|
Étienne Brunet
Université de Nice
Les dictionnaires électroniques
des temps modernes
Les dictionnaires électroniques du français classique
ou préclassique posent des problèmes spécifiques,
dont beaucoup sont liés au traitement complexe des graphies anciennes.
La tâche est plus facile quand il s'agit d'une orthographe normalisée
et d'un état de langue plus proche de nous. Et c'est pourquoi les
dictionnaires informatisés du français (ou de l'anglais)
contemporain ont été réalisés avant les autres,
sans compter que la rentabilité commerciale y était mieux
assurée.
Bons ou mauvais, ces précédents peuvent servir pour les
réalisations, envisagées ou déjà entreprises,
qui s'appliquent à un état de langue plus ancien. En examinant
quelques-uns de ces dictionnaires électroniques des temps modernes,
on peut espérer en tirer des principes et des lecons, sans cacher
les erreurs et les embarras que la difficile entreprise de la rétroconversion
entraîne nécessairement. Comme il serait vain de tenter un
catalogue, on appuiera la réflexion sur quelques dictionnaires qui
permettent de mettre en valeur les bons et les moins bons exemples et de
diversifier les expériences, selon qu'il s'agit du français
ou de l'anglais, d'un dictionnaire de langue ou d'une encyclopedie, d'un
produit disponible sur CD-Rom ou sur Internet. Quatre réalisations
sont ainsi proposées à l'analyse:
- l'Encyclopedia Universalis
- le Robert électronique
- l'Oxford English Dictionary (version 2)
- le TLFI (Trésor de la langue française informatisé)
- I -
Il serait oiseux de reprendre les considérations générales
sur l'hypertexte, si en vogue aujourd'hui. Les moyens nouveaux de stockage
et de diffusion, qui permettent l'accès direct à n'importe
quelle information et son affichage immédiat, offrent à l'utilisateur
la liberté interactive de circulation, avec des itinéraires
variés et une signalisation précise - ce que recouvre la
notion d'hypertexte. Mais la circulation peut être étroitement
canalisée ou largement ouverte, fluide ou encombrée, selon
la portée et la commodité des moyens de communication.
La circulation est aisée dans le CD-Universalis, que l'Encyclopedia
du même nom vient de lancer dans le public. Pour parcourir un espace
considérable (plus de 45 millions de mots répartis en 52000
entrées et 22000 documents), ce dictionnaire encyclopédique
- à la différence des dictionnaires de langue - se fonde
sur un thésaurus hiérarchique qui tend à structurer
les connaissances, les domaines et les concepts.
1 - La première action à mener est de proposer un mot
ou une expression dans la ligne du haut de l'écran, et de choisir
un mode de recherche, grâce à un menu déroulants où
l'item par défaut (index) cache d'autres options (recherche dans
l'encyclopédie tout entière, dans les résultats acquis,
dans le panier, dans le document ouvert, parmi les sources citées
ou les auteurs d'articles).
Figure 1. Choix du type de recherche
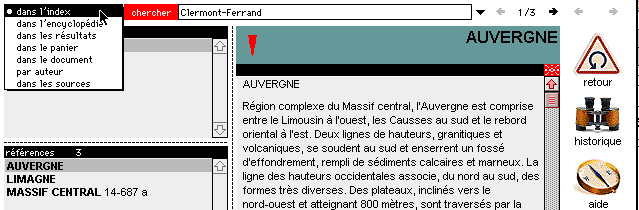
C'est en principe par l'index que commence une consultation. Si la notion
revêt un degré de généralité suffisant,
on y verra apparaître des retraits et des sous-catégories,
comme dans l'exemple 1 relatif à la physique, qui propose
68 entrées dont certaines hiérarchisées (dans la fenêtre
supérieure gauche). On peut élargir ou restreindre la portée
de la recherche en sollicitant les symboles + ou - qui accompagnent le
nombre des entrées retenues. Noter que les entrées sont classées,
selon leur importance typographique, les majuscules l'emportant sur les
minuscules et les caractères gras sur les maigres.
Dans une seconde étape on choisit dans la liste des entrées,
celle qui cerne de plus près l'objet de la recherche (par exemple
antimatière).
On obtient alors une liste de références, c'est à
dire d'articles développés dans l'encyclopédie. Un
troisième choix est à faire parmi ces références
- l'article élu prenant place dans la fenêtre principale (par
exemple l'électron dans la figure 2).
Figure 2. Choix de l'entrée, puis de l'article de référence
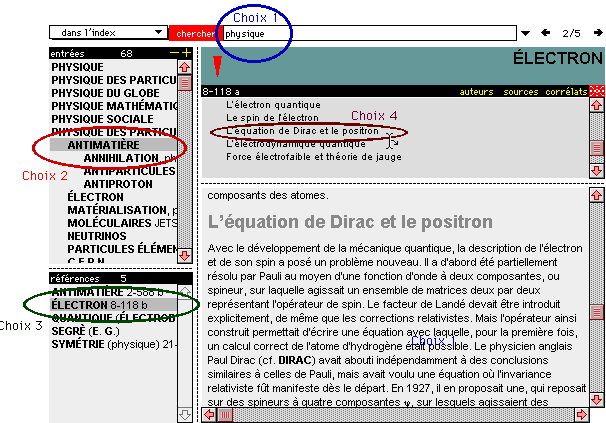
En trois ou quatre coups de "zoom" on focalise ainsi la recherche sur
le texte pertinent, par une procédure qui est analogue à
la consultation du fichier matières dans les bibliothèques.
La structure interne de l'article - si elle est explicitée -
est montrée en haut de l'écran, à droite. Un clic
sur un élément de ce sommaire provoque l'affichage du paragraphe
correspondant. Mais en dehors de ce sommaire aucune analyse de l'article
n'est disponible. Il n'y a rien qui corresponde aux éléments
imposés d'un dictionnaire de langue, comme les définitions
et les exemples. L'article est alors considéré comme une
portion de texte linéaire, que l'on peut lire, sauvegarder ou imprimer.
A défaut d'analyse - impraticable dans le texte intégral
- le logiciel est généreux à l'exportation. Rien n'y
limite la copie ou l'impression, sinon les règles morales qui régissent
le copyright (dont le rappel discret figure au bas des documents exportés).
