Un banco de datos Filológicos (BDFSN)
Jesús-Luis Cunchillos Ilarri
Laboratorio de Hermeneumática - CSIC-Instituto de Filología
Duque de Medinaceli, 8, 28014 Madrid
Tel 4290626/ Ext. 2503 - Fax (91) 3690940
correo eléctrónico (equipo) : cunchillos@fresno.csic.es
(personal) : ilarri@shapshu.filol.csic.es
Résumé
Une fois résolus les problèmes spécifiques à l'exploitation informatique des langues sémitiques (alphabet, ordre alphabétique spécifique), la méthode historico-critique et l'interdisciplinarité philologie/informatique ont permis la formalisation des premières étapes du parcours du reconnaissance critique du texte. Les trois modules créés qui serviront de prototypes, correspondent aux premières étapes (saisie et recherche, segmentation et restitution des chaînes graphématiques incomplètes et chaînes brisées, fichier et concordance de mots en morphologie déployée). Les statistiques obtenues jusqu'à présent concernent l'extension structurelle de la BDFSN et la grandeur des données philologiques exploitées, etc. Nous n’avons pas utilisé la méthode statistique. Cette présentation est plutôt une invitation aux statisticiens à participer dans ce projet.
Introduction
El Banco de Datos Filológicos Semíticos Noroccidentales (BDFSN) es fundamentalmente un Banco de datos objeto de estudio, sólo circunstancialmente ofrece datos referenciales (bibliografía). Los datos, objeto de estudio y por lo tanto de tratamiento informático posterior, son filológicos y pertenecen al mundo semítico noroccidental lo que acarrea problemas de alfabetos (fonts) para transcribir lenguas semíticas, así como los subsiguientes problemas de ordenación de los datos según un orden que no es el latino. Todos esos problemas han sido resueltos.
El Banco dispone de un sistema de gestión, una base de datos relacional (4ème Dimension) con aplicaciones propias que hemos resumido en Siamtu (sistema integrado de análisis morfológicos de textos ugaríticos).
La unidad mínima de codificación (sigla) es la línea, manera normal de referenciar en epigrafía semítica, textos incisos en soporte duro como es la tablilla de barro cocida en el horno. La unidad literaria está constituida por una o varias tablillas según los géneros (p. e. una en el caso de la correspondencia, tres o más en el caso de los mitos y leyendas). En cualquier momento el usuario de BDFSN puede disponer del texto completo de una tablilla. Incluso dispone del "texto compuesto" o "texto multicolaciones" ya que se han incluido igualmente en el BDFSN todas las colaciones de cada tablilla.
El método filológico utilizado, y que subyace a todo el tratamiento informático, es el conocido como histórico crítico. Pero forma parte de la filosofía del conceptor del BDFSN que todos los métodos alcanzan la realidad de manera diversa, pero ninguno de manera absoluta. Por lo tanto siempre estamos dispuestos a utilizar ulteriormente otros métodos con tal de que se encargue de ello un especialista en el manejo del método que se desea utilizar. Ahora comprenderán Vds por qué he podido aceptar la invitación que se me hizo para participar en una reunión de expertos estadísticos a pesar de no ser yo mismo especialista en estadística. Por lo demás el BDFSN utiliza muy poco la estadística, como tendrán Vds la posibilidad de comprobar. Quisiera, pues, ser esta comunicación una invitación a los estadísticos a mejorar o completar nuestros métodos.
1. El "Banco de Datos Filológicos Semíticos Noroccidentales" (BDFSN)
Organización. Hemos hablado in extenso en una reciente reunión científica. Nos referíamos a la concepción y al diseño (primera fase). Enunciábamos el principio básico de la interdisciplinariedad : filología e informática. El diálogo entre la filología y la informática lleva a utilizar los métodos propios de cada disciplina, filología e informática, más la resultante del diálogo entre ambas. En efecto, se producen cambios y mejoras en la metodología de cada una de las disciplinas bajo el influjo de la otra.
Los objetivos son cuatro : 1º Reunir en un Banco de Datos todo el Semítico noroccidental, es decir, todos los datos objeto de estudio del semítico noroccidental.
2º Recorrer con esos datos todas las etapas que recorre el especialista cuando comenta científicamente un texto. Partiendo del grafema hasta la interpretación.
3º Crear los programas informáticos (herramientas) que sirvan de ayuda al lingüista y comentarista de textos en el estudio y tratamiento científico-crítico de los textos objeto de estudio. Deberán, pues, formalizarse todas las etapas del conocimiento científico-crítico (Hermeneumática).
