RECHERCHE DE SIMILITUDES ENTRE FRAGMENTS DE DOCUMENTS
H. Betaille, A.M. Massotte, A. Joubert
LIRMM
UMR CNRS / Université Montpellier II
161 rue Ada, 34392 Montpellier Cedex 5 FRANCE
Email : {betaille, massotte, joubert}@lirmm.lirmm.fr
Résumé
This paper is aimed at developing a new approach to help scientists and people working in Industry to retrieve easily information recorded in documents. Several techniques based on work conducted by specialists such as G.Salton and J.F.Sowa have been experimented. However, it is demonstrated that searches based on similarities enable to get more relevant and pertinent information for a pre-defined sentence, in a given situation. More precisely, similarities are determined through a weighted calculation taking into account i) the grammatical processing of the text and ii) the importance of the words according to their rôle in the structure of the sentence and their field of interest. A tool called SIMILIDOC has been developed. It enables the analysis and the indexing of new documents depending on their context. SIMILIDOC has been used to perform text processing in the area of quality assurance, in entreprise. The best granularity, at paragraph level, could be defined in order to retrieve the most pertinent information.
Le problème et ses objectifs
Dans une entreprise, les ingénieurs sont amenés à consulter de nombreux documents pour trouver une information pertinente et complète sur un sujet donné. Les techniques statistiques dérivées des travaux de Salton [G.Salton] et l'indexation par graphes de Sowa [J.F.Sowa] sont mal adaptées à un corpus évolutif de petits documents devant prendre en compte un vocabulaire spécifique à l’entreprise et fournir une indexation précise. C’est pour pouvoir traiter ce cas que nous avons développé l'outil "Similidoc". Cet outil a été appliqué sur des textes concernant l’assurance de la qualité pour une entreprise.
Les documents consultés dans une entreprise par les ingénieurs et les concepteurs, mais également les techniciens et les utilisateurs sont non seulement des ouvrages de référence, mais aussi de nombreuses notes internes sous la forme de courrier électronique ou de documents informatiques pour lesquels se pose un problème spécifique d'indexation. Les documents comportent souvent des informations redondantes ou contradictoires, et il est difficile de fournir une synthèse sur un sujet donné.
Une indexation manuelle par mots clés serait fastidieuse. Ces mots clés, généralement définis par un expert, peuvent être assimilés à des ancres au sens des hypertextes. Les techniques statistiques sont adaptées à des corpus de grande taille [A.Griffiths] qui par leur volume compensent statistiquement l'imprécision de l'indexation automatique (recherche des chaînes de caractères sans avoir à tenir absolument compte de leur sens) : le repérage se fait par rapport aux documents plutôt que par rapport aux phrases ou aux paragraphes qui les composent. De plus, les documents pris en compte ne peuvent évoluer, ils sont figés définitivement. L'indexation par graphes de Sowa est très précise pour des textes courts se rapprochant de phrases. Mais au préalable à toute analyse, le document doit être représenté sous forme de graphe. Actuellement, aucun outil n'effectue automatiquement cette transformation pour des textes quelconques et l’indexation doit s’effectuer manuellement.
Ces méthodes sont donc mal adaptées à un corpus évolutif de petits documents. Lors de la recherche d’informations, il faut prendre en compte non seulement le vocabulaire spécifique au domaine mais aussi celui utilisé dans l’entreprise par les équipes qui ont rédigé les documents. L'ensemble de documents sur lequel s’effectue la recherche est de taille limitée mais plusieurs ensembles de documents doivent pouvoir coexister. On recherche ici une indexation de granularité fine (plutôt de la taille du paragraphe), permettant l'établissement de relations entre fragments de documents. Ces relations doivent être intra-documents autant que entre documents.
Pour améliorer la précision de l’indexation, il est nécessaire de mieux caractériser les éléments sur laquelle elle porte, c’est-à-dire les termes (mot, groupe de mots, phrase, paragraphe... suivant le contexte) au moyen de techniques linguistiques en combinant des techniques d'analyse de la langue naturelle avec des méthodes statistiques.
