|
Sergio Bolasco
Faculty of Economy University of Rome "La Sapienza"
Via del Castro Laurenziano, 9 - 00161 Roma - Italy
Meta-data and Strategies of Textual
Data Analysis :
Problems and Instruments
V International Conference of IFCS - Kobe, 27-30 march 1996, Japan
Proceedings in :
Data Science, Classification and Related Methodes,
Springer-Verlag, Tokio 1997
Summary : In order to develop a proper multidimensional
content analysis, we discuss some typical aspects of a pre-treatment
of a textual data analysis. In particular: i) how to select the peculiar
subset of the words in a text; ii) how to reduce the word ambiguity. Our
proposal is to use both frequency dictionaries and reference
lexicons as external lexical knowledge bases with respect to the corpus,
by means of a comparison of ranking, inspired by Wegmans parallel coordinate
method. The conditions of iso-frequency of unlemmatized forms as
an indication of the need for lemmatization is considered. Finally in order
to evaluate the opportunities of the choices (both disambiguations and
fusions), we propose the reconstruction, by means of bootstrapping strategy,
of some convex hulls - as word confidence areas - in a factorial plane.
Some examples from a large corpus of parliamentary discourses are presented.
1. Introduction
In this paper we are concerned with the different phases of text pre-treatment
necessitated by a content analysis, based on multidimensional statistical
techniques. These phases have been modified in recent years by the growth
in sizes of textual data corpora and their related vocabularies and by
the increased availability of lexical resources.
As a consequence of this, some new problems arise. The first one is
how to select the fundamental core of the corpus vocabulary, when
it is composed of several thousands of elements. In other words how to
identify the subset of the characteristic words within a text, regardless
of their frequency, in order to optimize computing time and minimize interpretation
problems. The second problem is how to reduce the ambiguity of language
produced by the automatic treatment of a text. The main aspects of this
are the choice of the unit of analysis and of lemmatization.
We also propose the validation of the lemmatization choices in terms
of the stability of the word points on factorial planes in order to control
the effects of this preliminary intervention.
To solve these problems, it is possible to use both external and internal
information, concerning the corpus: i. e. both meta-data and data. Some
examples of our proposals are applied to a very large corpus of parliamentary
discourses on government programmes (called Tpg from now on). The size
of the Tpg corpus (Tpg Program Discourses and Tpg Replies) is over 700.000
occurrences and the size of the Tpg vocabulary it is over 28.000 unlemmatized
words, equivalent to 2500 pages of text.
2. - How to identify the fundamental core of the corpus
vocabulary
Regarding the first problem, frequency dictionaries and reference
lexicons play a crucial role as external lexical knowledge bases. The
former can be represented as being several models of language. Just
as a reminder a frequency dictionary is a vocabulary ranking by decreasing
of headword frequency obtained by means of a very large corpus (at least
one million occurences); this corpus is a representative sample of texts
from some collections of the language. A reference lexicon is a complete
inventory of the inflected forms or of any other collection of locutions
or idiomatic expressions.
We can assume that every textual corpus (as discourse) is the reflection
of an idiom, a context and a situation (i. e.: enunciation
and historical period). So its vocabulary cannot but come out of these
three components.
The idiom is identifiable through the base-dictionary of a given
natural language. In Italian this base-dictionary is represented by a VdB
of around 7000 most frequent words in everyday language (or the 2000 most
frequent words in LIF, see Bortolini et al. 1971).
Some of the words of the corpus which belong to the VdB, in some cases,
could be eliminated from the analysis inasmuch as they are necessary only
to the construction of sentences (for instance the grammatical words).
Words such as support-verbs or idiomatic phrases can be clearly identified
and their capture will contribute to the reduction of ambiguity. This capture
is possible by means of a reference lexicon of locutions and phrasal verbs.
For example, if we look at the Italian verb <andare> (to go, in English),
we will see in tab. 1, from a reference lexicon, that there are over 200
different phrasal verbs that use this verb as support. Of these, of course,
almost half do not exist or do not have an equivalent in English.
