Vers un modèle hybride pour le traitement de l'information lexicale dans les bases de données textuelles
Ismaïl Biskri, Jean-Guy Meunier
Laboratoire de l’ANalyse Cognitive de l’Information - Université du Québec à Montréal
CP8888, succursale Centre-ville, Montréal H3C 3P8 Canada
biskri@pluton.lanci.uqam.ca - meunier.jean-guy@uqam.ca
Résumé
One of today's most intensive areas of research is in that of Textual data mining. This area of research is of the utmost importance for computer technology which finds itself confronted with volumes of unformated electronic documents. Several strategies are possible to resolve this problem, some are of a mathematical nature and others, of that of computational linguistics. In this article we will present an approach using a hybrid model of data mining. Our model takes its inspiration from neuronal models, and from Applicative and Combinatory Categorical Grammar (ACCG) (Biskri, 1995) (Desclés, Biskri, 1996).
1. Introduction
De nos jours, un nombre croissant d'institutions accumulent très rapidement des quantités de documents qui ne sont souvent classés ou catégorisés que très sommairement. Très vite, les tâches de dépistage, d'exploration et de récupération de l'information présente dans ces textes, c'est-à-dire des "connaissances", deviennent extrêmement ardues, sinon impossibles. Pour y faire face, il devient nécessaire d'explorer de nouvelles approches d'aide à la lecture et à l'analyse de texte assistées par ordinateur (LATAO)
Du point de vue méthodologique, la question de l'extraction des connaissances dans les grandes bases de données textuelles rencontre des difficultés sérieuses. D'une part les approches descendantes sur des corpus dont on ignore le contenu est difficile à appliquer et ce malgré un souci de bien définir les règles discursives ou une base de connaissances exhaustives. D'autre part, les approches statistiques, bien que systématiques demeurent souvent 'bruitées' et peu précises. Pour résoudre ce problème, nous explorons un modèle hybride à deux étapes : une première qui applique des stratégies statistiques et une seconde qui applique sur les résultats des premières des analyseurs de nature linguistique.
2. Stratégies numériques
La recherche sur l'application des méthodes numériques ou à proprement parler statistiques a montré sa fécondité. Ces méthodes permettent un traitement systématique, efficace et rapide d'une grande masse de données textuelles. On trouve des applications séduisantes de ce type de méthodes dans l'identification des réseaux lexicaux (Church, 1994), la génération automatique des hypertextes (Balpe, Lelu 1996) la recherche d'information (Salton, 1994). Sur le plan mathématique ces stratégies peuvent être vues comme de la reconnaissance de forme ou de la classification d'unités d’informations. Divers types de modèles sont utilisables :
- multidimensionnels : a) par cooccurrences, les corrélationnelles (Church, 1994), b) par composantes principales (Salem, Lebart, 1988), c) par regroupement ou factorisation, etc.
- Connexionnistes : par réseau de neurones auto-associatif. (Veronis, 1990, Salton et al, 1994, Meunier et al, 1995).
- Champs de markov : par analyse topologiques et probabilistes (Bouchaffra, 1993).
- Algorithme génétique (Meunier et al, 1997)
Dans le choix des modèles, des contraintes importantes doivent être respectées a) le modèle doit être capable de traiter un flux textuel en perpétuel changement. C'est la contrainte de plasticité sinon les analyseurs doivent recommencer l’analyse de tout le corpus textuel à chaque nouvel intrant. b) Le modèle doit fournir des résultats interprétables soit par un humain soit par une machine. C'est la contrainte d'interprétabilité. Notre recherche montrera la pertinence, mais aussi la limite des approches connexionnistes dans une application particulière d'analyse de texte assistée par ordinateur à savoir l'extraction d'information pertinente au lexique.
