-P. (1982). Pour une grammaire du discours. Mots, 5, pp. 143-185.
Vijay-Shanker, K. (1992). Using descriptions of trees in a Tree Adjoining Grammar. Computational Linguistics, 18(4), pp. 482-516.
Zweigenbaum, P. et consortium Menelas (1994). Menelas : an access system for medical records using natural language. Computer Methods and Programs in Biomedicine, vol. 45, pp. 117-120.