2 - Il n'est pas nécessaire de construire sa recherche aussi
précautionneusement, en suivant le fil logique du thésaurus
et en ouvrant les portes avec des mots-clés. La recherche directe
est possible dans la totalité de l'encyclopédie, sans autre
clé que le mot proposé. L'indexation a en effet été
réalisée dans le texte intégral sans rien exclure
parmi les mots dits pleins. Même les plus fréquents comme
homme
ou jour peuvent être proposés. Il y aura seulement
des limitations à l'affichage, seules étant retenues les
500 premières références (sur les 3690 où le
jour
pénètre). Mais les premières sont les plus significatives,
puisque le classement des documents présentés est déterminé
par la fréquence du mot cherché. Ce mot apparaît en
couleur dans la fenêtre de l'article et un système de flèches
permet de passer instantanément d'une occurrence à l'autre,
ou d'un document au suivant ou au précédent, ou d'une étape
à l'autre dans le chemin qu'on a parcouru et dont l'historique est
soigneusement relevé. Il faut admirer ici la puissance du moteur
de recherche et les facilités de navigation dans un corpus pourtant
considérable. Admirable est aussi l'économie des moyens:
un seul écran est maintenu d'un bout à l'autre de la consultation,
avec quatre zones principales occupant les quatre quadrants. Ces plages
sont cependant modulables et extensibles, surtout la fenêtre principale,
qui en cas de besoin, peut recouvrir toute la surface. L'ergonomie est
d'une grande efficacité, les icones de la partie droite ont un graphisme
clair et agréable, même si certains peuvent trouver à
redire devant la sobriété manifeste de la présentation,
et par exemple devant l'étroitesse de la ligne d'état, au
haut de l'écran (les flèches y sont si discrètes qu'elles
peuvent passer inaperçues).
Figure 3. Recherche dans le texte intégral de l'encyclopédie

La recherche dans le texte intégral est cependant dangereuse,
si l'on n'a rien pour se protéger contre le bruit et le silence.
Contre le bruit, c'est à dire les documents non pertinents, il est
avantageux d'accroître les contraintes, soit en proposant une expression,
soit en utilisant l'un des opérateurs ET (figure 4), SAUF ou PRES.
Contre le silence - c'est à dire un nombre trop restreint de documents
- on a la ressource de l'opérateur OU et aussi la troncature (marquée
par le signe * après le radical qu'on veut isoler).
Figure 4. Expression et opérateurs booléens

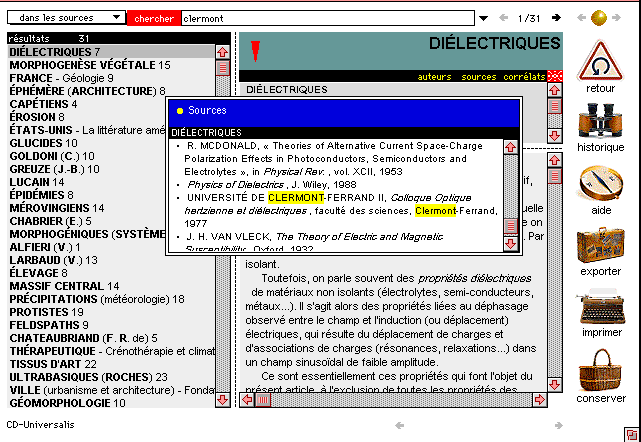
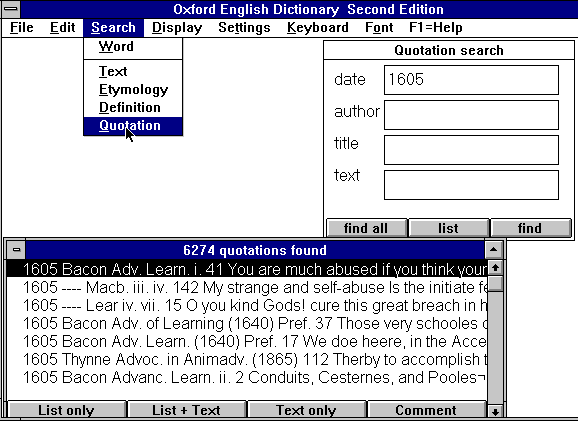
3 - Les recherches sur les auteurs et les sources jouent un rôle
assez semblable à celui de la tradition documentaire, à cette
réserve près que la liste des auteurs se limite au catalogue
des rédacteurs. Par contre les sources mentionnent la bibliographie
extérieure, sans fournir autre chose que les références
des ouvrages (ici les bibliothèques reprennent l'avantage...). Ce
type de recherche peut s'exercer à deux niveaux, soit à l'intérieur
d'un document (on dispose aussi d'un choix de corrélats), soit à
l'échelle de l'encyclopédie entière, comme dans la
figure 5 qui recense toutes les références dont l'origine
est à Clermont- Ferrand.
Figure 5. Recherche dans les sources
Quoique encyclopédique, le CD-Universalis ne cède
à aucune des facilités qui ont cours dans le monde du multimédia.
On n'y trouve ni image, ni son, ni séquences animées. Et
il n'y a rien dans le CD-ROM qui ne soit fidèlement dans la version-papier,
sinon un étonnant moteur de recherche apte à parcourir en
tous sens un circuit de 24 gros volumes. Un parti-pris, commun au CD-Rom
et au dictionnaire-papier, est affirmé en faveur du texte. C'est
toujours avec des mots qu'on aborde le référent, jamais avec
des illustrations. En cela l'Encyclopedia Universalis se rapproche des
dictionnaires de langue.
- II -
1 - Le Robert électronique est un CD-ROM conçu pareillement
à l'image du dictionnaire papier. Le contenu des articles est emprunté
sans changement au Grand Robert. L'organisation interne en est seulement
rendue plus visible non seulement par le jeu des symboles et de la couleur,
mais aussi par l'alternative entre présentation abrégée
ou détaillée et par le choix de la rubrique affichée
(définition, étymologie, citations, analogie ou dérivation).
Les liens mis en oeuvre sont ici
hiérarchiques (voir figure
6). Ils définissent la
structure et renvoient aux différents
éléments de l'article.
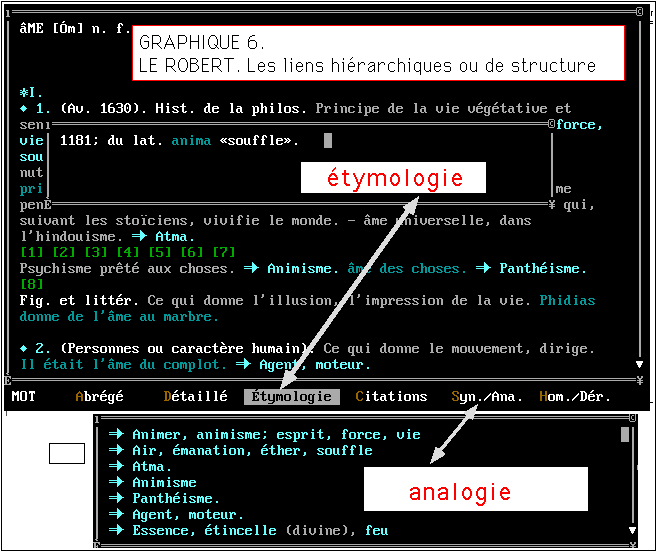
Cela répond à une nécessité ergonomique,
vu l'étroitesse de l'écran qui n'offre pas la même
surface déployée qu'un livre ouvert de grand format (sans
compter une définition très inférieure à celle
des photocomposeuses). Le lecteur du Grand Robert bénéficie
d'une vision globale et panoramique qui contraste avec la myopie inhérente
aux écrans ordinaires[1]. Le CD-ROM ne
présente en effet qu'une colonne, qui est souvent incomplète
et qu'on doire faire défiler.
