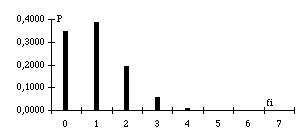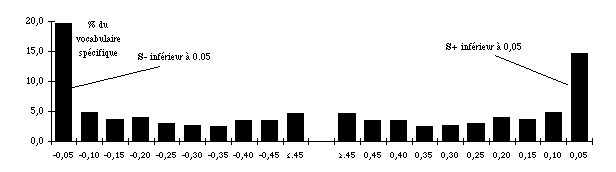|
Cyril LABBE France Télécom RD (28 chemin du vieux Chêne - 38243 MEYLAN Cedex) cyril.labbe@rd.francetelecom.fr Dominique LABBE CERAT-IEP, BP 48 – 38040 GRENOBLE Cedex 9. Dominique.labbe@iep.upmf-grenoble.fr QUE MESURE LA SPÉCIFICITÉ DU VOCABULAIRE ? A la fin des années 1970, P.Lafon a proposé d'appliquer la distribution hypergéométrique à la question de la répartition des "formes" dans un corpus. Sa formule a été appliquée sur de nombreux corpus sous le nom de "spécificités du vocabulaire". Dans cette note, nous présentons, après un rappel de la formule de P.Lafon, une simulation du comportement des résultats de la formule, en fonction de la fréquence des mots et de la taille des parties, ainsi qu'une application à un corpus de textes politiques contemporains. Cette discussion montre la portée et les limites de la notion de "spécificités du vocabulaire".
Mots clefs : Statistique lexicale - Statistique textuelle- Spécificités du vocabulaire - Répartition des formes dans un corpus Juin 1997
QUE MESURE LA SPÉCIFICITÉ DU VOCABULAIRE ? *
A la fin des années 1970, P.Lafon a proposé d'appliquer la distribution hypergéométrique à la question de la répartition des "formes" dans un corpus (Lafon 1980,1984). Cette formule a été appliquée à de nombreuses reprises mais, à notre connaissance, aucun bilan d'ensemble n'a été dressé depuis celui de B.Habert (1985). Dans cette note, nous présentons, après un rappel de la méthode préconisée par P.Lafon, une simulation du comportement des résultats obtenus en fonction de la fréquence et de la taille des parties, et une application à un corpus de textes politiques contemporains. Cette discussion nous amènera à définir certaines limites à l'utilisation de la méthode.
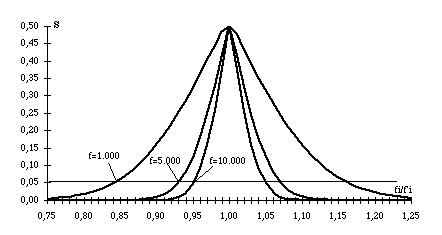
I. La méthode de P.Lafon. Cette méthode permet de mesurer les variations de la fréquence dans un corpus découpé en parties et, en fonction d'un seuil choisi par l'analyste, il indique si la fréquence observée dans telle ou telle partie peut-être considérée comme normale ou non. Dans ce dernier cas, P. Lafon propose de baptiser cette forme "spécifique" (de la partie considérée). On notera par la suite : T : la longueur du corpus (nombre total de mots de celui-ci) ti : la longueur de la partie i f : la fréquence absolue d'une forme dans le corpus entier. fi : fréquence absolue d'une forme dans la partie i X : la variable aléatoire mesurant le nombre d'apparitions d'une forme dans la partie considérée. On calcule une probabilité pour qu'une forme de fréquence f apparaisse k fois dans la partie i : (1) P(X=k)= Cette probabilité atteint son maximum à l'espérance mathématique, c'est-à-dire la "fréquence attendue dans la partie i", qui doit être nécessairement un entier tel que : - 1 _ f'i _ Si la fréquence observée n'est pas égale à cette fréquence attendue, on peut se demander si l'écart entre les deux valeurs est ou non significatif. La probabilité pour qu'on rencontre une fréquence telle que celle observée, sera : premièrement, avec fi>f' i :S+ = P(X_f i) =Si S+ est plus petit qu'un seuil choisi par l'opérateur — généralement 0,05 ou 0,01 —, on parle alors de spécificité positive : le mot est, d'après le calcul hypergéométrique, significativement "sur-employé" dans la partie considérée. deuxièmement, avec f i<f'i :S- = P(X_f i) =Dans le cas où S- est plus petit que le seuil choisi, on parle de spécificité négative : le mot est significativement "sous-employé" dans la partie considérée. On ne calcule donc pas la probabilité de l'ensemble des possibles (P(X_f)), l'indice ne sera jamais égal à un. Pour que chaque forme ait autant de chances d'être sur-employée que sous-employée, il faudrait même que la valeur maximum de la probabilité soit de 0,5. Les factorielles de la formule (1) ne peuvent être programmées directement pour les chiffres auxquels on est confronté dans les corpus linguistiques (elles aboutissent à des nombres extraordinairement grands). P.Lafon propose d'utiliser les logarithmes et aboutit à la formulation suivante : (3) log P(X=f i) = log f! + log (T-f)! + log ti! + log (T-ti)! - log T! - log fi! - log (f-fi)! - log (ti-fi)! - log (T-f-ti+fi)!Pour étudier le comportement