Tab. 1: Examples of idioms of the verb "andare" (to go ) as phrasal
verb
andar/bene/VAVV/V/DIGE/DCM541/ = >be/a/good/match/VDETAGGN/V
andare/a gli/estremi/VPN/V/DIGE/DCM693/ = go/to/extremes/VPN/V
andare/a/fare/la/spesa/VPVDETN/V/DIGE/DCM980/ = go/shopping/VAVV/V
andare/a/giornata/VDETN/V/DIGE/DCM721/ = go/out/to/work/by he/day/VPVPN/V
andare/a/male/VPN/V/DIGE/DCM654/ = go/bad/VAVV/V
andare/a/spasso/VPN/V/DIGE/CTS/ = go/for a/walk/VPN/V
andare/a/zonzo/VPN/V/DIGE/DTA/ = saunter/V/V
andare/avanti/VAVV/V/DIGE/DCM562/ = progress/V/V
andare/direttamente/a lo/scopo/VAVVPN/V/DIGE/DCM661/ = go/straight/to
he/mark/VAVVPN/V
andare/fuori/uso/VPN/V/DIGE/DCM1027/ = wear/out/VAVV/V
andare/fuori/VAVV/V/DIGE/DCM1026/ = get/out/VAVV/V
andare/fuori/VAVV/V/DIGE/DCM1026/ = go/out/VAVV/V
andare/fuori/VAVV/V/DIGE/DCM1026/ = set/out/VAVV/V
andare/oltre i/limiti/VPN/V/DIGE/DCM827/ = overstep/the/limits/VDETN/V
andare/per la/maggiore/VPAGG/V/DIGE/GV/ = be/very/popular/VAVVAGG/V
andare/smarrito/VAGG/V/DIGE/DCM966/ = go/astray/VAVV/V
andare/smarrito/VAGG/V/DIGE/DCM966/ = miscarry/V/V
andare/smarrito/VAGG/V/DIGE/DCM966/ = mislead/V/V
andare/sotto il/nome/di/VPNP/V/DIGE/GV/ = go/by the/name/of/VPNP/V
and so on, with over 200 different examples in Italian
language and at least other 40 phrasal forms of "to go" in English
The context and the situation are characterized with the aid of a specialized
frequency dictionary (political, scientific, or economic, etc.). In this
event, the lexical inclusion percentage of the corpus vocabulary in the
reference language model is a basic measure.
With regards to the Tpg, the chosen frequency dictionary is the lexicon
of Press and Press Agencies Information (called Veli). This vocabulary
is derived from a collection of over 10 million occurrences. On the assumption
that the Veli vocabulary is the pertinent neutral model available of a
formal language in social and political context, we can ask ourselves to
what extent the Tpg corpus resembles it, or differs from it.
In this sense the situation can be identified by studying the
original terms not included in this external knowledge base. In our case,
the language of the situation is composed of the Tpg terms which does not
belong to the Veli. This sub-set is interesting in itself.
On the contrary, the context can be identified through the words
in common in the above two lexicons. Among these words, in general,
the highly specific sectorial terms are measured by the largest diversities
of use with respect to the chosen frequency dictionary.
In this way we are interested to identify one sub-set of characteristic
words. The peculiarity or intrinsic specificity of this sub-set will be
measured by calculating the diversities of use for each pair of words.
As Lyne says (1985: 165): "The specific words are terms whose frequency
differs characteristically from what is normal. The difference can be calculated
from the theoretical frequency of a word in a given text, on the assumption
that the latter is proportional to the length of the text." One possible
measure of specificity could be the classical measure of z
- like a normalized difference of the frequencies -
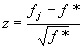
where: the 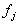 is the
relative number of occurrences in the corpus and is the
relative number of occurrences in the corpus and 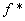 the correspondent in the frequency dictionary. Proposed by P. Guiraud in
1954, z usually is called écart reduit, and it is
equivalent to the square root of the chi square.
the correspondent in the frequency dictionary. Proposed by P. Guiraud in
1954, z usually is called écart reduit, and it is
equivalent to the square root of the chi square.
It is possible to compare the coefficients of usage between the two
vocabularies; where the latter is - for each headword - the frequency weighed
with the measure of dispersion.
The above specificity measure can be either positive or negative. Using
the Veli list as a yardstick, we can investigate the Tpg vocabulary. In
fact as Lyne suggests (ibidem: 1985: 7): "The ranking favours those
items which are most characteristic of our corpus, what we shall call,
Positive .. Items. Conversely, towards the bottom of this list are found
those items, Negative .. Items, which, although still occurring (in some
instances frequently) in our corpus, are nevertheless least characteristic
of it, since they occur relatively less frequently than in the reference
dictionary".