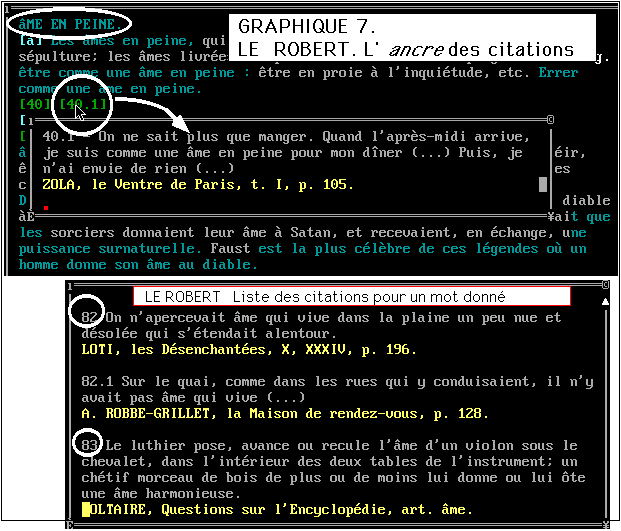
2 - Mais quand un dictionnaire préexiste à son traitement
informatique (c'est la situation commune au Robert, au TLF
et à bien d'autres), il y a chance que la structure hiérarchique
n'y montre pas la cohérence et la constance qu'on exige d'une base
de données. En particulier les citations sont disséminées
tout au long de l'article, et c'est par un artifice un peu brutal qu'on
peut les rassembler dans la même fenêtre en sollicitant le
menu
Citations au bas de l'écran (figure 7). Il est cependant
possible de lire la citation in situ en sollicitant le renvoi numérique
qui apparaît entre crochets dans le texte de la définition.
Ce lien est analogue à celui qui rattache traditionnellement la
note à l'appel de note. Sa mise en oeuvre dans un produit informatique
se traduit par une fenêtre superposée à l'endroit exact
où la citation a sa place dans le texte d'origine. L'effet est celui
d'une sorte de zoom qui explicite et developpe le signal convenu.
Cette technique de l'ancre a été généralisée
dans les écrans générés par WEB et gouvernés
par le langage HTML, comme on verra plus loin.
3 - Ces liens, internes à l'article, n'ont qu'une portée
restreinte. À l'échelle du dictionnaire, il existe un ordonnancement
alphabétique
des entrées, qui relie chacune à la précédente
et à la suivante dans la séquence. L'esprit humain est habitué
à cet ordre qui remonte à l'origine de l'écriture
et que la machine reproduit sans problème dans ses index. La manipulation
de tels index permet en outre de neutraliser le début ou la fin
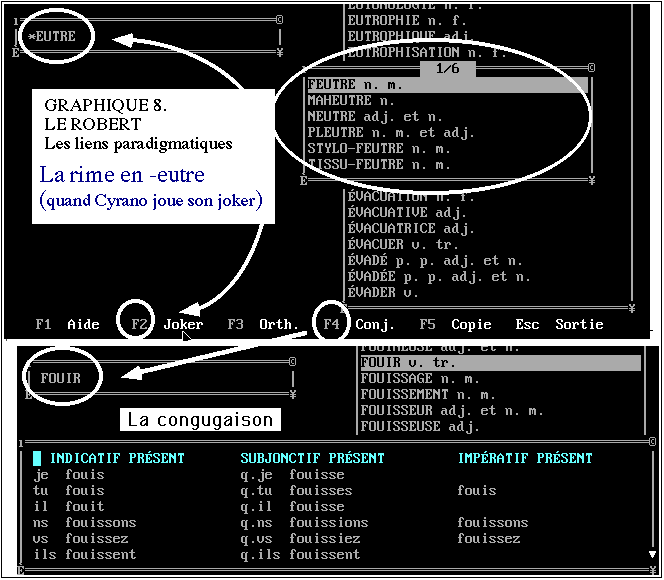
des mots, ou telle portion du mot que l'on voudra. Le rôle des jokers
est ainsi d'isoler un préfixe, un radical, un suffixe ou une chaîne
de caractères quelconque. Si Cyrano improvisant la fameuse ballade
du duel avait pu consulter le Robert électronique tout en
ferraillant, il ne lui aurait pas manqué la quatrième rime
en eutre dont il avait besoin. Voir le haut de la figure 8. Dans
le cas des verbes le lien
paradigmatique est établi entre
le radical et les désinences canoniques. Voir figure 8, en bas.
En réalité ces ressources de filtrage, de masquage
ou de conjugaison sont communes à la plupart des systèmes
documentaires et on les retrouve par exemple dans FRANTEXT. Sans constituer
le moins du monde une innovation, cette facilité offerte par le
Robert
électronique n'en représente pas moins un progrès
par rapport à la version papier.
4 - Un autre progrès, plus décisif, est apporté
par les liens de croisement (en anglais cross reference),
qui permettent, à la faveur d'un mot présent sur l'écran,
de se détourner de l'entrée affichée pour rejoindre
une autre. Cette possibilité de bifurcation est généralisée
à tous les mots affichés, qui sont tous accessibles au curseur
et à la sélection, qu'ils appartiennent à la définition,
à la citation ou aux champs analogiques ou dérivationnels.
Si on se laisse distraire, le parcours discontinu peut se prolonger à
l'infini et, à l'occasion, mettre en lumière la fameuse circularité
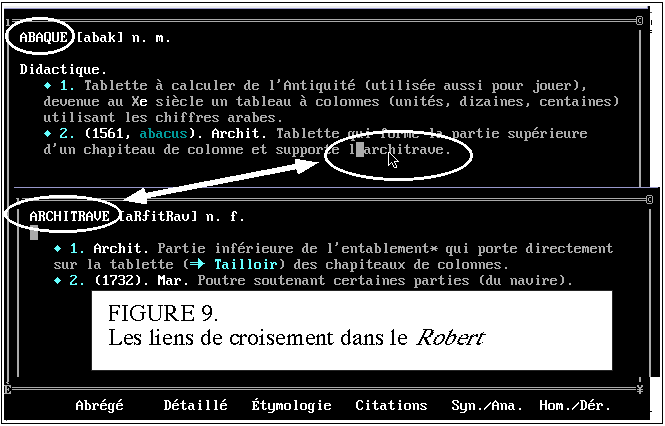
des définitions lexicographiques. L'exemple architectural de la
figure 9 montre le bénéfice qu'on peut attendre de cette
circulation rapide à l'intérieur du dictionnaire, le sens
d'une entrée se précisant en présence d'une seconde
entrée associée. Ainsi la seconde acception du mot abaque
s'éclaire au contact de l'architrave. Cette pratique de la
consultation en cascade n'est pas étrangère au dictionnaire-papier
et combien de voyages imaginaires n'y a-t-on pas faits parmi les mots et
les choses, jusqu'à oublier parfois le point de départ. Mais
la manipulation de tomes différents est lourde et décourageante,
au lieu que l'invite du CD-ROM est alerte et séduisante.
