EXPLORATION STATISTIQUE DE BASES DOCUMENTAIRES
Yves Baulac - Jean Moscarola
Sphinx Développement - Université de Savoie
7, rue Blaise Pascal 74600 Seynod
Summary
The use of textual data bases make it difficult to get a synthetic knowledge of their content. That is always the fact when the search cannot be defined by a single query.
Textual datamining technics can be very efficient in such a situation. The purpose of it, is to lead navigation into the data and to work out synthesis using the explicite or implicite structuration of the data base and of its content.
In a first part we are going to define typical structuration which can be recognised to show how they can be used by the textual datamining tools.
In the second part of the paper an exemple of the use and efficiency of these technics will be given with regard to the field of bibliography analysis.
L'accès aux grandes bases de données documentaires ou bibliographiques (Internet, CD Rom) est de plus en plus facile et aisé. Mais le mode d'accès par requête nécessite d'avoir une idée précise de ce qu'on y recherche, dans le cas contraire on est vite submergé par une masse d'informations. Comment alors aider celui qui doit prendre connaissance des centaines de références bibliographiques pertinentes pour son sujet, ou l'entreprise qui veut connaître la tendance des dépôts de brevet concernant son secteur d'activité ?
Les corpus issus des bases de données documentaires ont l'avantage de posséder une structuration très forte dont on peut tirer parti. Mais nous verrons que cette structure est complexe et imprécise et que sa reconstitution dans le logiciel d'analyse de données textuelles n'ira pas toujours sans mal.
Nous avons été confrontés à ces questions en tant que concepteurs et utilisateurs du Sphinx Lexica. Nous adopterons successivement ces deux points de vue en décrivant dans une première partie les aspects techniques du problème puis en les illustrant par un exemple tiré de la base ELECTRE.
Structure d'un corpus issu d'une base documentaire
Tous les travaux portant sur l’analyse de données textuelles conviennent que la première tâche à accomplir avant toute statistique est une préparation du texte que l’on appellera selon les cas une structuration, un formatage, une segmentation, une identification des unités statistiques.
Nous ne parlons pas ici du découpage en unités lexicométriques (chaîne, forme, mot, lemme, segment) mais du découpage préalable en fragments de texte qui pourront être retrouvés et/ou comparés les uns aux autres en fonction des unités lexicométriques qu’ils contiennent.
Cette phase, un peu à l’instar du nettoyage d’un jeu de données en statistique quantitative, est souvent passée sous silence. Soit parce que la segmentation est évidente (par exemple si elle est fondée sur la notion de fichier informatique), soit parce qu’elle est préétablie d’une manière irréfutable (par exemple par des séparateurs facilement identifiables), soit parce qu’elle est effectuée manuellement, soit parce qu’elle est absente (étude d’un texte unique), soit parce qu’elle est considérée comme sans influence sur les résultats de l’exploitation.
Une structuration complexe et dégradée
Le texte contient trois types de chaînes de caractères : les informations textuelles proprement dites (résumé, titre, procédé, compte rendu, … mais aussi noms, adresses, fonctions, …), le contexte (expressions alphanumériques représentant des nombres, des catégories, des codes), les balises (caractères ou chaînes de caractères séparant les différentes informations).
La tâche de repérage de ces informations est difficile. Nous avons en effet à décoder une structuration complexe, hiérarchisée, incomplète, souvent dégradée, implicite.
Pour le discours ou le recueil, l’acquisition des données passe le plus souvent par une phase manuelle de vérification du format, d’ajout des éléments de contexte qui caractérisent l’élément ou sa provenance. On profitera de ce travail dans un traitement de textes pour compléter et rectifier les éléments de découpage. Par contre, dans un corpus documentaire, l’acquisition des données est entièrement automatique : une simple requête nous donnera en quelques secondes un corpus volumineux.
Il serait fastidieux, voire décourageant, d’être obligé de pré-traiter manuellement un tel corpus. D’autant plus que l’objectif de l’analyse statistique d’une base documentaire est souvent peu ambitieux. On cherche moins une typologie des unités ou du vocabulaire qu’une prise de connaissance du contenu par le biais d’une statistique descriptive.
Une structuration dégradée
La structuration peut être totalement explicite lorsque nous accédons à la base via un SGBD ou bien lorsque le texte respecte une norme de balisage logique telle que la norme SGML.