de cet indice, on a fait varier ses quatre paramètres : la fréquence totale et la fréquence dans une partie i (f et fi) puis la taille du corpus et des parties (T et ti). II. Comportement de l'indice en fonction de la fréquence. Pour étudier le comportement de la probabilité en fonction de la fréquence, nous avons réalisé une série de simulations puis une application à un corpus réel. a. L'asymétrie de S dans les basses fréquences A priori, la mesure de la répartition des mots dans un texte devrait donner, à chacun de ces mots, une probabilité égale de figurer dans les spécificités positives ou négatives. Dans toutes les applications sur des corpus réels, les effectifs S+ et S- ne sont jamais égaux. Cette asymétrie se manifeste notamment lorsque la fréquence attendue est faible : seule la spécificité positive existe. On ne peut conclure à une spécificité négative que quand : P(X=0)<seuil Les quatre graphes 1 ci-dessous montrent que la distribution de la probabilité n'est pas symétrique autour de la valeur moyenne et ceci d'autant plus que la valeur attendue est faible. En revanche, mode, moyenne et médiane tendent vers la même valeur quand f grandit : S (fi=f'i) Å 0,5 (avec f très grand), etS (fi=f'i) > 0,5 (avec f petit)Graphique 1.1 Valeurs de P(X=fi) avec T=100.000 ; t=10.000 et f=10 (f'i=1)
Graphique 1.2 Valeurs de P(X=fi) avec avec T=100.000 ; t=10.000 et f=20 (f'i=2)
Graphique 1.3 Valeurs de P(X=fi) avec avec T=100.000 ; t=10.000 et f=50 (f'i=5)
Graphique 1.4 Valeurs de P(X=fi) avec avec T=100.000 ; t=10.000 et f=100 (f'i=10)
Ces caractéristiques avaient déjà été signalées par A. Salem (Salem 1987, p 214). Le choix des formes soumises au calcul doit donc se porter sur celles dont la fréquence totale est au moins égale à une valeur telle qu'une absence, dans la plus petite des parties du corpus, aboutisse à une spécificité négative (Salem propose de baptiser ce minimum : "seuil d'absence spécifique"). En dessous de ce seuil, le calcul n'a de sens que lorsque la fréquence constatée f i est supérieure à la fréquence attendue f'i. La conséquence sera que, plus on descendra dans les basses fréquences, ou plus on découpera le corpus en parties de taille réduite, plus le nombre des spécificités positives excédera celui des spécificités négatives. Il ne faudrait pas attribuer cet artefact à une caractéristique stylistique propre au corpus étudié !Mais, même au-dessus de ce seuil, la distribution des probabilités n'est pas symétrique autour de l'espérance mathématique (graphique 1.3 et 1.4). Sauf si l'on choisit de ne traiter que les mots à très fortes fréquences, les effectifs S+ et S- seront donc nécessairement différents. b. La convergence en probabilité Au-delà de ce problème des basses fréquences, quel est le comportement de la probabilité en fonction de la fréquence ? Ce comportement a été étudié en faisant varier f et fi. Les autres paramètres du calcul sont maintenus fixes. Le tableau 2 ci-dessous récapitule les résultats de l'une de ces expériences. On donne à f i des valeurs entières s'écartant de f'i, en plus ou en moins et selon un pas régulier. Pour pouvoir superposer diverses expériences, ces valeurs sont exprimées en proportion de f'i. Le graphique 3 permet de visualiser, pour trois valeurs significatives def, le comportement de la probabilité en fonction de fi.Tableau 2. Valeurs de S avec (T=300.000, t=30.000, f {1.000 -10.000} et fi {0,75 f'i à 1,25 f'i})
On observe un resserrement très important de l'intervalle de variation autour de l'espérance mathématique. Par conséquent, plus la fréquence totale s'élève, plus la "zone de spécificité" est importante. Ce qui signifie également qu'une même variation relative de la fréquence sera interprétée différemment selon la valeur absolue de cette fréquence. Cette observation est logique : elle découle de la "convergence en probabilité" qui est attachée à toute approche probabiliste. On peut donc dire que le calcul proposé par P.Lafon suppose, que plus une forme est employée fréquemment, plus ses variations, en valeur relative, doivent être faibles pour que son comportement soit considéré comme "normal". Cette caractéristique théorique est-elle vérifiée sur des corpus de textes réels ? C'est ce que nous proposons d'examiner maintenant.