. 
Celle du Robert électronique est même trop
séduisante, en ce sens qu'elle peut égarer l'usager et lui
faire perdre sa route. Il manque en effet à la consultation du Robert
un espion électronique qui repère les lieux parcourus et
permette le retour en arrière. Ces liens historiques, qui
relient les étapes d'un parcours, font partie intégrante
de tout voyage sur l'Internet. En particulier la consultation du WEB par
Mosaic ou Netscape imite la démarche du petit Poucet, et dépose
des cailloux à chaque détour du chemin. Le saut de l'un à
l'autre, en avant ou en arrière, se fait instantanément comme
si l'on disposait de bottes de sept lieues.
- III -
1 - Les liaisons historiques[2] ne font pas
défaut par contre à l'Oxford English Dictionary, même
si l'on aurait pu souhaiter une mise en oeuvre plus discrète. Toutes
les étapes restent en effet présentes, au moins à
l'état virtuel, sur l'écran. Et l'encombrement qui en résulte
ne va pas parfois sans confusion. Bien entendu toutes les variétés
de liaison exploitées par le Robert se retrouvent ici, puissamment
enrichies. Les entrées accessibles ne sont plus uniformément
les mots-vedettes, mais aussi bien des sous-vedettes, des graphies phonétiques,
ou des expressions (comme dans l'exemple de la figure 10). Les jokers,
comme dans le Robert, permettent de regrouper les formes qui respectent
un schéma alphabétique. 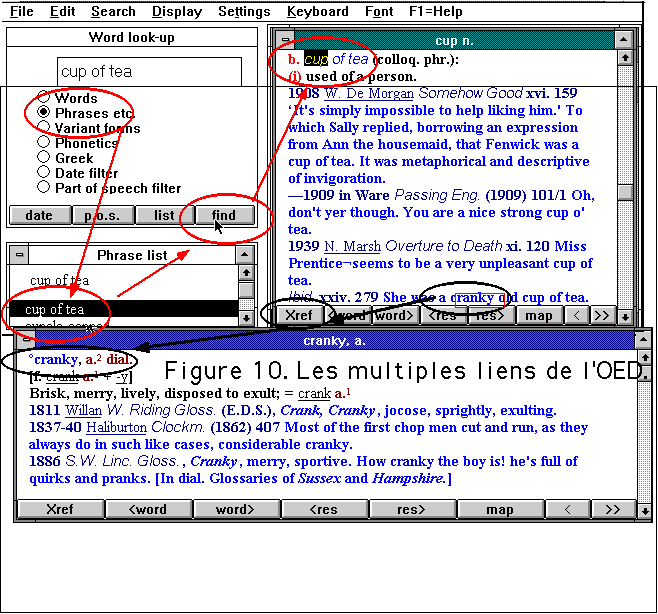
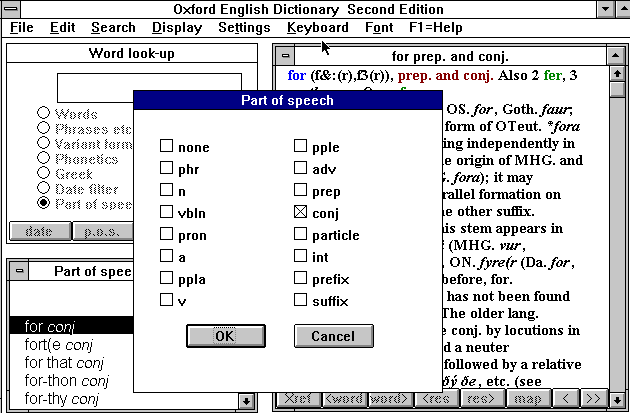
L'OED ajoute à ces critères formels de sélection
ceux de la datation et de la catégorie grammaticale. Les liens hiérarchiques
apparaissent lorsqu'on fait apparaître la carte ou structure de l'article
(bouton map). Et les liens séquentiels permettent de se déplacer
d'un pas en avant ou en arrière, dans la suite des entrées
(bouton <word et word>) ou des résultats (<res
et res>). Par contre les liens fondés sur l'analogie ne semblent
pas avoir fait l'objet d'un traitement particulier, même si les liens
de croisement peuvent jouer le même rôle, à la discrétion
de l'usager. On active ces derniers en isolant un mot et en sollicitant
le bouton Xref, comme dans l'exemple ci-dessus.
2 - La supériorité éclatante de l'OED ne
réside pas dans le simple affichage du dictionnaire papier, ni dans
les possibilités d'atteindre sélectivement telle ou telle
entrée de la nomenclature. L'avantage décisif de ce produit
tient à ses capacités relationnelles. Ces relations sont
trop timidement développées dans le Robert, et uniquement
dans la version Apple, pour la gestion des exemples. Il est en effet possible
d'y consulter la base pour relever tous les exemples qui contiennent tel
ou tel mot, par exemple jour et nuit.
Figure 11. Les capacités de la version Apple du Robert électronique
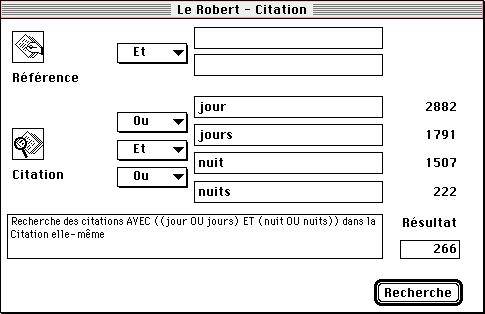
Résultat: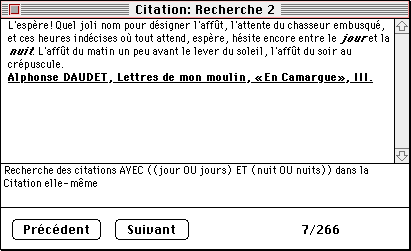
À cet égard l'OED va bien au delà du Robert.
