Deux langues pour une même politique : Étude d’un corpus bilingue parallèle de textes politiques
Jean-Claude Deroubaix
Laboratoire "Lexicologie et textes politiques" (ENS Fontenay-Saint-Cloud)
RESH (Bruxelles)
avenue Winston Churchill 19, B-1180 Bruxelles, Belgique
Summary
There are numerous forums in the world where multiples languages are used for political, technical and administration communication. There are also many States where two or more languages are considered as official idioms. Whe think that if it is important to control the precision of translation it is also important to verify that all these texts content the same message. Today sociological and political scientists when working on textual data in multilingual fields must take in account this reality. We propose in this paper an experience on the corpus of "déclarations gouvernementales" in Belgium which form a double corpus, one in french and another in dutch.
We examine by the way the possibility to extract automatically a lexicon from the measure of distance between words in the two corpuses.
La multiplication d’organes politiques internationaux, la constitution d’états fédéraux, où cohabitent des populations parlant plusieurs langues et où ne s’impose pas l’usage d’une seule langue officielle, la mise en œuvre d’organismes politico-économiques régionaux comme l‘Union européenne, Mercosur ou l’Alena sont des phénomènes qui ont induit le développement de l’écriture de textes politiques et administratifs en plusieurs versions linguistiques. Au delà des problèmes soulevés par le volume de la traduction des textes, cette multiplication de sources multilingues soulève la question de la réalité de l’unicité du message politique, juridique et administratif émis. Cette concordance des messages est théoriquement assurée au cas par cas par le traducteur et éventuellement son ou ses réviseurs. Mais peut-on s’assurer que globalement cette vérification faite au cas par cas suffise à conforter l’homogénéité globale des corpus multilingues.
Les actes des Journées internationales d’analyse statistique de données textuelles de 1993 (JADT93-Montpellier) contiennent 49 communications, toutes ces communications ont trait à des corpus de textes rédigés ou prononcés dans une seule langue. L’édition suivante des mêmes journées (JADT95-Rome) contient 97 textes de communications mais cette fois, trois communications sont consacrées à des corpus multilingues et deux plus spécialement à des travaux de traduction.
Carol Peters et Eugenio Picchi introduisent leur communication par ces mots : "Following the intensive linguistic studies on monolingual text corpora during the eighties, many researchers have now begun to turn their attention to bilingual text archives. […] In particular such corpora are beginning to be considered as important tools in bilingual dictionnary compilation, translating, and language learning activities in general." Cette assertion appelle deux remarques. La première concerne l’optimisme qui pousse les auteurs à s’imaginer être nombreux à s’intéresser aux corpus bilingues ou multilingues ; leur proportion est faible rapportée à l’ensemble des chercheurs qui se préoccupent d’analyse statistique de données textuelles, du moins si l’on accepte l’idée que les JADT93 et 95 sont un bon échantillon de ce domaine. La seconde remarque est plus importante, l’intérêt de l’étude des corpus bilingues ne se limite pas à la facilitation de la traduction ou à l’amélioration de l’apprentissage des langues. De même que l’analyse statistique de données textuelle monolinguistique trouve non pas une application dans l’ensemble des sciences humaines mais s’insère dans les procédures de recherche de ces disciplines comme un outil priviliégié de l’étude des relations sociales qui mettent toutes en œuvre peu ou prou le langage, l’analyse de corpus multilingues devrait se constituer un ensemble de méthodes et de procédures de recherche utiles à l’analyse des situations humaines où interagissent ou se confrontent plusieurs langues. La traduction et plus généralement le "transfert linguistique" est évidemment l’activité qui s’impose à l’esprit. Mais même en ne se restreignant qu’à l’Union européenne, dont le projet constitutif implique une unification économique et politique avec le maintien de la diversité culturelle et donc de la pluralité des langues, qui ne sent combien les études sociologiques et politiques seront à terme dépendantes de notre capacité à comparer les productions linguistiques faites dans des langues différentes !