Once the relative differences between the Tpg and the Veli vocabulary
are measured in terms of z, it is possible to select and to visualize
two comparative rankings of words in the above vocabularies. The threshold
of selection can be the classical level of the absolute value of z
(greater than or equal to 3). The set of these selected words can be visualized
by using the method of "parallel coordinates" (Wegman, 1990). As known,
Wegman's proposal consists in using the parallel coordinate representation
as a high-dimensional data analysis tool. Wegman shows
that this geometry has some interesting properties; in particular a statistical
interpretation of the correlation can be given. For highly negatively correlated
pairs, the dual line segments in parallel coordinates tend to cross near
a single point between the two parallel axes. So the level of correlation
can be visualized by means of the set of these segments (see Wegman's fig.
3, ibidem: 666).
Generally, only two dimensions are considered (fig. 1a,b), but it is
possible to compare several (more than two) ranking lists from the related
frequency dictionaries (fig. 1c).
Figures 1 illustrate the above selected verbs according to whether they
occur more or less markedly in our Tpg corpus than in the Veli corpus.
In fig. 1a we show the 50 verbs with the highest positive specificity,
among these: <intendere>= to intend, <assicurare>= to assure, <impegnarsi>=
to involve, <provvedere>= to take measures, <favorire>= to favour,
<garantire>= to garantee; and also the other 50 verbs with the highest
negative specificity in our Tpg. Among them, there are several most commonly
used verbs like: <dire>= to say , <stare>= to stay, <fare>= to
do, <vedere>= to see, <parlare>= to talk, <venire>= to come, but
also <decidere>= to decide, <spiegare>= to explain, <andare>=
to go. As you can see the criterion of negative specificity can clearly
characterize certain words as "infrequent" words. In fact they are very
relevant in their "rarity" (under-used or not so frequent) with respect
to the chosen frequency dictionary, being consciously or unconsciously
avoided by the writer or speaker. Also this selection of terms could be
the subject of a study by itself.
In fig. 1b we show the group of words that are not specific,
also called "banal", and could be discarded, because not so relevant as
expressions of the context.
A further selection of items could be derived from the comparison of
3 ranking lists (Tpg - Veli - Lif). The figure 1c shows the first 15 most
common verbs and some specific Tpg Verb, as Positive or Negative Items.
From this illustration we can conclude that the most typical governmental
verbs, among the Positive Items, are "to take measures" and "to intend".
Conversely the most relevant among the negative ones, in comparison with
Veli and Lif, are "to explain" and "to decide". Finally it is possibile
to observe the situation of the same use, in the three dictionaries, of
the verbs "to assure", "to involve", "to insure" as a set of high politic
peculiarity due to their progressive ranking in the passage from the general
language (Lif) to the sectorial one (Veli) up to the more specific one
of government programs (Tpg).
3. How to solve problems of ambiguity
Regarding the two components, idiom and context, the corpus should be
analysed at the level of headwords (lemmas) and therefore needs
a lemmatization.
While with respect to the third component (situation) it is preferable
to analyse the corpus in terms of inflected forms such as graphical
unlemmatized forms, or, even better, through the choice of adequate
units of analysis (like lexias, as linguists call them. The lexias
is the minimal significant unit of meaning).
In general, if a whole sequence of words induces meaning (for example
an idiomatic expression), it can be regarded as a single lexical item,
and therefore as a single entry of vocabulary. If the frequency of the
related forms composing the sequence is particularly high with respect
to the chosen frequency dictionary, this reflects a highly peculiar terminology,
and we can conclude that this segment is very representative and has an
intrinsic specificity of its own in the corpus.
In all the above cases, the corpus vocabulary is both more precise and
unambiguous. Moreover, it permits us to circumscribe the subsequent phases
of lemmatization, that is disambiguation and fusion. A preliminary recognition
of names, acronyms and polyforms shortens the lemmatization phase, especially
from a semantic point of view. This requires the use of reference lexicons,
such as a dictionary of locutions and of the principal support-verbs (Elia,
1995). The Institute of Linguistics at the University of Salerno has developed
an integrated system of external lexical knowledge bases composed of the
following inventories: one lexicon of over 110.000 simple entries - derived
from a collection of 4 main dictionaries of the Italian language -, called
DELAS; one lexicon of over 900.000 inflected simple forms, called DELAF;
one lexicon of over 600.000 inflected polyforms, derived from 250.000 lexias,
called DELAC. It is also available one dictionary of over 800.000 bilingual
terms, called DEBIS. Elia's study show - for example - that in 13.790
simple forms there are 1.406 polyrhematic constructions (polyrhematic
is a sequence of terms whose whole meaning is different from its elementary
components), composed of 3.500 simple forms, equivalent to 25% of vocabulary.