Il constitue une véritable base de données structurée,
qui certes donne accès à chacun de ses enregistrements, mais
autorise aussi des requêtes générales qui embrassent
l'ensemble de la base. Tandis que le Robert peut seulement conduire
l'usager à l'article vice (et à ses homonymes), l'OED
sait reconnaître les entrées où le vice s'est
introduit sous une forme ou sous une autre. Mieux même il peut dénoncer
le
vice dans l'ensemble du texte, ou seulement dans la définition,
ou dans les citations, voire même dans l'étymologie. À
vrai dire le vice est si répandu, même en Angleterre,
que la machine pourrait reculer devant ses débordements. Mais la
digue des 8000 occurrences n'est pas rompue et la machine restitue sans
broncher les 1785 contextes concernés. En limitant la recherche
aux citations empruntées à Oscar Wilde, on verra sur l'écran
les 117 contextes où cet auteur parle du vice en connaisseur. Si
l'on propose un mot moins courant, comme erotic, la base entière
sera explorée en quelques secondes pour livrer le résultat
de la figure 12. Les 120 contextes qui contiennent ce mot sont alors restitués
dans la présentation kwic devenue très courante. À
chacun une ligne est réservée qui est sensible au clic de
la souris, en ouvrant une fenêtre sur le dictionnaire.
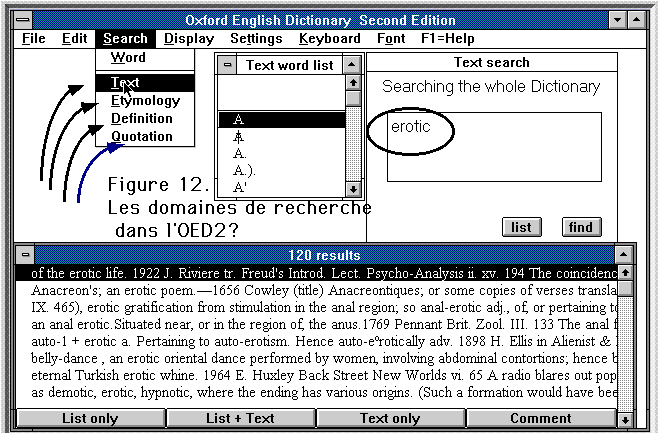
3 - On nous pardonnera de ne pas insister sur les vertus (non
plus que sur les vices, s'ils existent) de l'OED. Tout le monde
est conscient que l'OED dans sa version 2 représente l'exemple
le plus achevé que la lexicographie puisse offrir présentement
sur le marché du CD-ROM. Tout au plus peut-on observer que ce produit
est bon marché si on le compare au Robert, et plutôt
cher si on le confronte à Encarta et à certains CD-ROM
encyclopédiques. Mais que ne permet-il pas! Nous en donnerons un
ou deux exemples imprévus, qui font appel à la statistique.
Toute base de données correctement construite - et l'OED est de
ce nombre - peut restituer, mais aussi simplement décompter, les
enregistrements qui satisfont aux critères d'une requête donnée.
On peut se contenter de ces effectifs et construire sans trop d'efforts
un tableau à deux dimensions où les lignes seront constituées
par les mots différents et les colonnes par les rubriques intéressées.
En suivant la mauvaise pente où les mots
vice et erotic
nous ont entraîné, nous ajouterons les mots sexual
et porno à notre méchante série. Voici les
résultats exploitables:
texte étym. définit. citation
sexual 1758 30 770 774
erotic 120 6 32 75
porno 20 1 1 15
On a écarté le vice pour s'en tenir à la
même catégorie grammaticale. Nul besoin de calculer de savants
écarts réduits pour rendre compte de la réserve que
les rédacteurs opposent aux mots trop violemment marqués.
Les auteurs auxquels les citations sont empruntées n'ont pas la
même pudeur, puisque 15 emplois se rencontrent dans les citations
pour le mot le plus inavouable de la série, auquel le minimum est
accordé dans la définition (1 mention seulement)[3].
Plus sérieusement on peut s'intéresser à l'étymologie
pour laquelle l'OED offre une grille particulière, représentée
dans le graphique 13. Comme dans les autres champs, on a accès à
la graphie (dans différents jeux de caractères) ou, grâce
aux jokers, à un modèle de production, mais on dispose aussi
d'une rubrique propre qui mentionne la langue en question. C'est l'occasion
de vérifier si de l'autre côté de la Manche on parle
aussi franglais. L'effectif relevé pour le français et fourni
par la figure 13 (37032 étymologies) prend sens si on le rapproche
de ceux qu'on obtient pour les autres langues[4]:
french latin greek german american
language 37022 50725 18675 12322 --
text 10634 4565 4087 4502 8005
definition 1755 1330 1261 940 2393
citation 6708 1797 2234 2670 4694
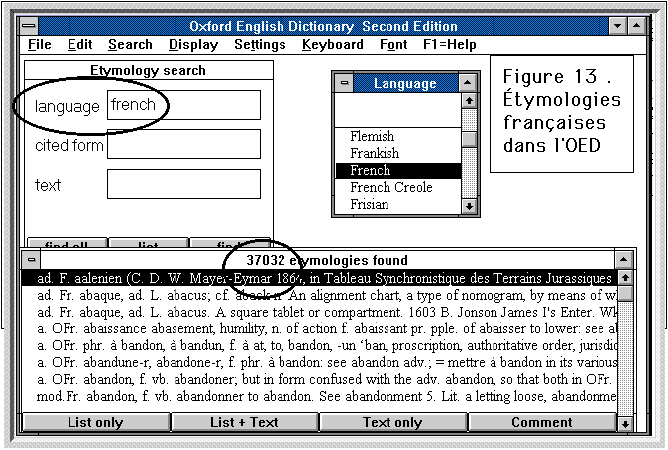
Le résultat est flatteur pour le sentiment national: avec
un effectif de 37022, les sources françaises ont un débit
trois fois supérieures aux germaniques. Le mot french l'emporte
aussi sur tous les autres, pour sa fréquence dans le texte des articles,
et surtout dans les citations - ce qui est un phénomène de
culture et de civilisation plutôt que de langue proprement dite.
Reste à savoir si le mot est pris en bonne ou mauvaise part, question
qu'il est imprudent d'approfondir.
Bien d'autres approches sont possibles qui prennent appui sur
le codage grammatical, comme dans la figure 14, ou sur la datation (figure
15).