Graphique 3. Valeurs de S avec T=300.000, t=30.000, f {1.000, 5.000, 10.000} et fi variant de 0,75 f'i à 1,25 f'i)
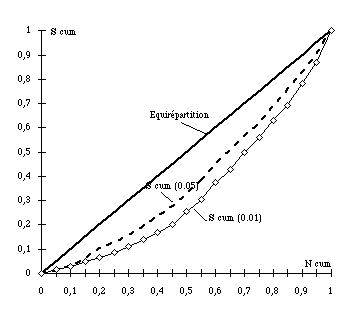
c. Application L'application porte sur le "corpus Mitterrand" découpé en 4 parties sensiblement égales (Labbé, 1990). Ce corpus comporte 305.000 mots (T) et 7.000 "vocables" différents dont 1.751 de fréquences (f) supérieures à 11 (pour tenir compte du seuil de spécificité négative défini ci-dessus). Dans un premier temps, nous examinerons les chances pour l'un de ces 1.751 mots d'être spécifique en fonction de sa répartition dans l'ensemble du corpus et de sa fréquence totale. Pour juger de manière synthétique d'une éventuelle influence de la fréquence (f) sur S, nous proposons de construire une courbe de concentration (dite de "Gini-Lorenz") : les mots sont classés par fréquence croissante et, pour chaque classe de fréquence, on compte le nombre de mots qui auront été mesurés spécifiques dans l'une ou l'autre des parties. Puis, l'on compare le poids relatif des différentes classes de fréquences dans l'effectif total et dans les mots spécifiques. Le tableau 4 et le graphique 5 permettent de visualiser cette expérience. Tableau 4. Spécificités du vocabulaire en fonction de la fréquence dans le corpus Mitterrand. Classement par fréquence croissante.
Graphique 5 Courbe de concentration de la spécificité en fonction de la fréquence
Dans la première colonne (abscisse du diagramme) : les effectifs relatifs cumulés par classes de fréquence ; dans la seconde et la troisième colonne (ordonnée du diagramme) : la proportion de mots spécifiques en retenant comme seuil 0,05 puis 0,01. Si la fréquence n'influait pas sur la spécificité du vocabulaire, on devrait retrouver sensiblement les mêmes chiffres dans les trois colonnes et, sur le graphique, les points devraient se situer sur la diagonale du carré (équirépartition du caractère sur l'ensemble des classes de fréquence). En revanche, plus ceux-ci s'éloignent de la diagonale, plus le phénomène — ici la spécificité — se concentre sur les mots les plus fréquents, ce qui est parfaitement net ici. En effet, le tableau indique que les 5% de mots dont la fréquence est la plus faible — soit f=12 — ne donnent que 1% des spécificités et qu'à l'opposé, les 100 mots les plus employés en donnent dix fois plus au seuil de 0,05 et 13 fois plus au seuil de 0,01. Cette expérience montre que plus la fréquence s'élève, plus les mots ont de chances d'être spécifiques. Comment expliquer la corrélation existant entre la fréquence et la spécificité ? On peut penser que la "convergence en probabilité" ne se produit pas, ou moins fortement que ce que la théorie laisserait attendre. Ceci peut être expliqué de la manière suivante. Pour les basses fréquences, le nombre théorique de combinaisons possibles (calculé grâce à la loi hypergéométrique) ne s'éloigne pas trop du nombre de combinaisons effectivement