As we can see the density of polyrhematic forms is very high.
Therefore it could be very important to construct some frequency
dictionaries of polyforms, in order to compare the corpus vocabulary
of repeated segments (Salem, 1987) or, even better, of quasi-segments (Bécue,
1995), and select those sequences that are more significant. Up to now
such frequency dictionaries are not available: an initial attempt to construct
one is illustrated here in tab. 2, concerning the adverbial
groups and other typical
Tab. 2: Example of Frequency Dictionary of Locutions derived from a
collection of over 2 million occurrences (among a total of 250 locutions
with occurrences > 30)
| ITALIAN WORD |
ENGLISH TRANSLATION |
|
|
|
Other Corpora
|
| |
|
|
|
|
|
| DA PARTE |
ON THE PART
OF |
855
|
227
|
368
|
260
|
| IN MODO |
IN THE WAY |
853
|
309
|
288
|
256
|
| IN ITALIA |
IN ITALY |
548
|
84
|
66
|
398
|
| PER QUANTO
RIGUARDA |
WITH REGARDS
TO |
511
|
237
|
136
|
138
|
| NON SOLO |
NOT ONLY |
477
|
176
|
119
|
182
|
| IN PARTICOLARE |
IN PARTICULAR |
453
|
270
|
100
|
83
|
| MA ANCHE |
BUT ALSO |
431
|
153
|
92
|
186
|
| IN TERMINI |
IN TERMS
OF |
429
|
92
|
94
|
243
|
| DI FRONTE |
IN FRONT
OF |
424
|
113
|
240
|
71
|
| PER CUI |
FOR WHICH |
421
|
19
|
34
|
368
|
| A LIVELLO |
AT THE LEVEL |
417
|
48
|
36
|
333
|
| SI TRATTA |
DEALS WITH |
384
|
170
|
127
|
87
|
| SUL PIANO |
ON THE LEVEL
OF |
373
|
167
|
141
|
65
|
| NELL'AMBITO |
IN THE CONTEXT |
368
|
149
|
132
|
87
|
| NEI CONFRONTI |
DEALING
WITH |
331
|
79
|
140
|
112
|
| SEMPRE PIÙ |
ALWAYS MORE |
330
|
176
|
45
|
109
|
| IN MATERIA |
ON THE SUBJECT |
321
|
143
|
160
|
18
|
| NEL QUADRO |
WITH THE
REFERENCE TO |
314
|
178
|
130
|
6
|
| NEL SENSO |
IN THE SENSE |
297
|
27
|
35
|
235
|
| IN CORSO |
ON GOING |
297
|
159
|
124
|
14
|
| SULLA BASE |
ON THE BASIS
OF |
277
|
153
|
102
|
22
|
| PER QUANTO |
IN AS FAR
AS |
273
|
61
|
37
|
175
|
| NEL CAMPO |
IN THE FIELD
OF |
273
|
107
|
76
|
90
|
| PER ESEMPIO |
FOR EXAMPLE |
259
|
35
|
74
|
150
|
| IN GRADO DI |
ABLE TO |
255
|
70
|
26
|
159
|
| IN MANIERA |
IN THE WAY |
248
|
36
|
31
|
181
|
| UNA VOLTA (da
disambiguare) |
ONCE, AT
ONE TIME,
ONCE UPON A TIME |
248
|
35
|
48
|
165
|
| AL FINE |
IN ORDER
TO |
202
|
166
|
31
|
5
|
expressions. Preliminary matching with the corpus under study allows
us to isolate the relevant parts of lexical items (either single or compound
forms) and constitutes a valid system of text pre-categorization.
An additional possibility for this disambiguation emerges from the data.
In every corpus it is possible to observe some equivalence of frequency
- I call it iso-frequency - among the inflected forms of the same
adjectives or nouns. See in tab. 3 some examples of adjectives like economic,
important and legislative.