Figure 14. Les parties du discours dans l'OED
Fugure 15. Interrogation de l'OED sur la date des citations
- IV -
On pourrait s'en tenir là: prendre l'OED pour modèle
et le transposer en français. Ce serait oublier que l'OED
est en mouvement, qu'il en est à sa seconde version et que déjà
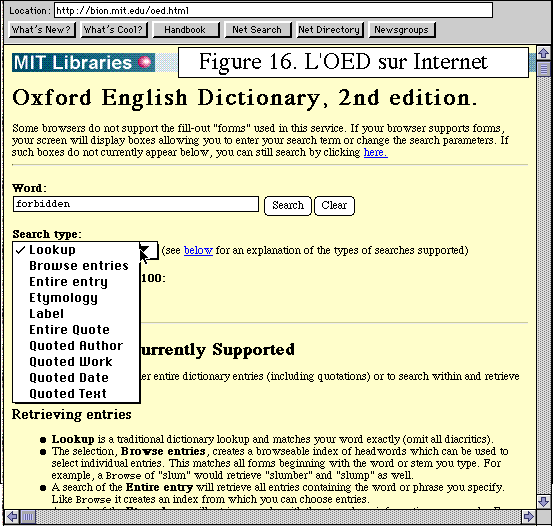
une troisième est à l'épreuve sur Internet. Nous n'avons
pu l'expérimenter, faute de posséder la clé dont jouissent
certaines universités américaines ou canadiennes. La tentative
a avorté que nous avons tentée sur le serveur du MIT. Méfiant
sur la validité de notre passeport, nous avions proposé le
mot forbidden à l'interrogation, comme précisé
dans la figure 16. Nous avons obtenu le message FORBIDDEN avec le refus
du mot demandé - dont nous ignorerons à jamais la signification.
1 - L'accès par Internet au TLFI (Trésor de la Langue
Française Informatisé) est par contre ouvert, au moins pour
la partie traitée (le tome 14). Il ne s'agit encore que d'un prototype,
livré à l'appréciation du public scientifique et non
nécessairement fixé dans son état définitif.
L'adresse WEB est celle de FRANTEXT, soit
http://www.ciril.fr/~mastina/FRANTEXT
Si Frantext exige un abonnement préalable, aucune souscription
n'est exigée pour le TLFI et l'on est conduit tout de suite au menu
principal représenté ci-dessous:
Figure 17. Le TLFI sur le WEB

Le niveau d'utilisation le plus élémentaire consiste
à tourner les pages comme on ferait pour la version papier. Le premier
item du menu principal (Visualisation simple d'un article) ouvre
le dictionnaire à la page qu'on veut (du tome 14). L'article recherché
apparaît avec la typographie originale, seuls étant ajoutés
des boutons de navigation qui permettent d'explorer les articles trop longs
pour être visibles sur un seul écran.
Figure 18. Consultation simple du TLFI

Ce mode de consultation n'est pas à dédaigner. Si l'on
dispose d'un poste d'interrogation relié en permanence à
Internet (c'est virtuellement le cas dans les universités ou dans
les bibliothèques), on évite ainsi la fatigue musculaire
qu'il faut déployer pour aller quérir le tome désiré
au haut de son rayonnage. Et pour peu que la recherche se promène
à différents endroits de l'alphabet, la peine en sera diminuée
et divisée d'autant. On gagnera aussi en rapidité de consultation
et même parfois en lisibilité. Car la taille des caractères
peut-être modifiée par Netscape pour plus de confort visuel,
alors que les contraintes de coût conduisent l'éditeur de
la version papier à la miniaturisation des caractères. La
fonction FIND du logiciel d'interrogation permet en outre d'explorer le
détail de l'article affiché. On appréciera plus encore
la possibilité d'imprimer ou de sauvegarder la sélection,
dans des conditions très supérieures à celles qu'offre
la photocopieuse.
2 - Mais l'avantage décisif est évidemment ailleurs,
dans la vue synthétique que le logiciel offre de toute la base.
Derrière un article, c'est tous les autres qu'on voit en perspective.
Apparaissent au premier rang ceux que le critère de tri a distingués,
selon une logique de sélection analogue à celle de l'OED.
Mais là où l'OED offrait une dizaine de types d'objets (voir
figure 16), le TLFI propose jusqu'à 35 objets différents,
dont les premiers alphabétiquement dont représentés
ci-dessous (figure 19).
Figure 19. Quelques-uns des objets de la recherche dans le TLFI

Outre ceux que mentionne la figure 19, les objets peuvent être
choisis parmi les domaines (techniques ou généraux), les
entrées (principales ou dérivées), les indicateurs
(grammaticaux, stylistiques ou sémantiques), les exemples et leur
source (auteur, titre et date), les synonymes et antonymes, et la segmentation
(paragraphe, syntagme). Cette variété des objets reflète
la complexité de la structure des articles, dont le lecteur, guidé
par la typographie, n'a pas toujours une exacte conscience. Il a fallu
aux rédacteurs beaucoup de discipline pour respecter cette structure,
d'un article à l'autre. Et il a fallu aux concepteurs de la base
beaucoup de perspicacité pour la mettre en évidence, après
coup, à travers le voile mi-transparent, mi-brouillé de la
typographie. Rarement la rétroconversion a offert autant de noeuds
à dénouer et d'ambiguïtés à dissoudre.
Sans doute a-t-il fallu quelques retouches manuelles pour parfaire les
traitements automatiques. Sans doute le chemin est-il encore long avant
que les 16 tomes soient traités comme le tome 14. Mais du moins
a-t-on la garantie qu'on ira au bout et qu'aucun obtacle rédhibitoire
ne peut plus obstruer le chemin.
Le résultat est presque trop beau et presque effrayant. Alors
qu'un article n'est jamais opaque dans un dictionnaire-papier, la structure
de l'article apparaissant immédiatement à l'oeil, presque
sans effort, c'est une rude opération intellectuelle qui est exigée
de l'utilisateur du TLFI, s'il veut tirer pleinement profit de la puissance
du moteur de recherche. Car il doit avoir une conscience aiguë des
différents éléments qu'on rencontre dans un dictionnaire
et de l'assemblage logique qui les constitue en article. On peut toutefois
se contenter, pour un premier contact, d'une question simple, qui porte
sur la date des exemples et qui permet de vérifier si oui ou non
le TLF rend compte d'un état de langue contemporain. On trouvera
ci-dessous la question (quels sont les articles qui contiennent un exemple
daté de 1960) et la réponse obtenue, d'abord sommaire (figure
20), puis détaillée selon la précision souhaitée,
le choix étant offert entre la visualisation globale et juxtaposée
(figure 21) et le "zoom" sur un exemple pleinement développé
(figure 22).