réalisables en respectant les règles du français. Il n'en est pas de même pour les mots de hautes fréquences : les combinaisons statistiquement possibles sont immenses et la plupart ne sont évidemment pas réalisables. Autrement dit, la structuration du discours — sous la double influence de la langue et du projet de l'auteur — se fait d'autant plus sentir que l'on monte dans les fréquences… Ainsi peut s'expliquer la présence de très nombreux "mots outils" dans la liste des mots spécifiques du corpus Mitterrand que l'on trouvera en annexe de cette note : articles, pronoms, adverbes usuels ou verbes auxiliaires alors que ces mots représentent une proportion très petite du vocabulaire total à la disposition de l'auteur. Ils devraient donc figurer également en petit nombre dans la liste. De plus, — comme il est impossible de ne pas les employer — on s'attendrait à ce que leur utilisation ne fluctue guère chez un même auteur et, dans une certaine mesure, d'un auteur à l'autre. Enfin, cette liste montre que la plupart des probabilités attachées à ces mots très usuels sont proprement infinitésimales et, d'ailleurs, nettement inférieures à la précision du calcul. En tout état de cause, leur répartition devrait être considérée comme extrêmement improbable… Cependant, au milieu des "mots outils", figurent d'autres verbes, des substantifs, des adjectifs ou des noms propres : — la plupart ont une fréquence élevée, ce qui explique leur présence dans la liste à côté des mots outils. Naturellement, ce dernier point montre l'intérêt de la méthode de Lafon : elle permet, pour les mots de fortes fréquences, de localiser des écarts relatifs même faibles et de leur affecter un signe ; — figurent également dans la liste, quelques substantifs moins fréquents. C'est le second intérêt de la méthode : elle permet de détecter des mots peu utilisés mais dont l'emploi est très localisé dans une des parties du corpus (ce qui peut donc être très significatif). Sans le calcul de Lafon, leur répartition particulière risquerait de passer inaperçue puisqu'ils sont perdus dans les profondeurs des listes de fréquences. Ainsi, en tête de la liste, on trouve "chaîne", "équilibre des forces" et "université" qui ne sont employés qu'à un moment particulier du septennat (la création de la cinquième chaîne de télévision, l'affaire des SS20 et de l'équilibre des forces nucléaires en Europe, la contestation étudiante et lycéenne de l'automne 1986). Cette localisation extrême entraîne un S+ dans l'une des parties et trois S- dans les autres. Cependant, cette brève discussion aura montré qu'il ne paraît guère possible de classer les mots en fonction des valeurs de S puisque le calcul recouvre des phénomènes langagiers et discursifs totalement opposés : fortes contraintes d'un côté ; extrême imprévisibilité de l'autre… A cela s'ajoute la grande sensibilité de la probabilité à la taille du corpus et des parties.