Mais nous n’avons généralement pas un tel accès direct et complet aux grandes bases documentaires. L’analyse doit porter sur un texte qui nous est fourni en réponse à une requête. Lors de l’extraction, l’application gestionnaire de la base documentaire effectue des simplifications et des ellipses qui vont compliquer la tâche de restructuration.
Et lorsque ces bases sont accessibles dans leur intégralité, la structure du document a plutôt été prévue pour faciliter la lecture par l’homme que l’analyse par la machine. On trouvera ainsi mêlées des balises typographiques, des balises syntaxiques, des balises graphiques.
Des corpus "multitextes"
Le discours, le recueil, la question ouverte sont des corpus que nous pouvons qualifier de "monotexte". Les analyses porteront sur l’ensemble du corpus et il est vrai que les décomptes ne dépendront pas ou peu de la segmentation, qu’elle soit en paragraphes, en pages voire en unités de longueur fixe.
Par contre, un corpus documentaire est "multitexte", plusieurs variables textuelles de nature complètement différente peuvent coexister dans un même corpus. On trouvera ainsi dans un corpus issu d’une base de brevets pharmaceutiques le résumé du procédé, les coordonnées du déposant, les effets secondaires, … autant de textes qui ne sauraient être analysés ensemble.
Des contextes imbriqués
Dans la question ouverte, les variables de contexte qui sont les autres données de l’enquête auront été mises en forme lors de la saisie ; leur décodage et leur affectation à un fragment de texte est donc préétabli. Dans le discours, il n’y a pas ou peu de contexte. Dans le recueil, le contexte sera essentiellement le document, facile à identifier.
Par contre, dans un corpus documentaire les éléments de contexte, numériques ou nominaux, sont étroitement mêlés au(x) texte(s). Il ne sera pas toujours facile de les identifier comme tels et de les décoder. Les chaînes numériques ou quasi-numériques donneront lieu à des variables numériques ou codées. Les chaînes courtes avec une forte répétitivité et un faible nombre de valeurs différentes donneront lieu à des variables nominales.
Une exploitation toutefois plus simple
Les textes sont exempts de "bruit" : Il n’y a pas de chaînes de caractères inutiles comme on en trouve de manière caricaturale dans une page html.
La syntaxe, le vocabulaire, le style sont très réguliers d’un fragment à l’autre.
Le langage est simple et il n’y a pas de figures de rhétorique ou de modalités linguistiques complexes.
Les textes pourront être simplifiés : la simplification du corpus ne se pose en effet pas dans les mêmes termes que pour les textes littéraires, discursifs ou conversationnels. La polysémie y est beaucoup moins fréquente, on s’intéresse à l’énoncé et pas à l’énonciation. On est loin ici de la problématique "Faut-il lemmatiser ?", "Faut-il regrouper par racine ?", "Faut-il compter tous les mots ou bien en ignorer certains ?", "Va-t-on utiliser un thesaurus ?".
Dans la plupart des cas, on sera rapidement amené à créer de nouvelles colonnes contenant un texte simplifié qui servira de base aux décomptes et aux analyses.
Une structuration implicite
L’information contenue dans un champ contextuel n’est pas toujours utilisable telle quelle. Différents types de structuration implicite peuvent avoir été utilisés par les auteurs de la banque de données, que cette structuration implicite soit propre à la base ou systématiquement utilisée dans le domaine. Voici quelques types de structuration implicite.
Expressions régulières : le champ suit une syntaxe précise (modèle) et l’information intéressante est une des parties du modèle. Exemples : Le pays qui sera toujours mis entre parenthèses et sur deux lettres dans une adresse - La référence bibliographique qui sera toujours mise entre crochets - Le type du procédé qui sera le premier mot suivi de deux points.
Informations numériques commentées : l’information qu’il nous importe de récupérer se trouve au milieu d’un groupe de mots la décrivant ou la complétant. Exemples : Le code postal dans une adresse - Une population dans une description géographique - L’année dans une bibliographie.
Contexte multiple : le contexte est formé de plusieurs mots qui n’ont pas de signification les uns par rapport aux autres mais pour des raisons diverses (économie, provenance, sémantique,…) apparaissent dans le même champ séparés par un espace ou tout autre caractère non utilisé dans le libellé de l’information. Il sera nécessaire de scinder ce champ en plusieurs variables, chacune reprenant les informations de même nature. Exemples : Titre et auteur ; Nom et qualité ; Poids et âge.