3. La Grammaire Catégorielle Combinatoire Applicative dans le cadre de la Grammaire Applicative et Cognitive
La Grammaire Applicative et Cognitive (Desclés, 1990) postule trois niveaux de description des langues :
a- le niveau phénotypique (ou le phénotype) où sont représentées les caractéristiques particulières des langues naturelles (par exemple l’ordre des mots, les cas morphologiques, etc....). Les expressions linguistiques de ce niveau sont des unités linguistiques concaténées, la concaténation est notée par : ‘u1-u2-...-un’.
b- le niveau génotypique (ou le génotype) où sont exprimés les invariants grammaticaux et les structures sous-jacentes aux énoncés du niveau phénotypique. Il est décrit par une grammaire appelée "Grammaire applicative".
c- le niveau cognitif où sont représentées les significations des prédicats lexicaux par des schèmes sémantico-cognitifs.
Les trois niveaux font appel à des formalismes applicatifs typés où l'opération d'application d'un opérateur à un opérande est considérée comme primitive. Les niveaux deux et trois s'expriment dans le formalisme de la logique combinatoire typée de H.B. Curry (1958). Cette logique fait appel à des opérateurs abstraits - appelés "combinateurs" - qui permettent de composer intrinsèquement des opérateurs plus élémentaires entre eux. Les combinateurs sont associés à des règles d'élimination dont celles ci (U1, U2, U3 sont des expressions applicatives typées) :
((B u1 u2) u3) > (u1 (u2 u3))
((C* u1) u2) > (u2 u1)
Le modèle de la Grammaire Catégorielle Combinatoire Applicative (GCCA) relie explicitement les expressions phénotypiques à leurs représentations sous-jacentes dans le génotype. Le système consiste en :
(i) une analyse syntaxique des expressions concaténées du phénotype par une Grammaire Catégorielle Combinatoire.
(ii) une construction à partir du résultat de l’analyse syntaxique d'une interprétation sémantique fonctionnelle des expressions phénotypiques.
Les Grammaires Catégorielles assignent des catégories syntaxiques à chaque unité linguistique. Les catégories syntaxiques sont des types orientés engendrés à partir de types de base et de deux opérateurs constructifs ‘/’ et ‘\’.
(i) N (syntagme nominal) et S (phrase) sont des types de base.
(ii) Si X et Y sont des types orientés alors X/Y et X\Y sont des types orientés.
Une unité linguistique u de type orienté X sera désigné par ‘[X : u]’.
Les deux règles d’application (avant et arrière) sont notées :
[X/Y : u1] - [Y : u2] [Y : u1] - [X\Y : u2]
----------------------------> ; ----------------------------<
[X : (u1 u2)] [X : (u2 u1)]
Les prémisses dans chaque règle sont des concaténations d’unités linguistiques à types orientés considérées comme étant des opérateurs ou des opérandes, la conséquence de chaque règle est une expression applicative avec un type orienté.
La GCCA généralise les Grammaires Catégorielles classiques en introduisant des opérations de changement de type et des opérations de composition des types fonctionnels d’une part et l’application des règles catégorielles introduit les combinateurs B, C* dans la séquence syntagmatique. Cette introduction permet de passer d'une structure concaténée à une structure applicative. Les règles de la GCCA sont :
Règles de changement de type :
[X : u] [X : u]
---------------------->T ; ----------------------<T
[Y/(Y\X) : (C* u)] [Y\(Y/X) : (C* u)]
[X : u] [X : u]
---------------------->Tx ; ----------------------<Tx
[Y/(Y/X) : (C* u)] [Y\(Y\X) : (C* u)]
Règles de composition fonctionnelle :
[X/Y : u1]-[Y/Z : u2] [Y\Z : u1]-[X\Y : u2]
------------------------->B ; -------------------------<B
[X/Z : (B u1 u2)] [X\Z : (B u2 u1 )]
[X/Y : u1]-[Y\Z : u2] [Y/Z : u1]-[X\Y : u2]
--------------------------->Bx ; --------------------------<Bx
[X\Z : (B u1 u2)] [X/Z : (B u2 u1)]
Les prémisses des règles sont des expressions concaténées typées ; les résultats sont des expressions applicatives (typées) avec éventuellement introduction d'un combinateur. Le changement de type d'une unité u introduit le combinateur C*; la composition de deux unités concaténées introduit le combinateur B.