4º El objetivo último no consiste solamente en informatizar una lengua, sino conocer, a través de ella, el circuito del reconocimiento crítico de un texto.
En la misma comunicación a la que me refería más arriba hablábamos también de la planificación (segunda fase de la organización) y de la ejecución (tercera fase). No me entretendré, pues, en ello.
2. Un prototipo, varios módulos
En otra comunicación reciente nos referíamos a los resultados y a las expectativas. Para evitar repeticiones, envío al lector a los trabajos precedentes. Me entetendré únicamente en señalar que investigando primero en la construcción de un prototipo (el ugarítico). Con él se van recorriendo las etapas del conocimiento y se construyen los programas con todas las tareas que realiza el investigador.
Del prototipo se extraen enseñanzas muy útiles. A cada etapa corresponde un módulo : unos datos proporcionados por el filólogo, unos procesos informáticos, los datos tratados terminan en un fichero. El conjunto es un módulo.
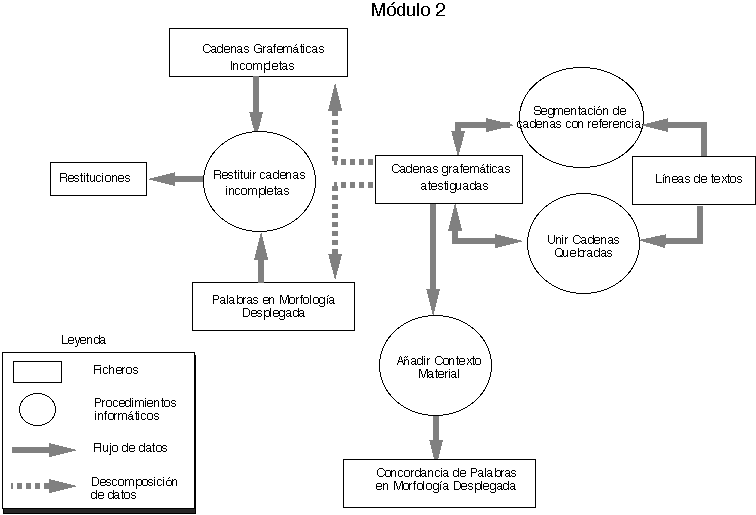
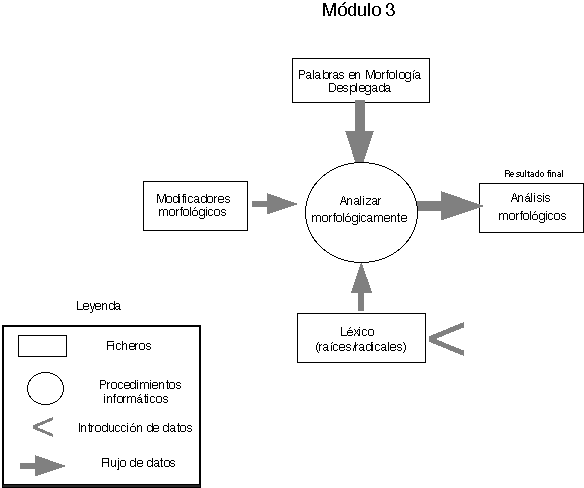
Hasta ahora hemos construido tres módulos : el primero dedicado a la introducción de datos, modificación y búsquedas ; el segundo se ocupa de la segmentación de Cadenas Grafemáticas, de la resticución de cadenas Grafemáticas incompletas y de las Cadenas Quebradas, termina en el fichero de Palabras en Morfología Desplegada y permite, con el contexto, llegar a una Concordancia de Palabras en Morfología Desplegada.
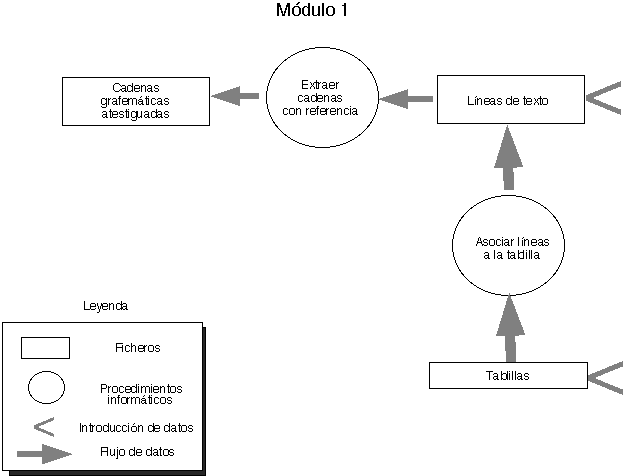
Véase, más adelante, el diseño de cada uno de los tres módulos realizados (figs. 1, 2, 3).