Les écueils
Il est évident que les écueils ne manquent pas et que la liste est sans fin. Nous citons dans cette partie les principaux obstacles auxquels nous avons été confrontés.
Champs communs à plusieurs fiches
La structuration du corpus initial en fiches et en champs peut s’accompagner d’une structuration plus large en thèmes, en parties, en années. Ce contexte de niveau supérieur ne sera pas répété à chacune des fiches. Il s’agit de jalons dont la valeur devra être propagée pour toutes les fiches jusqu’à la prochaine occurrence.
Utilisation de balises typographiques et semi-graphiques
Quand une base documentaire est intégralement à notre disposition, il arrive fréquemment que les éléments de structuration ne soient pas repérés par une syntaxe particulière qui dénaturerait le texte et en compliquerait la lecture mais par une typographie. Les grandes sections du corpus ou les noms des champs pourront ainsi apparaître dans une police ou un corps qui les distinguent du reste du texte.
Utilisation d’une syntaxe non réservée pour les balises
On trouvera souvent des corpus balisés tout simplement par le nom du champ sur une nouvelle ligne suivi de deux points.
Le problème vient du fait que l’on trouvera une syntaxe similaire, voire identique, à l’intérieur d’un champ. Si une simple lecture permet à l’homme de différencier une balise rare et une partie du texte, la machine utilisera la reproductivité de ces singularités pour proposer de conserver ou non cette balise hypothétique.
Type des variables de contexte
Si les variables de contextes sont typées dans la base de données initiale, le type n’apparaît plus dans le corpus que nous devons structurer. L’analyse de l’ensemble de la colonne permettra de déterminer la nature numérique, nominale, codée ou textuelle du champ. Mais seul l’utilisateur pourra déterminer si un ensemble de chiffres est un nombre sur lequel il y a effectivement un ordre ou bien un code qui sera interprété.
Information répartie dans plusieurs champs
Par exemple l’information sur la provenance géographique d’un brevet se trouve à la fois dans le champ "Déposant" et dans le champ "Inventeur". Avant de pouvoir exploiter le corpus, il sera nécessaire de concaténer ces deux champs dans une nouvelle colonne de notre feuille de données textuelles.
Exceptions volontaires
Des exceptions, volontairement présentes dans la base de données peuvent perturber par exemple un ensemble de valeurs numériques. Citons deux cas :
∑
Des informations textuelles sont ajoutées pour marquer un intervalle, une imprécision, un complément d’information (De 20 à 50 ; >100 ; Environ 300 ; 20000 en 1996)∑
Un changement d’unité intervient pour les quelques observations qui ont des valeurs très différentes des autres (20KF ; 3MF ; 450KF ; 2KF)L’intervention de l’utilisateur
Nous espérons avoir montré que le processus est très complexe et qu’il n’y a pas dans le cas général de solution complètement automatisable. Le programme d’intégration ne saurait être une boite noire et l’intervention de l’utilisateur sera déterminante. Dans certains cas, la complexité du traitement empêche d’ailleurs sa programmation par des choix multiples dans un dialogue.
Le logiciel propose, l’utilisateur dispose
L’ordinateur effectue le calcul combinatoire de la proposition la plus vraisemblable mais l’intervention de l’utilisateur sera indispensable pour valider, compléter, rectifier les solutions proposées.
C’est l’utilisateur qui indiquera, au vu du texte, la syntaxe des balises, la syntaxe des jalons, les caractères séparateurs.
C’est l’utilisateur qui donnera, sur proposition du logiciel, la liste des balises à retenir, les autres étant en fait partie du texte proprement dit.
C’est l’utilisateur qui donnera, sur proposition du logiciel, le type de chaque contexte (nominal, numérique, code).
Démarche par approximations successives
L’expérience montre que l’on a rarement un résultat satisfaisant du premier coup. Il n’est pas rare que l’analyse lexicale mette immédiatement en évidence des mélanges de champs ou de fiches qui auront été le fait d’une singularité dans la structuration. Il faudra corriger le texte initial et de reprendre l’opération d’intégration. Cette démarche par essai-erreur ne sera effectivement adoptée que si la facilité, la rapidité et la finesse de la mise en œuvre sont au rendez-vous.
Programmation de traitements des chaînes de caractères
Les traitements souhaités ne sont pas toujours explicitables par des simples choix dans un dialogue et l'utilisateur averti sera amené dans certains cas à utiliser un langage de programmation (comme le langage Basic), principalement pour deux objectifs, la reconnaissance des balises et l’explicitation des contextes.