L’étude statistique du vocabulaire de textes politiques unilingues permet de mettre en évidence des phénomènes structurels de transformation du vocabulaire dans le temps ou selon les options politiques. Il reste cependant difficile de dissocier les effets langagiers propres au domaine politique des effets langagiers plus généraux liés à la langue utilisée. En d’autres termes s’il avait fallu prononcer ou écrire ces textes dans une autre langue le vocabulaire de ces corpus auraient-ils été structurés de la même façon ? Les messages, les slogans auraient-ils été les mêmes ? Auraient-ils bénéficié d’une présentation ou d’un éclairage identiques ? L’existence de corpus parallèles bilingues ou multilingues permet dans certaines situations de tenter des réponses à ces questions et dans le même temps de vérifier que les corpus sont bien identiques ou au moins semblables. Sans interroger le sens des textes mais en cherchant à identifier des structures semblables à leur surface, l’on peut se donner une mesure "objectivée" de l’homogénéité de corpus multilingues.
La Belgique est l’un de ces États où les institutions politiques nationales sont bilingues. Ceci signifie que celles-ci produisent des textes dans les deux langues nationales (français et néerlandais, et qui parfois deviennent trois lorsque s’y ajoute l’allemand). La Constitution dont le texte original de 1831 était français est depuis environ un siècle traduite en néerlandais. Les deux textes font également foi, ils sont égaux. À l’exemple de la Constitution, les textes de loi sont aussi bilingues, comme le sont encore les communications politiques importantes du gouvernement. L’une de ces communications jouit d’une particulière importance : la déclaration gouvernementale car elle contient à la fois le programme du gouvernement à peine constitué et une demande de confiance adressée aux Chambres. L’obtention d’un vote de confiance par le gouvernement à la suite de la lecture de la déclaration gouvernementale installe définitivement le cabinet dans ses fonctions.
Nous avons étudié le corpus formé par les 38 déclarations lues devant les Chambres depuis 1944 jusqu’à la fin de la Belgique unitaire en 1992. Nous avions cependant travaillé sur le corpus des textes français. Il s’imposait d’explorer les déclarations telles que les citoyens néerlandophones ont pu les lire ou les entendre et comparer les résultats avec ceux de l’étude du corpus francophone.
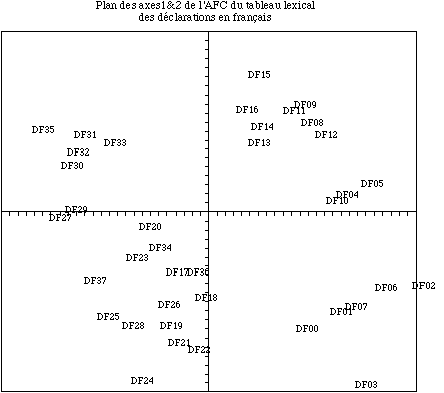
Pour faire bref, l’élément le plus saillant de notre étude sur les déclarations en français était la mise en évidence d’une structure de chronique textuelle. Autrement dit, les déclarations ne se divisent pas en déclarations de centre droit ou de centre gauche selon la coalition au pouvoir mais selon leur appartenance à la période. L’évolution du vocabulaire entraîne chaque gouvernement à utiliser un vocabulaire proche de celui de son prédécesseur. Le premier plan d’une analyse factorielle des correspondances montre bien ce phénomène de progression le long d’un axe dont la signification se rapproche de celle d’un axe temporel [voir figure 1].
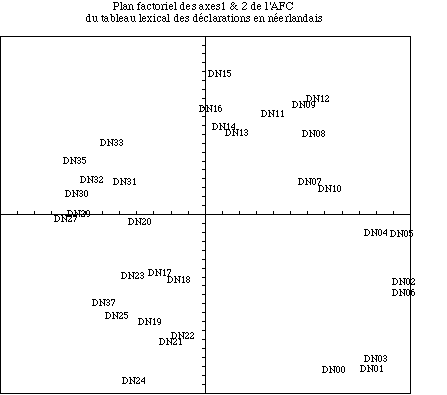
L’étude du corpus néerlandais nous rend la même image générale nous confortant dans l’idée que la contiguité temporelle des textes organise la manière dont ils se ressemblent plus que les affinités politiques [voir figure 2].