Pour l’exemple suivant La liberté renforce la démocratie nous avons l’analyse suivante :
1. [N/N : la]-[N : liberté]-[(S\N)/N : renforce]-[N/N : la]-[N : démocratie]
2. [N : (la liberté)]-[(S\N)/N : renforce]-[N/N : la]-[N : démocratie] (>)
3. [S/(S\N) : (C* (la liberté))]-[(S\N)/N : renforce]-[N/N : la]-[N : démocratie] (>T)
4. [S/N : (B (C* (la liberté)) renforce)]-[N/N : la]-[N : démocratie] (>B)
5. [S/N : (B (B (C* (la liberté)) renforce) la)]-[N : démocratie] (>B)
6. [S : ((B (B (C* (la liberté)) renforce) la) démocratie)] (>)
7. [S : ((B (B (C* (la liberté)) renforce) la) démocratie)]
8. [S : ((B (C* (la liberté)) renforce) (la démocratie))] B
9. [S : ((C* (la liberté)) (renforce (la démocratie)))] B
10. [S : ((renforce (la démocratie)) (la liberté)))] C*
11. [S : renforce (la démocratie) (la liberté)]
Ainsi pour cet exemple, à l’étape 1 des types catégoriels sont assignés aux unités linguistiques. À l’étape 2, la règle (>) est appliqué aux unités linguistiques la et liberté. À l’étape 3 une règle de changement de type (>T) est déclenchée pour construire un opérateur (C* (la liberté)) à partir de l’opérande (la liberté). Cet opérateur est composé avec l’opérateur renforce à l’étape 4 par une opération de composition (>B) de façon à former un opérateur complexe (B (C* (la liberté)) renforce). Deux autres opérations respectivement (>B) et (>) suivent.
À l’étape 7 commence la réduction des combinateurs. Cette série de réduction se fait dans le génotype.
À l’étape 11 nous produisons la structure prédicative dont nous aurons besoin pour aider le terminologue.
Un traitement complet basé sur la Grammaire Catégorielle Combinatoire Applicative s’effectue en deux grandes étapes :
(i) la première étape s’illustre par la vérification de la bonne connexion syntaxique et la construction de structures prédicatives avec des combinateurs introduits à certaines positions de la chaîne syntagmatique,
(ii) la deuxième étape consiste à utiliser les règles de b-réduction des combinateurs de façon à former une structure prédicative sous-jacente à l’expression phénotypique. L'expression obtenue est applicative et appartient au langage génotype. La GCCA engendre des processus qui associent une structure applicative à une expression concaténée du phénotype. Il nous reste à éliminer les combinateurs de l'expression obtenue de façon à construire la "forme normale" (au sens technique de la b-réduction) qui exprime l'interprétation sémantique fonctionnelle. Ce calcul s'effectue entièrement dans le génotype. Les formes applicatives obtenues en bout de parcours seront retenues pour être stockées dans des bases de données à des fins d’aide terminologique à l’utilisateur.
4. Le modèle Hybride
Dans sa forme concrète le modèle hybride que nous proposons consiste en deux grandes étapes :
- Un filtrage numérique grossier du corpus qui permet de classifier et de structurer le corpus en des classes de termes qui serviront d’indices de régularités d'associations lexicales que le terminologue peut utiliser comme tremplin pour approfondir les étapes ultérieures d'interprétation, de construction de réseaux sémantiques, et finalement d'élaboration de ses fiches terminologiques. Une plate-forme réalisée au LANCI, en l’occurrence, la plate-forme ALADIN (Meunier, J.G., Seffah, A., 1995) permet d’exécuter une chaîne de traitement qui réalise un tel filtrage. La chaîne présente les étapes suivantes : elle commence par une gestion du document, suit alors une description morphologique (lemmatisation) et une transformation matricielle du corpus. Vient ensuite une extraction classificatoire par réseaux de neurones FUZZYART. Ainsi dans la première étape de sa gestion, le texte est reçu et traité par des modules d'analyse de la plate-forme ALADIN-TEXTE. Cette plate-forme est un atelier qui utilise des modules spécialisés dans l'analyse d'un texte. Dans un premier temps, un filtrage sur le lexique du texte est fait. Par divers critères de discrimination, on élimine du texte certains mots accessoires (mots fonctionnels ou statistiquement insignifiants, etc.) ou ceux qui ne sont pas porteurs de sens d'un point de vue strictement sémantique, et dont la présence pourrait nuire au processus de catégorisation, soit parce qu'ils alourdiraient indûment la représentation matricielle, soit parce que leur présence nuirait au processus interprétatif qui suit la tâche de catégorisation. Vient ensuite une description morphologique minimale de type lemmatisation.