Reconnaissance des balises : Cette opération se déroulera dans le traitement de textes, avant l’intégration dans le logiciel d’analyse de données textuelles. Des macro-commandes (applicables globalement sur la totalité du texte) permettront de supprimer les passages inopportuns de retrouver rapidement des typographies, des régularités et de les transformer en balises reconnaissables. Ces macro-commandes sont essentiellement des combinaisons d'opérations de recherche/remplacement et d'insertion/suppression.
Explicitation des contextes : Dans le logiciel d’analyse de données textuelles, l’utilisateur aura à sa disposition un langage de programmation similaire avec des fonctions d’extraction de chaîne dans une expression régulière, par exemple pour retrouver le énième mot d’un contexte, pour retrouver le premier nombre cité, pour supprimer les parties du texte entre parenthèses.
L’analyse lexicale pour la reconnaissance de la structure implicite des contextes
Les structures régulières ne permettent pas toujours de mettre en évidence les éléments pertinents dans un contexte. On sera amené à utiliser les techniques d’analyse lexicale pour le traitement de ces contextes complexes.
∑
Reprendre le haut du lexique pour retrouver les principales modalités∑
Calculer les segments répétés (exemple : les noms d’auteurs en fin d’articles)∑
Étudier la concordance et les lexiques relatifs pour mettre en évidence des variantes d'écriture (exemple : les noms d’entreprise mentionnées sous des libellés un peu différents)Exemple : analyse d’une base de données bibliographiques
Pour illustrer ce qui précède examinons le cas des bases de données bibliographiques en prenant pour exemple la base ELECTRE. Elle contient l’ensemble des titres de langue française disponibles à la vente en librairie. Nous illustrerons notre propos sur l’extrait des 484 fiches bibliographiques dont le titre contient le mot éthique. Notre objectif est d’avoir un aperçu de la littérature sur ce thème.
En sélectionnant éthique dans le champs ‘titre’, on exporte les 484 fiches vers un fichier texte. On récupère ainsi un corpus qui garde les traces de la structuration de la base d’origine (Figure n° 2). Dans le cas présent on l’identifie facilement par la répétition des intitulés Auteurs, Titre... Ces mots sont toujours situés en début de ligne et sont suivis de 2 points. Avec la ligne de tirets séparant chaque fiche ils définissent des balises qui structurent le corpus.
En détectant ces balises un logiciel comme Le Sphinx Lexica permet de reconstituer la structure de la base d’origine et cela même si les fiches sont souvent incomplètes. Dans notre exemple on reconstitue ainsi 7 champs que nous appellerons désormais variables : Auteurs, Titre, Éditeur, Date de publication, ISBN, Résumé, Matière qui définissent l’information contenue dans la base d’origine.
|
Figure n° 1 Le corpus de départ |
------------------------------------------------------------------------------- Auteurs : Ciair, André Titre : Kierkegaard existence et éthique / André Ciair Éditeur : PUF Date de publication : 31/12/99 ISBN : 2-13-048330-5 ------------------------------------------------------------------------------- Titre : La santé face aux droits de l'homme, à l'éthique et aux morales / préf. Daniel Tarschys, Jean-Pierre Massué, Guido Gerin Éditeur : Conseil de l'Europe Date de publication : 13/12/96 ISBN : 92-871-3054-X Résumé : Sont étudiés, ici, cent vingt cas pratiques, où les auteurs évaluent les réactions possibles du professionnel de santé face à la législation internationale, l'éthique et les principales morales religieuses et laïques. Matière : santé publique : droit éthique médicale médecine : droit ------------------------------------------------------------------------------- |
Grâce aux ressources de l’analyse lexicale on obtient très rapidement un aperçu du contenu de ces ouvrages. Par exemple le haut du lexique des titres nous donne une idées de leur contenu, mais il nous montre également les limites de nos données. Comme le montre la présence des formes trad, ed,.....le lexique des titres confond le titre proprement dit et la mention de l’auteur ou de l’éditeur, ceci interdit de conclure sur la fréquence des noms propres. Kierkegard est bien l’objet du titre d’une des fiches de la figure 1 mais il est aussi l’auteur de plusieurs ouvrages.
Pour parer à cet obstacle on peut utiliser un élément implicite de structuration. La présence du caractère / à la fin de l’énoncé du titre permet en effet d’isoler la seule partie significative du titre. On obtient ainsi une variable contenant uniquement la mention du titre. Nous modifions ainsi la structure de la base initiale en créant un nouvelle variable ‘Titre exclusif’ dupliquant une partie du champ d’origine.