Tab. 3: Examples of Iso-Frequency
--- not ISO-FREQUENT NOUNS --- ISO-FREQUENT ADJECTIVES
LEGGE (law) (s) 622
LEGGI (laws) (p) 208 (DS = 0.33) ECONOMICO (ms) 315 (DS = 0,77)
ECONOMICA (fs) 461
ECONOMIA (economy) (s) 262 ECONOMICHE (fp) 100
ECONOMIE (economies) (p) 35 (DS = 0.13) ECONOMICI (mp) 100 (DS =
1,00)
--- ISO-FREQUENT NOUNS
IMPORTANTE (s) 117
OBIETTIVO (purpose) (s) 243 IMPORTANTI (p) 116 (DS = 0,99)
OBIETTIVI (purposes) (p) 286 (DS = 0,85)
INTERESSE (interest) (s) 193 LEGISLATIVO (ms) 57 (DS = 0,84)
INTERESSI (interests) (p) 178 (DS = 0,92) LEGISLATIVA (fs) 68
LEGISLATIVE (fp) 53
LIVELLI (levels) (p) 110 LEGISLATIVI (mp) 58 (DS = 0,91)
LIVELLO (level) (s) 187-67=120 (DS = 0,91)
<a/livello> 48 LIBERA (fs) 58
<al/livello> 19 LIBERO (ms) 55 (DS = 0,95)
LIBERE (fp) 28
FORZA (force) (s) 105 LIBERI (mp) 25 (DS = 0,89)
FORZE (forces) (p) 259-166= 93 (DS = 0,88)
<forze politiche> 126 LOCALE
(local) (s) 80
<forze sociali>
40 LOCALI (local) (p) 195-90 = 105 (DS
= 0,89)
<enti-locali> 90
Legend: DS = occ A / occ B with occ A < occ
B
(s) singular (p) plural (ms) masculine and singular (fs)
feminine and singular
(mp) masculine and plural (fp) feminine and plural
This iso-frequency can be the first clue to their equivalent use and
meaning. On the contrary, in some cases, the lack of iso-frequency
among the inflected forms of the same headword (Bolasco, 1993) suggests
the need for disambiguation. In fact, this happens in presence of some
compound forms, especially where the incidence of the occurrences of simple
component forms is relevant. As you can see in words like <forza> (force)
and <livello> (level). For example when we take away the frequency of
the compound form of the word "level" (187) like "at (local) level" (48)
and "at level of" (19), we return to the presence of iso-frequency (120)
with the plural (110). As we will see later the differences among the inflected
forms can be the clue to their different meanings. This should be verified
by means of a bootstrapping approach.
4. Strategies for evaluating the lemmatization choices
For an optimal reconstruction of the main semantic axes of latent sense
in a corpus we can use, as is well known, correspondence analysis (Lebart
and Salem, 1994). Our objective, at this level, is to obtain stable representations.
To assess the opportunities that both the disambiguations and fusions offer,
we can test their significance by providing the factorial planes with confidence
areas (Balbi, 1995). This assessment procedure is
based on a bootstrapping strategy that generates a set of "word to subtext"
frequency matrices. We assume Balbis hypothesis which consists in generating
a large number B of contingency tables by resampling, with replacement,
into the original contingency table.
This set of bootstrapped matrices generates a three-way data structure;
which could be analysed for example by means of a multiway technique, for
constructing a reference matrix. A technique, such as STATIS, can be used,
see Lavit (1988). In our example, in order to optimize computing time,
the reference matrix is the average of these B matrices, due to the large
dimensions of the original matrix (786 x 46) and of the number of bootstrapped
matrices (B=200).
The stability of word points is graphically established by projecting
them, as supplementary points, into the first factorial plane computed
from a correspondence analysis of this reference matrix. Balbi proposes
to use the non symmetrical correspondence analysis (ANSC). We have attempted
this road but the results have not been comforting at level of interpretation.
We believe that, in general, it is more opportune use the analysis of the
simple correspondence analysis and only for special reasons the ANSC.The
resulting clouds of points (for each word) constitute the empirical confidence
areas, delimitated by a convex hull. The fig. 2 shows the convex hull regarding
the word <way> and its locution <in/the/way>.
In practice, if two or more convex hulls do not overlap, disambiguation
is absolutely necessary. See also, in fig. 3, the semantic disambiguation
of the word <sviluppo> (development) in three different meanings: the
first as "economic growth", the second as "progress" (in general political
sense: social or civil), and the third as some "specific technological
advance".
On the contrary, if the relative convex hull of different inflected
forms or of some synonyms are (strongly) overlapping or included, their
fusion is fruitful for the analysis.
Let me give some examples concerning these situations. In fig. 4a "stato_verb"
(equivalent to "been" in English) is clearly distant from "stato_noun"
("state"); but, conversely, the different unlemmatized forms (<stato/a/e/i>)
of "stato_verb" (see fig. 4b) have their convex hulls completely overlapped
and it is not important to distinguish them. Furthermore, if we look at
the two meanings of "stato_noun" - they are further distinguished (fig.