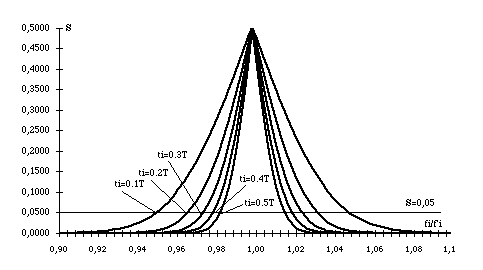
III. L'influence de la taille sur la spécificité. Comme précédemment, nous nous proposons d'examiner l'influence de la taille sur la probabilité grâce à une série de simulations théoriques avant de confronter ces résultats avec ceux d'une application. a. Simulations L'influence de la taille totale (T) sur la spécificité a été signalée par tous les auteurs : plus le corpus est grand, plus la proportion de mots spécifiques est élevée. Deux éléments sont à prendre en compte : — Du point de vue probabiliste, l'augmentation de la taille des échantillons doit entraîner un resserrement des observations autour de l'espérance mathématique (voir tableau 2 et graphique 3 ci-dessus). — Du point de vue linguistique, l'accroissement du vocabulaire est une fonction décroissante de l'allongement du corpus : quand T s'accroît, les fréquences élevées augmentent plus que proportionnellement, ce qui nous ramène au cas de figure précédent. Autrement dit — pour des raisons qui tiennent au raisonnement probabiliste et à la finitude du vocabulaire —, plus le corpus est vaste, plus les mots fréquents devraient être régulièrement répartis sur l'ensemble du corpus. L'influence de la taille des parties (t i) sur la probabilité découle en partie du constat précédent. Elle dépend également de la relation existante entre ti et T. Nous avons étudié cette relation particulière en faisant varier ti et en maintenant fixes f et T. Le graphique 6 et le tableau 7 récapitulent les résultats obtenus lors de l'une de ces expériences théoriques.On observe toujours le même phénomène de gonflement de la zone de spécificité (ou de rétrécissement de la "zone de normalité"). Là encore, le raisonnement probabiliste explique ce résultat. Plus les tailles des parties sont importantes, plus la forme considérée devrait présenter, "normalement", des variations relatives faibles ou encore plus sa fréquence observée (f i) dans chaque partie devrait s'approcher de la valeur attendue f'i.Graphique 6. Evolution de S en fonction de la taille des parties (T=300.000 ; f=10.000 ; t i {30.000 — 150.000} ; fi {0,9 f'i — 1,1 f'i}
tableau 7. Evolution de S en fonction de la taille des parties (T=300.000 ; f=10.000 ; t i {30.000 — 150.000} ; fi {0,9 f'i — 1,1 f'i})
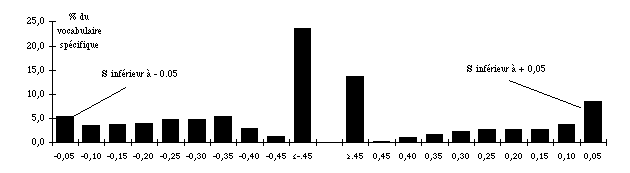
b. Application Pour mesurer l'influence de la taille des parties sur les spécificités du vocabulaire, nous avons découpé le corpus "Mitterrand" en parties égales de plus en plus nombreuses. Les résultats sont donnés dans le tableau 8 et le graphique 9 ci-dessous. Tableau 8. Proportion du vocabulaire spécifique dans le corpus Mitterrand découpé en parties égales.
Figure 9.1 Diagramme de répartition des spécificités dans le corpus Mitterrand découpé en 2 parties égales
Figure 9.2 Diagramme de répartition des spécificités dans le corpus Mitterrand découpé en 10 parties égales
Avec un découpage en 2 parties égales, plus du tiers des mots sont spécifiques en tel ou tel point du corpus (à un seuil de 0,05). Avec un découpage en 10 parties égales, cet effectif est légèrement inférieur à 14%, soit une division par 2,5. La taille des parties joue donc un rôle considérable dans les chances qu'auront les mots d'être ou non spécifiques. Ces résultats appellent quelques remarques complémentaires : — Il n'y a pas de symétrie entre le haut et le bas du tableau (ou entre les parties gauche et droite des graphiques). Avec deux parties, les spécificités négatives (S-) sont plus nombreuses que les positives (S+) ; avec cinq parties et plus, la proportion se renverse et l'écart se creuse progressivement. Les graphes 1 discutés plus haut fournissent l'explication. Pour 2 parties, la plus petite fréquence attendue est de 6 puisque f_12 : dans une telle configuration, on voit que l'asymétrie des probabilités est assez faible mais qu'elle joue en faveur des S-. Pour dix parties, les mots, dont la fréquence sur l'ensemble du corpus est inférieure à 30, ne peuvent plus être S-. L'asymétrie des probabilités joue massivement en faveur des spécificités positives. — On observe également une asymétrie croissante entre l'effectif à -0,5 et à +0.5. Cette caractéristique tient aussi à l'application du calcul sur des fréquences assez basses… — Une proportion importante des mots sont spécifiques — et, étant donné leur haute fréquence, ils couvrent la majorité du texte — ce qui pose problème quant au raisonnement probabiliste : la spécificité devient la situation "normale" et la normalité, l'exception ! Enfin, on aura noté que, dans les tableaux 2 et 7, les valeurs de S, lorsque f i=f'i, sont légèrement supérieures à 0,5 et que l'écart tend à diminuer au fur et à mesure que T,ti et f augmentent. Ce biais est inhérent au calcul proposé par Lafon. La formule (3) consiste en effet à calculer l'espace sous la courbe entre 0 ou f et la valeur observée incluse. La probabilité pour que X=f'i est donc comptée deux fois. Naturellement, cette caractéristique de la formule ne se voit que lorsque la valeur observée coïncide avec l'espérance mathématique. Elle n'avait pas été aperçue car ces valeurs n'intéressent généralement pas l'observateur qui recherche les spécificités et ne s'intéresse pas à l'ensemble de la distribution.