Le système développé a pour objectif la recherche de similitudes entre parties de documents. A chaque recherche, il y a création de liens dynamiques entre les parties de documents suivant leur degré de similitude au sens du système. Il faut donc être capable d’évaluer cette valeur et c’est pour cela que, dans un premier temps, il est nécessaire d’indexer les textes et de réaliser autant que possible, cette indexation automatiquement. Cela nécessite l'utilisation d'un thésaurus qui n'est pas disponible directement car le vocabulaire utilisé est spécifique à chaque entreprise même si celles-ci travaillent dans le même domaine. Il faut donc le construire de façon incrémentale. Comme les mécanismes automatiques ne sont pas fiables, il ne s'agit que d'une aide à l'utilisateur dans la création de son propre thésaurus. D’autant que, s’il est expert, il doit pouvoir remettre en cause les résultats de l'indexation automatique et ne la valider qu’après vérification. S’il n’est qu’utilisateur, une interface homme-machine hypertextuelle simple [M.Zizi] lui permettra de consulter directement les documents ou le résultat d'une recherche.
Construction incrémentale du dictionnaire contenant le vocabulaire
Pour indexer un nouveau document, le dictionnaire du vocabulaire significatif est construit incrémentalement au fur et à mesure de la rencontre de nouvelles racines. Mais il est préférable, pour commencer à le construire, de demander à un expert de choisir un ou plusieurs documents représentatifs du vocabulaire de l’entreprise. Ces documents vont être analysés et les mots vont être répartis en plusieurs classes. Le vocabulaire est constitué par des mots ou des groupes de mots réduits à leur racine grammaticale :
∑
Les mots "rejetés": ce sont des mots qui n’apportent aucune information significative dans le texte. Ce sont des mots comme : de, le, un, alors, avant, selon, etc... Ces mots sont a priori rejetés, ce qui signifie que lors de l’analyse d’un nouveau document, ces mots sont éliminés du texte pour le simplifier. Sont donc classés dans cette catégorie uniquement des mots qui seront ignorés quel que soit le texte et le domaine.∑
Les mots "ignorés": ce sont des mots qui dans le cas particulier du domaine concerné et du groupe de documents traités sont considérés comme des mots non significatifs. Par exemple, le mot "adhésif" n’a pas d’intérêt particulier pour le vocabulaire utilisé dans les textes analysés. Cette classe de mots a été introduite pour éviter une spécialisation de l'outil à un domaine ou un vocabulaire particulier.∑
Les mots "du domaine": sont considérés comme tels des mots "du domaine" aussi bien des mots simples que des groupes de mots qui présentent une signification importante pour le domaine. Par exemple : qualité, achat, fournir (au sens de fourniture), assurer (au sens de l’assurance), commande, document, sont des mots simples. Certains groupes de mots sont significatifs, par exemple : l’assurance de la qualité, la qualité totale, les documents techniques. Les locutions peuvent être de 1, 2, 3 mots ou plus.∑
Les mots "secondaires": ce sont des mots qui pris isolément appartiendraient aux mots ignorés car peu porteurs de sens. Par contre, ces mots prennent un sens lorsqu’ils sont associés à un mot du domaine et dans ce cas, leur sens devient très important. Par exemple, le mot cadre seul n’a pas grande signification du point de vue du domaine, par contre il prend un sens important dans le groupe de mots contrat cadre. Il peut aussi avoir d’autres sens dans l'entreprise lorsqu’il est associé à des mots différents et dans ce cas appartenir aux mots du domaine : la caisse des cadres.∑
Les "cooccurrences": ce sont des mots qui sont fréquemment utilisés au voisinage d’un mot du domaine. Par exemple, le mot qualité est un mot du domaine et l’on s’aperçoit que sur 197 occurrences de ce mot, 50 étaient proches du mot assuré, 24 du mot achat, 22 du mot total et 20 du mot produit. En fait, la plupart des textes concernent l'assurance de la qualité ou la qualité totale des achats.∑
Les mots "nouveaux": ils correspondent aux mots qu'il n'est pas possible de répartir dans les classes précédentes lors de l'interprétation informatique d'un nouveau document. C'est donc à l'expert, par une intervention manuelle, de rediriger le vocabulaire nouveau vers les classes précédemment décrites.L'indexation basée sur l'analyse grammaticale
Le calcul des similitudes entre paragraphes utilise des techniques statistiques, mais il fait appel au préalable à un traitement grammatical pour compenser l'imprécision statistique de l'élaboration d'un vecteur de mots clés.