On pourrait songer à superposer les deux plans, on observerait alors sans peine que les deux versions des déclarations des différents gouvernements occupent des places structurellement semblables.
L’analyse du tableau lexical formé par la superposition des deux tableaux lexicaux, néerlandais et français, ou, ce qui revient au même, l’étude du tableau lexical issu de l’étude du corpus dont chaque partie comprendrait à la fois sa version dans l’une et l’autre langues, conduit évidemment à une structure semblable et permet de voir comment se situent l’un par rapport à l’autre les deux nuages formés par les parties francophones et néerlandophones[voir figure 3].
Seule peut être notée le "déplacement" du point correspondant à la déclaration numéro 7. Elle est l’indice d’un phénomène de politique linguistique : les Néerlandais et les Flamands ont opéré en 1947 une réforme de l’orthographe assez sévère. Le corpus comportait donc des textes écrits sous deux régimes orthographiques distincts. Nous avons réalisé une unification de l’orthographe selon la version la plus moderne afin d’éviter que cette réforme ne perturbe l’analyse. Cependant, outre l’orthographe, d’autres éléments ont été proposés à la réforme et en particulier l’usage de "van" pour marquer le complément du nom en lieu et place du génitif. La déclaration DG7 est particulière en ce qu’elle est la première déclaration à appliquer les nouvelles règles et elle les applique tellement résolument qu’elle se distingue des textes qui lui succèdent et qui appliqueront les directives modernes plus modérément.
La mise en évidence d’une structure semblable sur les deux corpus mène à deux conclusions importantes. Une confirmation méthodologique d’abord. Puisque nous retrouvons une même organisation textuelle, nous pouvons conclure au moins à la robustesse des méthodes utilisées ; d’autant plus que nous restreignant à l’étude des formes graphiques, nous pouvions craindre de plus grands écarts entre les deux corpus : les verbes du néerlandais ne se conjuguent pas en autant de formes que les verbes français, l’usage de mots composés par agglutination est fréquent en néerlandais, les adjectifs ne possèdent que deux formes et non quatre comme c’est le cas généralement en français, etc.
Une confirmation politique ensuite : au moins pour ce qui concerne les grandes lignes du discours, on peut admettre l’idée qu’il y a une même histoire du gouvernement belge vue par ceux-ci en flamand ou en français.
Cette démarche prend place dans une tentative de mettre au point des méthodes particulières d’étude de corpus multilingues car il paraît d’ores et déjà clair que les approches globales (AFC, Classification automatique) devront être complétées par des recherches plus fines sur les distributions conjointes des vocabulaires dans les textes. En effet, comme le signalent Daniel B. Jones et Harold Somers [1985], il est intéressant de pouvoir utiliser les corpus multilingues parallèles pour essayer d’extraire le plus automatiquement possible des informations concernant les correspondances de vocabulaire et enrichir, sur la base de corpus, les lexiques de traduction. Une première approche proposée par ces auteurs consiste à établir pour chaque forme d’un texte dans une langue une liste des formes correspondantes dans le même texte rédigé dans une autre langue. Pour établir une telle liste, on calcule une distance entre les distributions des formes entre partitions semblables des corpus, les résultats sont assez décevants pour les distances essayées.