Puis une transformation est opérée pour obtenir une représentation matricielle du texte. Cette transformation est encore effectuée par des modules d'ALADIN explicitement dédiés à cette fin. On produit ainsi un fichier indiquant pour tout lemme choisi sa fréquence dans chaque segment du texte. Suit ensuite un post-traitement pour construire une matrice dans un format acceptable par le réseau de neurone FUZZYART.
Le réseau neuronal génère une matrice de résultats qui représentent la classification trouvée. Chaque ligne (ou vecteur) de cette matrice est constituée d'éléments binaires ordonnés. La ligne indique pour chaque terme du lexique original s'il fait ou non partie du prototype de la classe. Ainsi est créé un "prototype" pour chacune des classes identifiées. On dira alors que la classe no. X est "caractérisée" par la présence d'un certain nombre de termes. Autrement dit, chaque classe identifie quels sont les termes qui se retrouvent dans les segments de textes qui présentent, selon le réseau de neurones une certaine similarité. Ainsi, les classes créées sont caractérisées, arbitrairement, par les termes qui sont présents également dans tous les segments du texte qui ont été "classifiés" dans une même classe.
Les résultats du réseau de neurones se présentent donc (avant interprétation) sous la forme d'une séquence de classes que l'on dira "caractérisées" par des termes donnés et incluant un certain nombre de segments.
- Un traitement linguistique plus fin des segments sélectionnés selon les thèmes choisis par le terminologue. Ce dernier sélectionne donc des segments dont il veut une analyse plus fine et en extraire une représentation des connaissances plus structurée. Le terminologue peut décider pour un segment donné de focaliser son attention sur un terme donné et en construire son réseau sémantique. La Grammaire Catégorielle Combinatoire Applicative peut organiser les phrases dans lesquelles apparaît le terme, choisi par le terminologue, sous forme de structures prédicatives 'Prédicat argument1 argument2... argumentn'. Ainsi pour une sélection de phrases on peut engendrer une liste d’expressions prédicatives. Nous pouvons avoir dans cette liste des structures prédicatives ayant des arguments en commun.
Par exemple le cas suivant :
Prédicat1 argument1 argument2
Prédicat2 argument3 argument1
et là un terminologue comprendrait la relation sémantique entre les arguments 2 et 3 par rapport à l’argument 1.
Nous pouvons conserver une liste d’expression de la forme 'Prédicat argument1 argument2... argumentn' dans une base de données.
Le terminologue la consultant peut déduire le sens sémantique de chaque argument (donc terme) en ce sens qu’il peut en construire le réseau sémantique.
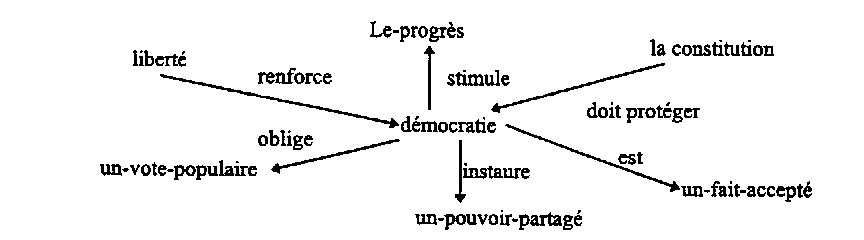
Prenons les phrases suivantes :
La liberté renforce la démocratie.
La démocratie stimule le progrès.