Lors de cette phase d'analyse grammaticale d'un document, les mots sont réduits à leur racine. Les mots rejetés et ignorés ne sont pas pris en compte. Par exemple, parmi les mots du domaine, la racine fournir qui apparaît 113 fois se présente sous la forme de fournir, fourni, fournit, fournitures, fournisseurs. Cela permet de savoir combien de fois apparaît chaque mot au sens de sa racine. Lors de l'analyse d'une phrase, les mots sont répartis en groupes grammaticaux et la phrase est représentée sous la forme d'un vecteur de mots-clés.
L'indexation de la phrase s'effectue en pondérant son importance suivant l'intérêt pour le domaine des mots la constituant et à la suite le traitement du texte comporte :
∑
la détermination automatique des mots prépondérants (appelés entités pertinentes) et de leur importance. Cette dernière dépend de la profondeur des mots dans l’arbre de dérivation de la phrase et de leur fonction dans la phrase ;∑
l'association d'un mot-clé à chaque racine lexicale. Si une racine possède plusieurs sens (cas des homonymies), il sera associé à cette racine autant de mots-clés que de sens qu’elle possède ; ainsi, à chaque mot-clé correspond une liste de racines synonymes ;∑
le calcul de la représentation de chaque fragment du nouveau document : le calcul est fait pour chacun des mots du fragment ; on détermine ainsi une liste de mots-clés avec des coefficients proportionnels à leur importance sur le fragment concerné ; pour un mot-clé donné, ce coefficient correspond à la sommation, sur le fragment de document, des importances des différentes occurrences des racines associées à ce mot-clé ;∑
l’indexation proprement dite : en final, à chaque mot-clé sont associés les fragments de document qui lui correspondent ; chacune de ces associations est pondérée par le coefficient (calculé lors de la représentation du fragment) proportionnel à l’importance du mot-clé sur le fragment.
Le calcul des similitudes
Il utilise les mots significatifs précédemment définis. Ce calcul est lancé par l’utilisateur final qui après sélection d’un passage de texte demande au système de lui fournir les textes qu’il juge semblables. La similitude entre fragments de documents est alors calculée :
∑
en fonction du taux de présence du mot au sens de sa racine.∑
en fonction des formes grammaticales utilisées : les formes substantives, les plus porteuses d’information, les adjectifs qui amènent des informations complétant le substantif et les verbes qui ont en fait peu d’importance dans le document lui-même.∑
en fonction de la distribution du mot. Un mot qui apparaît de façon homogène dans le texte, c’est-à-dire dispersé à l’intérieur du document, sans probabilité particulière sur un petit nombre de documents est un mot peu significatif. A l’opposé, un mot qui n'est présent que localement à certains endroits, est un mot qui apporte beaucoup plus d’informations pour discriminer le document.∑
en fonction du sens des mots et non de la proximité lexicale∑
en fonction de l'importance du mot dans le domaineOn va associer à la comparaison de deux fragments de documents un coefficient de similitude qui sera d’autant plus fort que les deux fragments sont sémantiquement plus proches l’un de l’autre. On utilise la représentation précédemment calculée de chacun des fragments par une liste de mots clés avec leurs coefficients d’importance respectifs.