4a). <Stato_s1> like state or nation and <stato_s2> like status or
condition/situation (marital status, state of mind) have their relative
convex hulls separated.
In particular the latter does not overlap so much with the other synonyms
such as "condition(_2)" and "situation(_1)", as you can see in fig. 4c.
This shows how the use of these terms has changed over time in political
discourse. Paying particular attention to fig. 4a, these words are always
distant from state as the Italian State.
Now let me look at the significance and interpretation of convex hull
sizes and positions, as shown in the following scheme:
1) a small convex hull, and therefore closeness of points, means high
stability of representation but: a) when the points are located around
the origin of the axes, it means evenness of these items in the various
parts of the corpus, or b) when the points are in one particular quadrant
of the plane, distant from the origin, it means the item is very characteristic
and specific to some sub-set of the corpus. In this case, most of the time
we obtain convex hulls not so small as above, because the factor scale
of this region depends on the point distance from the origin (see the example
of Politics in fig. 5);
2) a large convex hull, that is with a wide dispersion of points, means
a not so strong stability of representation, and several different uses
of this word in the corpus, but: a) if we do not have overlapping convex
hulls, this means that the relative items have different meanings and that
their fusion is not pertinent or, in other words, that their disambiguation
is justified (see in fig. 4a the case of nation and status) or b) if, conversely,
we have overlapping convex hulls, this means irrelevant disambiguation
or justified fusion (factual synonyms).
In conclusion, having discussed how to identify the most significant
part of the corpus and how to construct a more restricted and highly peculiar
vocabulary composed of items with a high level of semantic quality, we
can now finally proceed to an accurate and proper content multi-dimensional
analysis, based on the above vocabulary, in which all the relevant units
of analysis, which I have called "textual forms", are considered
(Bolasco, 1993).
To this effect, such a vocabulary (see an example in tab. 4) will be
composed of the items which are: 1) not banal with respect of some model
of language (high intrinsic specificity or original terms); 2) significant
as a minimal unit of meaning (lexia): either headwords (verbs and
adjectives), or unlemmatized significant inflected forms (such as nouns
in the plural with different meaning from the singular, i.e. forza/forze),
or more frequent typical locutions and other idiomatic expressions (phrasal
verbs and nominal groups).
5. References
Balbi, S. (1995): Non symmetrical correspondence analysis
of textual data and confidence regions for graphical forms. In:
JADT 1995 Analisi statistica dei dati testuali, Bolasco, S. et al.
(eds.), II, 5-12, CISU, Roma
Bécue, M. et Haeusler, L. (1995): Vers une post-codification
automatique In: JADT 1995 Analisi statistica dei dati testuali,
Bolasco, S. et al. (eds.), I, 35-42, CISU, Roma
Bolasco, S. (1993): Choix de lemmatisation en vue de
reconstructions syntagmatiques du texte par lanalyse des correspondances.
Proc. JADT 1993, 399-410, ENST-Telecom, Paris
Bolasco, S. (1994): Lindividuazione di forme testuali
per lo studio statistico dei testi con tecniche di analisi multidimensionale.
Atti della XXXVII Riunione Scientifica della S.I.S., II, 95-103, CISU,
Roma
Bortolini N., Tagliavini C., Zampolli A. (1971): Lessico
di frequenza della lingua italiana contemporanea. Garzanti., Milano.
Dubois, J. et al. (1979): Dizionario
di Linguistica, Bologna: Zanichelli
Elia, A. (1995): Per una disambiguazione semi-automatica
di sintagmi composti: i dizionari elettronici lessico-grammaticali. In:
Ricerca Qualitativa e Computer, Cipriani, R. e Bolasco, S. (eds.),
112-141, Franco Angeli, Milano
Cipriani, R. e Bolasco, S., eds. (1995): Ricerca Qualitativa
e Computer. Franco Angeli, Milano
Lavit, Ch. (1988): Analyse conjointe de tableaux quantitatifs.
Masson, Paris
Lebart, L. et Salem, A. (1994): Statistique textuelle.
Dunod, Paris
Lyne A. A. (1985): The vocabulary of french business
correspondence, Slatkine-Champion, Paris
Salem, A. (1987): Pratique des segments répétés.
Essai de statistique textuelle. Klincksieck, Paris
Wegman, E. J. (1990): Hyperdimensional Data Analysis
Using Parallel Coordinates JASA, 85, 411, 664-675
|