D’autre transformations de la structure initiale peuvent être utiles par exemple en ramenant le contenu de plusieurs variables à une seule. Ainsi en réunissant les variables ‘Titre exclusif’ et ‘Résumé’ on obtient un lexique décrivant mieux les ouvrages étudiés. La figure 2 présente les 10 éléments les plus fréquents du lexique réduit provenant des variables que nous venons d’évoquer. Elle met bien en évidence ce qu’on peut gagner en matière d’approximation lexicale. On aurait pu également tirer parti de la structure syntaxique des titres et produire un lexique lemmatisé. Mais on aurait alors perdu la sensibilité au nombre des termes éthique(s) et question(s) dans le lexique des résumés. Cette variation est très significative.
Si on complète l’aperçu par la recherche des segments répétés (autre manière d’exploiter les structures implicites au niveau des découpages élémentaires) de la variable regroupant ‘Titre exclusif’ et ‘Résumé’ on obtient une idée beaucoup plus précise des contenus auxquels la notion d’éthique renvoie.
|
Figure n° 2 Approximation lexicale par le haut du lexique. Influence de la structuration |
. TITRE : 10 premières occurrences du lexique réduit éthique (513), Jean (72), trad (57), éd (51 préf (43), dir (41), Pierre (39), politique (30 vie (30), sciences (29), RESUME : 5 premières occurrences du lexique réduit éthique (194), auteur (45), réflexion (38), morale (35 philosophie (32), éthiques (31), question (31), vie (31 problèmes (29), questions (25), TITRE EXLUSIF + RESUME : 10 premières occurrences du lexique réduit éthique (711), vie (61), philosophie (53), morale (51 sciences (51), droit (48), politique (47), auteur (46 réflexion (42), question (38),
|
20 premiers Segments répétés de TITRE EXCLUSIF + RESUME éthique politique : 21 éthique sciences : 20 national éthique : 19 sciences vie : 17 comité consultatif national éthique : 15 éthique économique : 15 éthique médicale : 14 éthique sciences vie : 14 vie santé : 14 éthique chrétienne : 13 éthique esthétique : 12 éthique nicomaque : 12 recherche biomédicale : 12 droits homme : 11 éthique biomédicale : 11 éthique psychanalyse : 11 éthique sociale : 11 réflexion éthique : 11 éthique droit : 10 |
Ce premier stade de l’approximation lexicale conduit à des interrogations plus poussées : peut-on plus largement que par le simple examen des lexiques ou des segments répétés identifier les thématiques dominantes de ce corpus et suivre son évolution au cours du temps ?
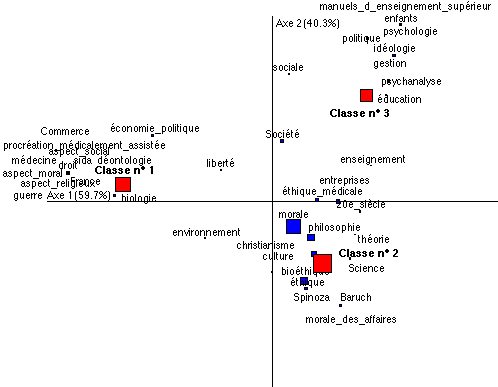
La réponse la première question peut être trouvée par l’analyse de la structure interne du corpus des titres, des résumés ou des matières. Ainsi la figure n° 3 présente les résultats d’une analyse factorielle conduite à partir des 50 premiers termes du lexique de la variable des matières. On a d’abord procédé à une classification des fiches fondée sur une analyse factorielle multiple conduite sur le tableau de présence de ces 50 premiers termes. Les 3 classes définissent des groupes de fiches présentant les mêmes types d’association entre matières. On enrichit alors la base d’une nouvelle variable codant chaque fiche selon son appartenance à l’une des 3 classes. Enfin pour caractériser chacune de ces classes on établit le tableau lexical répertoriant pour chacune d’elle le nombre d’apparitions des termes retenus pour construire la classification.