Puisque l’analyse factorielle des correspondances donne une image structurelle semblable des deux sous-corpus des déclarations gouvernementales, il était tentant de reproduire ces tentatives mais en utilisant pour rechercher la liste des mots les distances du khi-2. Si l’on conserve une partition du corpus en 38 déclarations, c’est-à-dire si l’on retient une partition "naturelle" du corpus, les résultats paraissent encourageants :
Par exemple, en classant par distance croissante dans l’espace des dix premiers facteurs de l’AFC, les formes néerlandaises les plus proches des formes françaises on obtient des résultats comme ceux repris dans le tableau suivant. On observe une adéquation excellente pour Gouvernement, pour, par, nous, est, un, des résultats un peu moins bons pour il (zij) et des échecs pour nombre d’autres formes et en particulier politique.
|
Gouvernement |
regering |
op |
het |
om |
de |
|
un |
een |
voor |
in |
dit |
en |
|
il |
te |
brengen |
zij |
uit |
stellen |
|
qui |
uit |
brengen |
te |
nog |
aan |
|
que |
dat |
brengen |
uit |
te |
is |
|
est |
is |
tijdens |
dat |
niet |
brengen |
|
au |
het |
de |
van |
en |
op |
|
pour |
voor |
de |
het |
met |
om |
|
par |
door |
op |
zullen |
eerste |
voeren |
|
politique |
economisch |
worden |
een |
deze |
en |
|
plus |
meer |
kunnen |
een |
twee |
vragen |
|
sur |
met |
op |
om |
voor |
worden |
|
ce |
dat |
is |
kunnen |
met |
uit |
Comme les résultats ne sont pas parfaits, nous avons essayé de réaliser la même expérience mais en divisant les corpus en 89 parties d’environ 1300 occurrences (ce fut d’autant plus facile à réaliser que les deux sous-corpus comptaient approximativement 115000 occurrences chacun) et en appariant les 89 parties.
Les résultats furent cette fois décevants. Les distances sont calculées sur l’ensemble des facteurs et sont présentées classées à partir de la plus petite.
|
Gouvernement |
het |
van |
de |
en |
in |
op |
een |
regering |
|
un |
de |
en |
van |
in |
het |
een |
op |
met |
|
il |
te |
en |
het |
van |
de |
regering |
een |
door |
|
qui |
de |
het |
van |
te |
en |
regering |
een |
aan |
|
que |
de |
het |
en |
van |
in |
te |
een |
regering |
|
est |
en |
de |
het |
van |
te |
een |
in |
regering |
|
au |
de |
van |
het |
en |
in |
een |
op |
regering |
|
pour |
de |
het |
van |
en |
een |
in |
regering |
te |
|
par |
het |
de |
van |
en |
te |
een |
in |
regering |
|
politique |
de |
in |
het |
en |
een |
van |
voor |
met |
|
plus |
en |
in |
het |
de |
een |
van |
met |
voor |
|
sur |
de |
het |
regering |
in |
van |
en |
op |
een |
|
ce |
de |
van |
een |
op |
het |
en |
regering |
in |
On observera la régression au 8ème rang de la traduction normale de Gouvernement par regering et l’intrusion de nombreuses formes de "mots-outils".
Jones et Somers estiment qu’il faut arriver à une meilleure réalisation de l’appariement, et qu’une des voies à explorer consiste à se servir de la position des différentes occurrences dans le texte pour "ancrer" la recherche des formes traduites. La division des deux sous-corpus en 89 parties de taille assez semblables et le fait que dans un texte de nature politique et non littéraire, les traducteurs respectent la division en phrases ou en paragraphes auraient dû nous garantir un "ancrage" similaire. Encore une fois, mais l’expérience reste à tenter, nous pensons qu’une approche par la recherche de segments répétés pourrait conduire à une certaine automatisation de la construction des lexiques.
Références
Deroubaix, J. Cl. (1997). Les déclarations gouvernementales en Belgique (1944-1992). Étude de lexicométrie politique, Thèse de doctorat, Sorbonne nouvelle Paris 3, 1997.
Bolasco, S. (1997). Il lessico del discorso programmatico di governo, in M. Villone e A. Zuliani (a cura di), L’attività dei governi della republica italiana (1948-1994), Bologna : Il Mulino,
Jones, D.B. and Somers, H. (1995). Bilingual vocabulary estimation from noisy parallel corpora using variable bag estimation, in S. Bolasco, L. Lebart et A. Salem Analisi statistica dei dati testuali, vol 1, JADT95.
Lebart, L. et Salem, A. (1995). Statistique textuelle, Paris : Dunod.