Figure 20. Exemple d'interrogation simple
(un seul objet, un seul contenu)
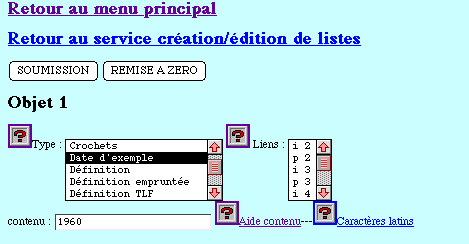

Figure 21. Visualisation globale
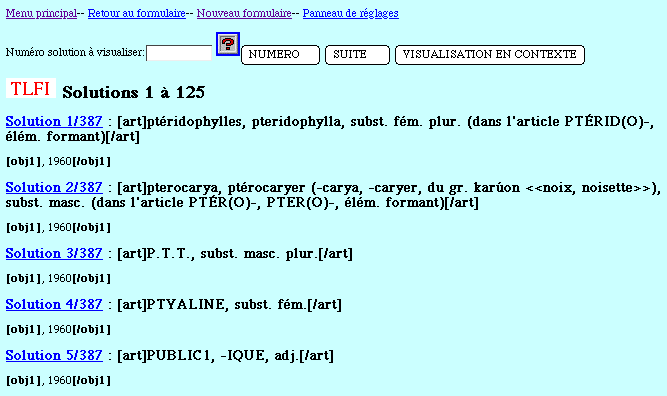
Figure 22. Affichage détaillé

En renouvelant la même question pour toutes les années,
on obtient une série inégale où les années
ne pèsent pas le même poids. De même que les exemples
de Littré montrent une préférence marquée pour
la langue du grand siècle, de même les rédacteurs du
TLF semblent avoir puisé leurs illustrations avec un goût
prononcé pour le XXe siècle. Sans doute leur était-il
interdit de faire appel à des textes antérieurs à
la Révolution, puisque la base était alors limitée
aux deux derniers siècles et de fait aucun exemple n'est daté
d'avant 1780. Mais les textes les plus éloignés dans le temps
leur ont paru donner une image déformée et vieillie de la
langue contemporaine et un appel très circonspect est fait à
la génération romantique comme à celle qui a suivi.
Mais inversement les textes les plus récents n'ont pas paru leur
offrir une garantie suffisante et ils ont préféré
la sécurité et l'authenticité que donne un recul raisonnable,
de l'ordre du demi-siècle. En adoptant le pas de la décennie,
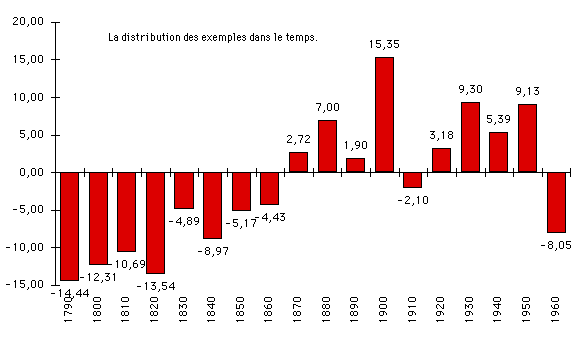
on obtient la distribution suivante:
1800 1810 1820 1830 1840 1850 1860 1870 1880 1890
667 405 803 1844 1750 1455 1739 1783 1964 1850
1900 1910 1920 1930 1940 1950 1960 1970 1980 1990
2047 1684 3346 4393 3054 2683 2610 969 575 4
Sans doute les textes du corpus sont-ils plus nombreux dans les tranches
qui ont recueilli les suffrages des rédacteurs et une pondération
est nécessaire. La courbe obtenue après pondération
n'en est pas moins très claire. Voir figure 23.
Figure 23. Distribution des exemples par décennie dans le TLFI
(données pondérées)
Sans doute s'agit-il du tome 14, l'un des derniers de la série.
Le centre de gravité se situerait-il au même endroit si l'on
avait considéré le tome 1, dont la rédaction est antérieure
de vingt ans? Au moins peut-on là-dessus faire la comparaison avec
l'OED, dont l'empan est plus large puisque ce dictionnaire historique rend
compte de la langue anglaise dans son ensemble, des origines à nos
jours. Un sondage au dizième (en ne retenant qu'une année
sur 10) est suffisant pour constater l'étalement des références
dans le temps.
Figure 24. Distribution des exemples de l'OED
(données brutes, lissées par la méthode de la moyenne
mobile)
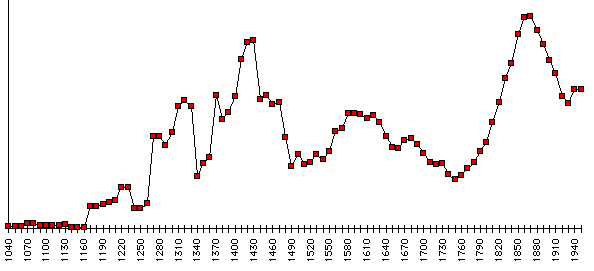
Les rédacteurs de l'OED retiennent nécessairement
les exemples anciens, puisque pour chaque mot le dictionnaire note la première
apparition et restitue les traces des variations que la langue anglaise
a subies au cours des siècles, notamment durant la longue période
de gestation qui va de la conquête normande à la guerre de
cent ans. L'époque de Shakespeare se reconnaît à un
palier haut aux alentours de 1600 mais le sommet de la courbe est atteint
à la fin du XIXe siècle. Aucun corpus préalable n'étant
imposé, le choix des exemples n'est pas canalisé et le choix
des rédacteurs reflète l'évolution de la langue.
3 . Cette comparaison montre que beaucoup de traitements sont
communs à l'OED et au TLFI, ce dont il faut se réjouir. Cependant
la formalisation et l'unification de ce dernier ont été poussées
plus loin. Et par voie de conséquence la puissance et la sophistication
des requêtes y sont nettement plus développées. L'OED
ne distingue guère que les grandes divisions de la structure des
articles: l'entrée, l'étymologie, la définition et
les citations, chacun de ces niveaux ayant une sous-structure. Ainsi l'entrée
se décompose en entrée simple, complexe, secondaire, phonétique,
à quoi s'ajoutent la date de la première apparition et le
code grammatical. L'étymologie propose pour sa part trois champs
de recherche et les citations ou exemples quatre rubriques distinctes:
la date, l'auteur, le titre et le texte. Pour croiser plusieurs requêtes,
un langage est proposé qui utilise les opérateurs booléens
et un jeu assez riche de mots-clés, d'abréviations et de
fichiers-résultats. Tout langage exige un apprentissage et dans
le cas de l'OED la maîtrise des procédures ne va pas sans
effort.