On met ainsi en évidence 3 thématiques. La classe 1 correspond aux conceptions spécialisées de l’éthique comme code régulant des pratiques scientifiques ou sociales, elle s’oppose aux classes 2 et 3 plus ancrées sur la conception héritée de la tradition morale et philosophique. Parmi ces 2 classes on distingue un ensemble d’orientation plus pédagogique et appliqué (classe 3) qui s’oppose à des approches plus théoriques et fondamentales (classe 2).
|
Figure n° 3 Classes thématiques établies à partir des 50 premiers éléments lexicaux du champ des matières |
|
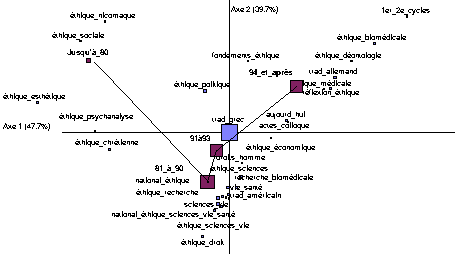
La réponse à la seconde question nécessite d’introduire la notion de période ce qui conduit à enrichir à nouveau la base de données initiale. A partir de la variable date de publication on peut en effet définir les différentes périodes par rapport auxquelles cerner les évolutions de la bibliographie. En établissant un tableau lexical qui dénombre les occurrences selon les périodes on peut mettre en évidence des évolutions significatives. La figure 4 en donne une illustration sur la base des 25 premiers segments répétés de la variable TITRE + RESUME. La carte ci-dessous met clairement en évidence l’évolution d’une notion à l’origine ancrée dans la tradition des sciences philosophiques qui évolue vers les pratiques spécialisées. On remarque également l’émergence dans les années 80 d’une problématique liée à la régulation publique des activités scientifiques.
|
Figure n° 4 Évolution des segments répétés selon les périodes |
Ces 2 exemples ne font qu’ébaucher les nombreuses problématiques qui peuvent être élaborées en tirant parti de la structuration du corpus initial et de son enrichissement progressif au fil de l’investigation : distinguer dans le corpus différents champs sémantiques, mettre à jour des structurations implicites, créer de nouvelles codifications...
On peut ainsi parvenir très vite à la mise à jour des traits dominants fournis par l’analyse statistique. Leur interprétation demeure le privilège du lecteur. L’analyse ne fait que déplacer son attention d’un corpus très volumineux vers un matériau beaucoup plus synthétique qui concentre son attention sur des propriétés qui échappent en général à la lecture classique. Reste à confirmer les interprétations par le retour au texte et aux différents éléments du corpus qui permettront de vérifier par une lecture classique, mais sélective, les idées que le matériau lexical aura fait naître.
Conclusion
Les outils de l’analyse lexicale peuvent être un précieux auxiliaire pour nous aider à prendre connaissance des corpus que l’informatique met désormais à notre disposition. Mais ces masses considérables d’information risquent de rester hors de notre portée s’il nous faut les découvrir par les méthodes de la lecture classique.
Tout comme la lecture rapide, l’approximation lexicale repose sur la capacité de parcourir le corpus dans un survol guidé par des repères structurants. La statistique lexicale et les ressources informatiques nous aident à le faire en nous offrant une ‘mobilité’ entre les différentes parties, ou niveaux du corpus, que nous pouvons faire varier en fonction de nos curiosités.
Les outils s’évaluent à leur capacité d’accompagner les différents points de vue du lecteur tout en lui révélant les propriété du corpus qu’il examine. Il pourra alors le transformer et le modeler en fonction de ses attentions et de ses questions.
La machine peut ainsi réduire des volumes décourageants par leur ampleur en leur substituant quelques informations sélectionnées par des procédés statistiques et perceptibles d’un seul coup d'œil. Mais c’est au lecteur de donner le sens et d’interpréter les données que la machine transforme.
Un outil performant et souple, un lecteur curieux et cultivé, des données riches de sens, lorsque par bonheur ces trois conditions sont remplies, les méthodes que nous venons d’exposer peuvent faire gagner beaucoup de temps et conduire à des découvertes inattendues.
Références
Baulac, Y., De Lagarde, J., Moscarola, J. (1986-1997). Le Sphinx Lexica, logiciel et manuel de référence, Sphinx développement.
Meunier, J.-G. (1996). La théorie cognitive : son impact sur le traitement de l'information textuelle, Science - Technologie - Connaissance, PUG.
Moscarola, J. (1994). Les actes de langage - Protocoles d'enquêtes et analyse des données textuelles, Colloque Consensus Ex-Machina, La Sorbonne, Paris.
Vuillemin, A. (1993). Les banques de données littéraires, PULIM.