Conclusions A l'issue de cette discussion, il nous paraît nécessaire de préciser les limites d'utilisation du calcul hypergéométrique pour la recherche des spécificités du vocabulaire d'un corpus. En premier lieu, il convient d'y associer un seuil minimal de fréquence en dessous duquel le calcul ne sera pas effectué, seuil qui ne pourra pas être inférieur à la valeur nécessaire pour que la fréquence attendue dans la plus petite partie du corpus soit au moins égale à trois (puisque, en toute hypothèse avec f'i<3, la spécificité négative ne peut pas être inférieure à 0,05). Même avec un tel seuil, le nombre des mots S+ ne sera pas égal à celui des S-. Pour établir une certaine égalité, la fréquence attendue dans la plus petite des parties doit probablement être nettement supérieure à 5. Autrement dit, cela limiterait l'application de la formule à quelques mots usuels, dans de grands corpus découpés en parties elles-mêmes vastes. Dans le cas contraire, pour la plupart des mots, le fait d'être S+ ne pourra pas être considéré comme exactement symétrique de l'événement S-. Etant donné l'influence considérable de la fréquence sur la probabilité, il n'est pas souhaitable de comparer, du point de vue de leur spécificité, des mots de fréquences trop différentes. Cela devrait conduire à faire apparaître clairement la fréquence aux côtés de la spécificité et à découper les tableaux en plusieurs compartiments (pour le moins : fréquences fortes, moyennes et faibles). Plus fondamentalement : puisque la formule mesure indissociablement les effets des choix de l'auteur et les contraintes que la langue fait peser sur ses usagers, il serait souhaitable de comparer des mots de même nature : la spécificité d'un pronom personnel ne devrait s'apprécier que par rapport aux autres pronoms personnels, les substantifs et les adjectifs par rapport aux autres substantifs et adjectifs, de même pour les articles, les numéraux, etc… Enfin, les parties comparées devraient être sensiblement égales ou, dans le cas contraire, les comparaisons devraient être décomposées pour constituer des sous-groupes de tailles pas trop différentes. Ces conditions restrictives posées, la présentation des résultats pose un problème aux non-statisticiens : la spécificité est d'autant plus forte que S est faible ! Pour faciliter la compréhension des résultats, deux solutions sont envisageables : On exprime S sous la forme d'un indice fluctuant entre 0 et ±1 avec une spécificité d'autant plus forte qu'il s'approche de ±1 et une valeur nulle effectivement égale à 0… Ceci peut être obtenu grâce à la formulation suivante :
Mais cette formulation présente un inconvénient : l'indice n'est plus égal à la probabilité (que l'événement f i ne soit pas dû au hasard). Par exemple avec S = 0,05, l'indice sera égal à 0,90 (et non à 0.95). C'est pourquoi, à la réflexion, une seconde solution paraît préférable.Deuxièmement, le calcul de Lafon mesure l'espace compris sous la courbe de probabilité de l'événement f i :
Pour mesurer cette surface, la formule devient : (1) S = Et pour le calcul pratique, avec fi<f'i, on utilise la formule (1) ci-dessus, avec fi=f' i : S = 0.5avec fi > f'i, : S = 1 - Le mot sera significativement sur-employé, au seuil de 5%, avec un indice supérieur à 0,95 (ou 0,975 selon que l'on considère la moitié de la courbe ou l'ensemble de celle-ci) et à 0,99 (ou 0,995) au seuil de 1%. A l'inverse, il sera significativement sous-employé avec un indice inférieur à 5% ou 1%. La spécificité positive sera d'autant plus significative que S se rapproche de 1 ; la spécificité négative d'autant plus significative que S tend vers 0. Cette formulation est préférable à l'indice ci-dessus ou à la notation adoptée par le laboratoire de lexicométrie de Saint-Cloud, à la suite des travaux de P. Lafon. En définitive, ce calcul est une application du schéma de l'urne que, il y a plus de 30 ans, C. Muller avait proposé d'appliquer à l'étude du vocabulaire : "Essayer les méthodes statistiques sur le vocabulaire d'un texte, c'est avouer une croyance, ou tout au moins ne pas refuser une hypothèse : celle d'après laquelle le choix des mots, dans l'exercice du langage, relève des lois du hasard et peut être assimilé à un tirage aléatoire. Cela tout au moins quand on considère une étendue suffisante de texte, et qu'on l'envisage comme une masse en faisant abstraction de l'ordre d'apparition de ses éléments" (Muller, 1964). Comme C. Muller en avait eu l'intuition, dès l'origine, ce schéma est un pis-aller : nous sommes condamnés à l'utiliser tant que n'auront pas été développés des modèles théoriques plus adaptés à la réalité du langage. Grenoble, juin 1997.