La démocratie oblige un vote populaire.
La démocratie est un fait accepté.
La constitution doit protéger la démocratie.
La démocratie instaure un pouvoir partagé.
Les structures prédicatives de ces phrases obtenues par une analyse linguistique catégorielle sont respectivement :
renforce (la démocratie) (la liberté)
stimule (le progrès) (la démocratie)
oblige (un-vote-populaire) (la démocratie)
est (un-fait-accepté) (la démocratie)
(doit protéger) (la démocratie) (la constitution)
instaure (un-pouvoir-partagé) (la démocratie)
un terminologue ayant dans sa base de données ces deux structures prédicatives pourra représenter le réseau sémantique de (la démocratie).
Remarque : De tels exemples cependant ne mettent pas en évidence la pertinence de l'approche par classifieurs numériques car il n'y a pas d'ambiguïté dans les exemples. Le mot pole démocratie a un sens unique.
Prenons le mot pole ferme, nous pouvons avoir trois groupes possibles :
Groupe 1 : Une démocratie ferme est l'espoir d'un peuple.
Un vote ferme est passé à l'assemblée.
C'est une position ferme du gouvernement.
Groupe 2 : Les paysans ont occupé les fermes et les villages.
Toutes les fermes ont abandonné leur récolte.
Les fermes sont laissées à l'abandon.
Groupe 3 : Le vote ferme la discussion.
La décision du gouvernement ferme les options.
Le président de l'assemblée ferme le vote.
C'est le traitement classifieur qui a permis de séparer les champs lexicaux en trois groupes. Mais c'est au moyen de la grammaire catégorielle combinatoire applicative qu'une analyse en profondeur sera faite.
5. Conclusion
Nous venons de présenter un modèle d’extraction des connaissances pour terminologues. L’idée d’associer des modèles linguistiques à des modèles numériques est très prometteuse. Elle est également très pertinente, en ce sens qu’elle associe la finesse d’analyse des méthodes linguistiques à la capacité des méthodes numériques d’absorber de gros corpus. L’ordre stratégique d’appliquer une méthode numérique avant de faire intervenir une méthode linguistique résulte du compromis nécessaire pour faire 'cohabiter' ces deux approches. En effet, la méthode numérique est plus à même de 'débroussailler' un gros texte et de permettre à un terminologue de soumettre des segments choisis à l’analyseur linguistique plus fin.
Ce type d'approche permet de répondre à l'une des critiques importantes qu'on fait classiquement aux approches de cooccurrence et collocation : leurs difficultés d'interprétation. Notre approche permet d'entrevoir des outils de raffinement de l'analyse des résultats livrés par les approches numériques trop grossières et générales. Il y a compensation entre les deux. Les Grammaires Catégorielles sont trop fines et donc trop lentes sur un corpus ample. Mais bien placées elles ne travaillent que sur des sous-corpus qui ont effectué un premier travail de désambiguisation.
En fait cette approche oblige à effectuer la désambiguisation dans un traitement différent de celui de la grammaire. La désambiguisation joue sur la différentialité des contextes de l'ensemble d'un corpus (relation paradigmatique) alors que l'analyse catégorielle opère sur la dépendance des contextes immédiats (relation syntagmatique). Ainsi, le système n'est pas obligé de faire les deux analyses en même temps ou dans une même passe ce qui, pensons nous, le rend plus efficace.
Enfin la configuration des résultats telle que permise par les expressions prédicatives permet au lecteur analyste d'avoir une organisation plus limpide sur le plan ergonomique et cognitif. On envisage la possibilité de lire ces résultats dans des réseaux structurés mais aussi dans des reposoirs structurés genre dictionnaires, thesaurus, bases de connaissances, etc.
Références
Biskri, I., (1995). La Grammaire Catégorielle Combinatoire Applicative dans le cadre de la Grammaire Applicative et Cognitive, Thèse de Doctorat, EHESS, Paris.
Bouchaffra, D. (1993). Theory and Algorithms for analysing the consistent Region in Probabilistic Logic. An International Journal of Computers & Mathematics with applications, vol. 25, February, edit. Ervin Y. Rodin, Published by Pergamon Press.