L' interrogation du TLFI se fait par le canal du WEB, avec les
ressources ordinaires du langage html et du "navigateur" (par exemple Netscape
ou Mosaic dans leurs versions passe-partout). Sans doute pourrait-on solliciter
les fonctions avancées que proposent Java et Javascript, si elles
étaient stabilisées et disponibles sur tous les postes d'interrogation,
ce qui n'est pas le cas actuellement. Le TLFI se contente donc des simples
formulaires du langage HTML. Mais il les superpose en établissant
entre eux des liens complexes, en sorte que la question posée qui
en résulte peut être aussi précise et aussi sophistiquée
que l'on veut. Les critères de sélection peuvent porter en
même temps sur l'entrée, le domaine, l'auteur, le code grammatical,
l'indicateur stylistique, la date, et bien d'autres éléments
de la structure, chacun étant pourvu d'un champ à remplir
où l'usager précise le "contenu" de ce qu'il cherche. Il
y a évidemment quelques contraintes: si l'usager ignore la liste
des domaines, des indicateurs ou des codes grammaticaux, ou s'il propose
des événements pour des dates, le résultat sera incertain.
Un innocent qui n'aurait jamais ouvert une page du TLF risque de se perdre
et de ne pas remplir correctement les zones du contenu. Mais il est si
facile de lire d'abord un ou deux articles, comme celui de la figure 18,
et de se familiariser avec la structure du TLF, que les bonnes questions
viendront vite avec l'expérience. Les bonnes réponses suivront
si l'on franchit la difficulté majeure, qui est relative aux liens.
Le programme prévoit deux sortes de liens pour unir deux ou plusieurs
formulaires:
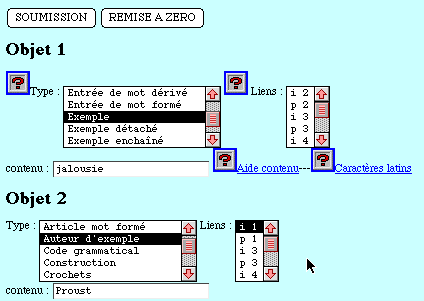
- dans le premier cas l'objet x est inclus dans l'objet y. Ainsi,
si l'objet 1 recherche le mot jalousie dans les exemples de la base,
et si l'objet 2 circonscrit la recherche d'exemples à un auteur
unique, par exemple Proust, il faudra lier la seconde contrainte au premier
critère, afin d'obtenir un résultat croisé qui mentionne
les exemples, tirés de Proust, qui contiennent le mot jalousie.
L'inclusion (marquée par le choix i 1 de l'objet 2) se justifie
par le fait que la rubrique auteur fait toujours partie de la rubrique
exemple.
Voir figure 25.
Figure 25. Les exemples de Proust contenant le mot jalousie
(Question et réponse)

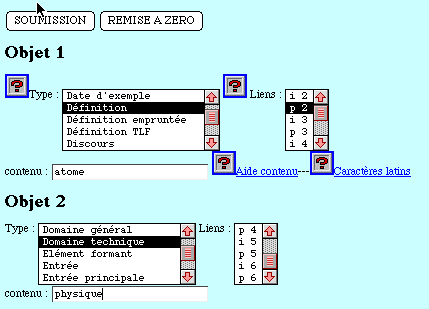
- dans le second cas la contrainte est plus molle, l'objet x est supposé
être dans la portée de l'objet y. Si par exemple on s'intéresse
uniquement à un domaine du savoir, par exemple la physique, on pourra
relever toutes les définitions où intervient nommément
l'atome. On aurait alors deux formulaires ainsi ordonnés
(si on inverse l'ordre, le lien p 2 deviendra p 1):
objet 1 - type "définition" - contenu "atome"
- lien "p 2"
objet 2 - type "domaine technique" - contenu "physique"
Figure 26. Les mentions de l'atome dans les définitions
des termes de physique
(Question et réponse)

Il faut veiller à ce que l'objet qu'on isole dans chaque
formulaire ait au moins un lien avec les autres. Ce lien peut être
inopérant et aboutir à une intersection vide, mais il doit
être établi formellement. Dans tous les cas la fonction logique
est celle du et, jamais du ou. Et cela se produit notamment
lorsqu'un même objet est lié à la fois à deux
autres (ou à plusieurs). Dans cette situation les résultats
délivrés devront satisfaire à la triple contrainte:
par exemple pour épingler les citations empruntées à
Céline (1), appartenant au domaine médical (2) et au registre
populaire (3), on devra lier l'objet 1 aux deux autres par les relations
p
2 et p 3.
La seule difficulté est de savoir quand il y a lieu d'envisager
la relation d'inclusion plutôt que celle de "portée". Dans
la pratique l'inclusion trouve à s'employer dans les structures
fortes comme celle de l'entrée (qui comporte toujours un code grammatical)
ou de l'exemple (auquel sont associés, un auteur, une date et une
localisation). La portée s'applique plutôt aux types d'objets
flottants qu'on peut rencontrer à différents niveaux. Les
indicateurs et les domaines sont de ce type.
Quant au contenu, ce n'est pas nécessairement un mot unique.
On peut y placer une locution, une liste de mots, une cooccurrence et y
ajouter des paramètres de placement, relativement au début
ou à la fin de l'objet textuel exploré. Les opérateurs
qui ont cours dans les meilleurs systèmes documentaires et qui ont
fait le succès de Frantext s'appliquent ici à la définition
du contenu pour exprimer les schémas les plus divers: négation
(&n ou
^), conjugaison (&c), lemmatisation
(&m), joker (&q), cooccurrence (|), distance (&d
et
&f), liste (&l). Il y a là tant d'outils disponibles
qu'on ne sait plus lequel choisir. Mais nul n'est tenu à la virtuosité.
L'usage minimal est proposé par défaut, et l'on peut fort
bien s'en contenter en ignorant jusqu'à l'existence des fonctions
complémentaires. De même l'OED se livre à l'exploitation
simple, sans exiger la connaissance d'un langage d'interrogation sous-jacent,
réservé aux spécialistes. Pour apaiser la frayeur
des néophytes peut-être eût-il été judicieux
que le TLFI réduise à un ou deux le nombre initial de formulaires,
quitte à fournir un supplément à ceux qui en feraient
la demande.
Verra-t-on tout cela sur l'étroite surface d'un CD-ROM? Comment
y engranger tant de liens entrecroisés dans le TLFI, tant de fichiers
associés, tant de fonctions cumulées? La réponse est
négative dans le temps présent. L'OED a eu besoin de tous
les octets disponibles sur la surface optique et aucun des 632 Mo n'a été
gaspillé. Mais une mutation technique se prépare qui mettra
bientôt à la disposition du public un CD-Rom nouveau, DVD
ou Digital Video-Disc, dont la capacité sera multipliée,
ainsi que le débit de transmission. On parle de 3 à 10 milliards
d'octets. C'est assez pour contenir en même temps le TLFI
et Frantext et bien d'autres choses encore. Et déjà
bleuit l'horizon où l'on devine les premières lueurs du laser
bleu. Ici comme en d'autres circonstances la technique informatique comblera
son retard avant que les données soient prêtes et les outils
fabriqués.
|