C’est-à-dire que si deux fragments de document ont pour représentation :
Fragment1 = { (motclé11,coeff11),(motclé12,coeff12),...,(motclé1i,coeff1i),... }
Fragment2 = { (motclé21,coeff21),(motclé22,coeff22),...,(motclé2j,coeff2j),... },
alors le coefficient de similitude entre les deux fragments pourrait être de la forme :
S
(pour motclé1i = motclé2j) coeff1i * coeff2jValidation de l'indexation des documents
Lors de la construction du dictionnaire et de la représentation des documents que nous noterons base de documents, l'intervention d'un expert est nécessaire pour valider l'analyse de chaque document. Il pourra être amené à :
∑
modifier l’importance d’un motLors de l’introduction d’un nouveau texte, le logiciel calcule automatiquement l’importance des mots. L’expert a la possibilité de modifier cette importance, estimant qu’elle a été sur- ou sous-évaluée. Ainsi, par exemple, dans la qualité du logiciel de dessin utilisé au secrétariat, l’importance déterminée automatiquement pour le mot secrétariat est très faible. Si l’expert tient à souligner que dans ce paragraphe il est prépondérant de tenir compte de ce mot, il aura la possibilité de modifier manuellement son importance.
∑
enlever les ambiguïtés :L’expert a également un rôle à jouer dans la levée des ambiguïtés. En effet, si à une même racine rencontrée plusieurs fois dans les textes précédents, l’expert a fait correspondre plusieurs sens différents, plusieurs mots-clés seront associés à cette racine. Lors d’une nouvelle occurrence de celle-ci, le logiciel ne pourra pas décider automatiquement quel mot-clé lui associer. Dans un fragment, à une occurrence de racine ne sera associé qu’un seul sens, et donc un seul mot-clé ; lors de la première occurrence d’une racine présentant une ambiguïté, l’expert devra intervenir pour définir quel sens il associe à cette racine.
∑
établir la liste des synonymes :L’expert associe un mot-clé à chaque nouvelle racine rencontrée. Si une racine possédant un sens analogue est déjà présente dans le dictionnaire, plutôt que de spécifier le mot-clé de la nouvelle racine, l’expert aura la possibilité d’indiquer que cette nouvelle racine est synonyme d’une racine déjà rencontrée. Ainsi sont constituées des listes de synonymes.
Dans le cas de l'ajout de nouveaux documents, le travail précédent peut même, au besoin, être réalisé par l'utilisateur final car les nouveaux mots sont présentés "en contexte". Toutefois l'assistance d'un expert est profitable. En effet, Similidoc considère les mots contextuellement : certains qui, pris isolément, seraient ignorés prennent un sens lorsqu'ils sont associés à des mots du domaine.
L'outil Similidoc
En réponse à une demande, la recherche d’informations cohérentes, pertinentes et prenant en compte les éventuelles corrections ou mises à jour, doit souvent être effectuée dans un minimum de temps.
L'outil Similidoc permet la consultation et la modification d'une base de documents ainsi que l'analyse de nouveaux documents sans pour autant qu’il soit nécessaire de devoir réindexer la totalité de la base à chaque fois. Il permet l'accès à des informations précises pour aider à la réalisation d'une tâche comme la rédaction d'un document de synthèse ou l'obtention d'informations pertinentes pour une situation donnée.
L’outil s’adresse à deux types d’utilisateurs, l’expert qui construit ou met à jour la base de données et l’utilisateur normal qui utilise cette base pour son travail.
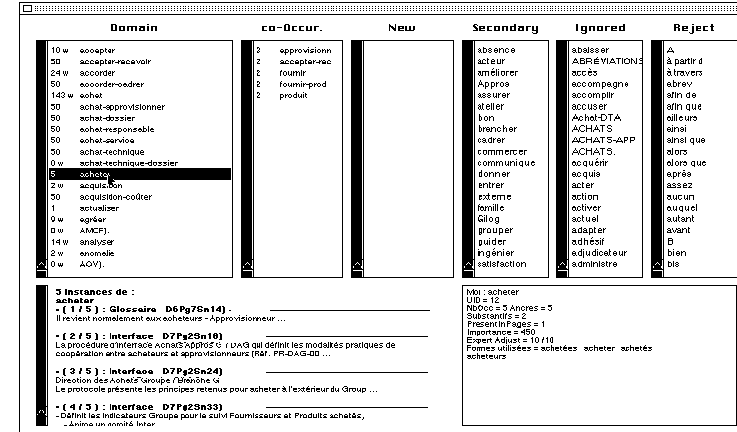
Lors de la phase de création de la base, le système fait, dans un premier temps, une pré-analyse automatique des documents qui conduit à l’établissement des listes de vocabulaire qui devront être validées par l’expert. La figure1 qui suit présente un exemple de ces listes avec la sélection d’un mot.