Lo aprendido con el prototipo se aplica a otras lenguas. Ahora construimos varios módulos 1, cada uno preparado para una lengua diferente. De ahí puede surgir un módulo 1 que englobe varias lenguas y escrituras.
3. Las estadísticas en el BDFSN
Como ya hemos indicado más arriba, BDFSN no utiliza los métodos estadísticos. Sin embargo proporciona al usuario algunas magnitudes de los datos, listados e incluso algunos gráficos. Todo ello será juzgado, y con razón, por los colegas dedicados a la estadística del lenguaje, como muy elemental. Así lo consideramos también nosotros. No obstante lo vamos a exponer para que los avezados en el uso de la estadística, como son los que me escuchan, puedan tener puntos de arranque para la aplicación de sus métodos y puedan sugerirnos cómo mejorar lo realizado hasta ahora. No hay, pues, la mínima pretensión por nuestra parte, sólo el deseo de cooperar con otras disciplinas, con otros especialistas.
1.- Para empezar veamos : las magnitudes de bdfsn-siamtu (agosto 1997)
Estructura 5, 8 Mb
Tablas relacionales 17
Definición de claves ajenas (enlaces)
Atributos 130
Dominios (listas enumeradas) 15
Procesos
Procedimientos (procedimientos, tratamientos de pantallas y de objetos) 1.119
Pantallas 144
Menús 36
Datos almacenados según la estructura diseñada 57, 9 Mb
|
Nº ocurrencias |
Lengua ugarítica |
|
1.359 |
Tablillas |
|
en curso de introducción |
Imágenes de tablillas |
|
26.894 |
Líneas de texto |
|
65.586 |
Ocurrencias de Cadenas Grafemáticas |
|
6.727 |
Palabras en Morfología Desplegada atestiguadas |
|
3.806 |
Cadenas Grafemáticas Incompletas |
|
6.914 |
Entradas del Léxico |
|
122 |
Modificadores morfológ. (prefijos, preformantes, afijos, ...) |
|
3061 |
Ocurrencias de Cadenas Grafemáticas Divididas |
|
390 |
Cadenas Quebradas |
|
30.952 |
Restituciones de Cadenas Incompletas |
|
32.388 |
Análisis morfológicos obtenidos |
|
544 |
Sintagmas simples |
2.- El usuario dispone de listados de : Tablillas, Líneas de texto, Ocurrencias de Cadenas Grafemáticas, Palabras en Morfología Desplegada atestiguadas, Cadenas Grafemáticas Incompletas, Ocurrencias de Cadenas Grafemáticas Divididas, Cadenas Quebradas, Restituciones de Cadenas Incompletas, etc. Igualmente listados de : PMD que tienen análisis y cuales no lo tienen ; número de análisis de cada palabra, número de análisis morfológicos de una raíz o radical. Además la CPU añade el contexto de cada PMD y la CRU el número de contextos de cada entrada del léxico.
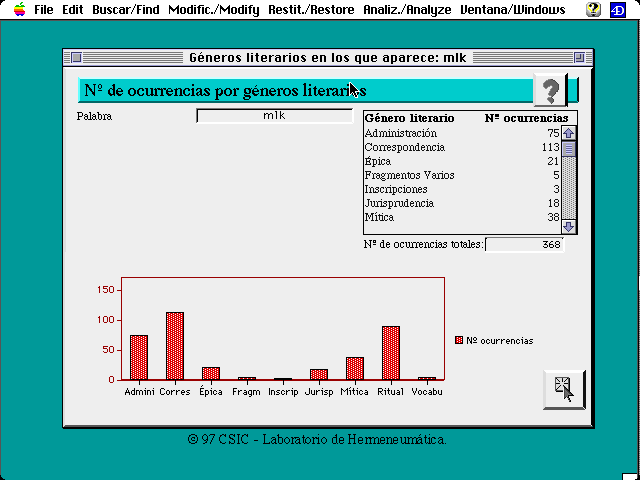
3.- Gráficos de :
Distribución del uso de una palabra por géneros literarios (fig. 4).
Modificadores morfológicos por tipos (fig. 5).
Clasificación de las entradas del léxico por su condición gramatical (fig. 6).
Conclusion
Hasta esos puntos ha llegado el BDFSN. Ahí están las entradas para los colegas especialistas en estadística que son Vds. Nuestro deseo es colaborar con Vds y esperamos poder presentar en una próxima JADT resultados mejorados gracias a la intervención de algunos de entre Vds a quienes invitamos a unirse al equipo de investigación del BDFSN.