Bibliographie HABERT Benoît, 1983, "L'analyse des formes spécifiques et typologie des énoncés", Mots, 7, octobre 1983, p 97-121. HABERT Benoît, 1985, "L'analyse des formes spécifiques : bilan critique et propositions d'utilisation", Mots, 11, octobre 1985, p 127-154. LABBE Dominique, 1990, Le vocabulaire de F. Mitterrand, Paris, Presses de la Fondation nationale des sciences politiques. LAFON Pierre, 1984, Dépouillements et statistiques en lexicométrie, Genève-Paris, Slatkine-Champion. LAFON Pierre, "Sur la variabilité de la fréquence des formes dans un corpus", Mots, 1, octobre 1980, p 127-165. LEBART Ludovic, SALEM André, 1994, Statistique textuelle, Paris, Dunod. MULLER Charles, 1964, Essai de statistique lexicale. L'illusion comique de Pierre Corneille, Paris, Klincksieck. MULLER Charles, 1977, Principes et méthodes de statistique lexicale, Paris, Hachette. SALEM André, 1987, Pratique des segments répétés. Essai de statistique textuelle, Paris, Klincksieck. Annexe 1. Les 100 indices de spécificités les plus forts du corpus Mitterrand (classement par spécificités décroissantes)
Annexe II. Les mots spécifiques du corpus Mitterrand découpé en quatre parties Mots Fréquence Spécificitédans les quatre parties chaîne (n.f.) 76 8,5288E-22 5,9929E-06 5,9929E-06 0,00367453 équilibre (n.m.) 114 5,061E-11 1,4274E-06 0,00022548 0,00024403 force (n.f.) 204 9,9272E-08 7,6728E-07 1,3212E-06 2,0276E-05 non (adv.) 523 2,8239E-07 4,6441E-05 0,00116901 0,00624776 nous (pro.) 2047 4,5594E-27 1,5858E-24 4,3876E-13 4,309E-11 réforme (n.f.) 65 1,4064E-15 0,0003343 0,00119105 0,00359855 son (det.) 868 0,00023928 0,0011452 0,00378882 0,00759949 université 24 2,0259E-10 0,0090286 0,0090286 0,0090286 Dans trois parties : aller (v.) 786 2,2706E-07 6,9113E-05 0,00599067 alliance (n.f.) 42 9,2296E-06 8,4787E-05 0,00062563 Alsace 17 7,4203E-08 0,00751583 0,00751583 arabe (adj.) 50 6,6917E-09 8,7005E-05 0,00210703 avoir (v.) 7713 8,0014E-10 5,02E-07 0,0052096 banque (n.f.) 33 5,495E-07 0,00532218 0,00532218 Bretagne 22 1,2172E-10 0,00178336 0,00178336 candidat (n.m.) 42 2,4393E-09 8,4787E-05 0,00302974 ce (pro.) 5260 2,3148E-30 9,7778E-11 0,00175001 ce (det.) 2723 4,0497E-08 0,00142254 0,00420445 charge (n.f.) 104 3,1558E-07 0,00052118 0,00298387 chiffre (n.m.) 46 1,9838E-05 0,00484486 0,00484486 cinquième (det.) 36 4,3325E-10 3,1762E-05 0,00263694 consommation (n.f.) 34 3,9324E-09 5,647E-05 0,00069655 croissance (n.f.) 64 9,9586E-08 1,803E-05 1,803E-05 de (prep.) 20964 