Burr, D. J. (1987). Experiments with a connectionnist text reader. IEEE First International Conference on Neural Networks, San Diego, 717-24
Carpenter, G., Grossberg, G. (1991). An Adaptive resonnance Algorithm for Rapid Category Learning and Recognition. Neural Networks 4, 493-504.
Cheeseman, P., Self, M., Kelly, J., Stutz, J, Taylor, W., Freeman, D. (1988). Bayesian Classification. Proceedings of AAAI 88, Minneapolis, 607 -611
Church, K., Gale, W., Hanks, P., & Hindle, D., (1989). Word Associations and Typical Predicate-Argument Relations. International Workshop on Parsing technologies, Carnegie Mellon University, Aug. 28-31,
Church, K. W., & Hanks, P. (1990).Word association norms, mutual informaton, and lexicography. Computational Linguistics 16, 22-29.
Curry, B. H., Feys, R., (1958). Combinatory logic, Vol. I, North-Holland.
Delany, P. Landow (1993). The Digital Word : Text Based Computing in the Humanities. Cambridge, Mass : MIT Press.
Descles, J. P., (1990). Langages applicatifs, langues naturelles et cognition, Paris : Hermes.
Garnham, A. (1981). Mental models and representation of texts. Memory and Cognition 9 (560-565).
Grossberg, S., Carpenter, S. (1987). Self Organization of Stable Category Recognition Codes for Analog Input Patterns. Applied Optics 26, 4919- 4930.
Jacobs, P., Zernik. U. (1988). Acquiring Lexical Knowledge from Text A case Study. Proceedings of AAAI 88 (St Paul. Min.).
Jansen, S., Olesen, J., Prebensen, H., & Tharne, T. (1992). Computanional approaches to text Understanding. in Copenhaguen : Museum Tuscalanum Press.
Kohonen, T. (1982). Clustering, taxonomy and topological Maps of Patterns. IEEE Sixth International Conference on Pattern Recognition, 114-122.
Lebart, L., Salem, A. (1988). Analyse statistique des données textuelles. Paris : Dunod.
Meunier, J.G (1996). Théorie cognitive : son impact sur le traitement de l'information textuelle, in V. Riale et D. Fisette Penser L'esprit, Des sciences de la cognition a une philosophie cognitive. Presses de Université de Grenoble. 1996, 289-305.
Moulin B, Rousseau, D. (1990). Un outil pour l'acquisition des connaissances a partir de textes prescriptifs. ICO, Québec 3 (2), 108-120.
Recoczei, S. et al., (1988). Creating the Domain of Discourse : Ontology and Inventory. In J. &. B. G. Boose (Ed.), Knowledge Acquisition Tools for Experts and Novices. Academic Press.
Salton, G. (1988). On the Use of Spreading Activation. Communications of the ACM vol 31 (2).
Salton, G., Allan, J., Buckley, C. (1994). Automatic Stucturing and Retrieval of Large Text File. Communications of the ACM 37 (2), 97-107.
Seffah, A., Meunier, J.G., (1995). ALADIN : Un atelier orienté objet pour l'analyse et la lecture de Textes assistée par ordinateur. International Conferencence On Statistics and Texts. Rome 1995.
Shaw, M. L. G., Gaines, B. R., (1988).Knowledge Initiation and Transfer Tools for Expert ad Novices. In B. Gaines (Ed.), Knowledge Acquisition Tools for Expert Systems. Academic Press.
Steedman, M., (1989). Work in progress : Combinators and grammars in natural language understanding, Summer institute of linguistic, Tucson University.
Veronnis, J., Ide, N. M., & Harie, S. (1990). Utilisation de grands réseaux de neurones comme modèles de représentations sémantiques. Neuronimes.
Zarri, G. P., (1990). Représentation des connaissances pour effectuer des traitements inférentiels complexes sur des documents en langage naturel in Office de la langue française (Ed. Les industries de la langue. Perspectives 1990. Gouvernement du Québec).