Figure 1 Le vocabulaire
Dans un deuxième temps, le système étant déjà amorcé, l’expert reprend chaque document pour effectuer leur analyse afin de mémoriser les informations relatives aux cooccurrences, aux documents eux-mêmes, aux locutions multiples (assurance de la qualité,...), aux synonymies entre mots. Lorsqu’il est nécessaire d’introduire un nouveau document (ou plusieurs ce qui est plus intéressant) dans le système, celui-ci analyse le vocabulaire et demande à l’expert de prendre une décision concernant les mots nouveaux qu’il n’a pu affecter.
En mode d’exploration de documents, d’utilisation de la base déjà créée, l’utilisateur peut consulter librement chacun des documents de la base ou d’un groupe de documents page à page (dans la base, les documents peuvent être affectés à un groupe cela permet par exemple, de limiter les recherches à un sous-ensemble de documents choisis au préalable).
Par soucis de convivialité, plutôt que d'expliciter une requête, l'utilisateur choisit dans une page un fragment de texte correspondant à un concept. Cette sélection est transformée en requête par analyse des mots clés. Une fois cette requête formulée, le système calcule quelles sont toutes les réponses potentielles et fournit la liste ordonnée par pertinence décroissante des passages similaires à sa sélection. La figure 2 qui suit est un exemple de ce qui précède.

Figure 2 Sélection d’un fragment de texte et recherche de similitudes
Il peut alors naviguer directement vers ceux-ci grâce à une interface homme-machine hypertextuelle simple.
Conclusion
Similidoc est un outil d'aide intégré, pour une personne qui doit effectuer un certain travail à partir de documents dont certains lui sont propres, avec sa propre indexation, et qui d’autre part, partage avec les autres utilisateurs le dictionnaire du vocabulaire de l’entreprise. De plus, lors de la consultation de la base de documents, si l’utilisateur s'aperçoit que l'indexation n'a pas été correctement réalisée, pour en obtenir une meilleure, il lui est possible de modifier un certain nombre de critères.
Cet outil a été utilisé pour effectuer des rapprochements entre des textes relatifs à l'assurance qualité. La granularité choisie est celle du paragraphe. Une baisse de précision est observable pour des paragraphes courts dont le contexte est trop limité. En contrepartie, la délivrance directe des paragraphes supposés pertinents est un atout important par rapport à celle de textes complets.
Cet outil est bien adapté à des corpus de taille limitée, mais du fait de la granularité de l’analyse qui permet de travailler au niveau du fragment de texte, son utilisation peut paraître coûteuse. En conséquence, elle ne serait pas possible sans baisse de performance notable sur des corpus de grande taille, à moins d’apporter des améliorations à l’indexation d’une part, et de compter sur l’utilisation de matériels plus performants d’autre part.
Références
Griffiths, A., Luckhurst, H.C., Willet, P. (1986). Using inter-document similarity information in document retrieval systems. Journal of the American Society for Information Science 37 : 3-11. |
Salton, G., Allan, J. (1994). Automatic text theme decomposition and structuring. RIAO-94 6-20 Centre d’Information Documentaire, Paris. |
Salton, G., Buckley, G. (1993). Term-weigthing approaches in automatic text retrieval. Information Processing and Management 24(5) : 513-523. |
Salton, G., Singhal, A., Buckley, C., Mitra, M. (1996). Automatic text decomposition using text segments and text themes. Hypertext’96 ACM. |
Salton, G. (1989). Automatic text processing : the transformation, Aanalysis and retrieval of information by computer. Addison-Wesley, Reading, MA. |
Sowa, J.F. (1984). Conceptual Structures. Addison Wesley. |
Zizi, M., Beaudoin-Lafon, M. (1994). Accessing hyperdocument through interactive dynamic maps. ECHT94 Proceedings ACM. |