6,8849E-38 4,5045E-36 0,00858815 disposer (v.) 162 3,2708E-07 0,00115378 0,00727124 dix (det.) 301 5,7692E-15 8,9458E-07 0,00030253 domaine (n.m.) 152 6,5136E-06 0,00112968 0,00421396 économie (n.f.) 87 0,00059008 0,00806731 0,00806731 énergie (n.f.) 48 2,1291E-07 0,00320499 0,00320499 entreprise (n.f.) 218 3,2991E-15 4,6584E-05 0,00025781 et (conj.) 5516 9,1155E-16 2,4826E-05 0,0001277 être (v.) 10995 4,8506E-15 5,8657E-05 0,00121785 étudiant (n.m.) 35 3,5774E-15 4,2351E-05 0,00053652 Europe 390 2,1191E-07 7,5572E-07 0,00418295 Habré 25 0,00021438 0,00702209 0,00702209 Hissein 25 0,00021438 0,00702209 0,00702209 il (pro.) 4976 3,5691E-06 0,00015046 0,00806081 impôt (n.m.) 91 3,6982E-25 4,2524E-12 2,0649E-05 investissement 54 4,1045E-07 0,00019632 0,00019632 Irak 32 3,404E-08 0,00117145 0,0067059 Iran 53 1,0665E-18 4,454E-06 4,0996E-05 Israël 71 2,3725E-19 3,2503E-06 3,2503E-06 le (art.) 29559 5,7499E-46 4,3662E-22 7,8879E-12 Liban 65 6,2324E-07 1,4142E-05 0,00359855 Libye 41 0,00011054 0,00637569 0,00637569 libyen (adj) 25 7,3565E-06 0,0007523 0,00702209 Louvre 26 0,00038961 0,00545454 0,00545454 majorité (n.f.) 217 3,3374E-12 3,5351E-06 0,00032183 mars (n.m.) 61 1,7929E-08 0,00019115 0,00736562 missile (n.m.) 37 1,4262E-10 0,00031765 0,00893878 monsieur (n.m.) 452 2,3313E-08 8,7741E-05 0,00447171 musée (n.m.) 25 9,6348E-10 0,00702209 0,00702209 nationalisation (n.f.) 57 1,514E-14 9,6733E-05 0,00176672 nécessaire (adj.) 125 7,6194E-05 0,00024838 0,00563478 neuf (det.) 821 2,0499E-15 1,6265E-08 7,5788E-05 notre (det.) 710 3,6497E-16 4,521E-11 0,0082605 nouveau (adj.) 269 3,6595E-05 0,00405375 0,00866057 otage (n.m.) 37 1,3366E-11 2,382E-05 0,00031765 Palestinien (n.m.) 28 2,2071E-06 0,00327961 0,00327961 pas (adv.) 4042 4,6071E-07 2,5712E-06 0,00928358 président (n.m.) 303 1,7173E-15 2,2595E-05 0,00041266 quatre (det.) 745 4,8787E-14 2,3998E-07 0,00907428 que (pro.) 2326 0,00852945 8,9538E-05 0,00040214 référendum (n.m.) 27 6,0441E-06 0,00423187 0,00423187 relance (n.f.) 32 2,6447E-12 0,0001004 0,0067059 république (n.f.) 330 3,1854E-14 0,00017627 0,00079586 social (adj.) 227 1,1981E-05 0,00032152 0,00807394 soixante (det.) 250 4,6723E-14 0,00011633 0,00202481 Tchad 114 2,1574E-13 1,0853E-12 0,00061691 tonne (n.f.) 35 1,3171E-09 4,2351E-05 0,00053652 Union Soviétique 84 8,8629E-07 2,1522E-06 0,00030124 vingt (det.) 666 8,195E-08 9,6621E-06 0,00241435 y (pro) 1745 3,6265E-14 7,9962E-07 0,00246845 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||