|
Ludovic Lebart
Ecole nationale supérieure des Télécommunications
(ENST) Paris
Statistical processing of responses
to open questions in survey analysis
Introduction
Today computer-readable media are becoming the most natural way of storing
textual information. Consequently, automatic processing of raw texts is
beginning to have new objectives: verification of data entry, data retrieval,
creation of typologies of texts as an initial exploratory step, comparisons
of sets of responses to open ended questions. The techniques that are discussed
below concerns this last family of applications. They are independent of
the actual language in which a text is written.
The procedures presented in this paper are based upon applying multivariate
descriptive techniques (such as correspondence analysis) to the analysis
of responses to open-ended questions. An international survey will serve
as an example.
The approach is principally meant to explore connections between
open and closed questions. Its purpose is to describe the contrasts among
several texts, whether these texts be original responses, or groupings
of responses based on closed questions from the same questionnaire. For
an open question and for different categories of individuals we obtain,
without pre-coding, the main features of the differences between responses:
graphical visualization of proximities between forms and categories of
respondents, overview of the similarities between various groups of respondents,
description of the associations between words.
Section 1 briefly recalls the main concerns of the researchers who are
interested in the statistical analysis of texts. Two large families of
approaches can be distinguished:
approaches based on form (stylometry, socio-linguistic analysis) and
approaches using both form and content (information retrieval, automatic
codification, analysis of the responses to open questions).
Section 2 is also a brief reminder of the advantages and limitations
of the use of open ended questions in sample surveys.
Section 3 is devoted to the choice and selection of the most relevant
statistical units (forms, segments, quasi-segments, lemmas), and to the
subsequent codification of the text.
These basic units allow to define the lexical and segmental tables
presented in section 4, together with the statistical tools of description
and visualization of these tables.
Section 5 deals with the selection of characteristic elements,
and with the usual strategy for analyzing responses to open ended questions.
1. Two series of Problems in the statistical analysis
of texts
Most applications of statistical techniques to textual data can be assigned
into one of the two following families of methods: stylometric methods,
based on the form of textual data, and global methods, using simultaneously
the form and the content of textual data.
1.1 Statistical models based on form
Authorship attribution, or determining the epoch of writing for a piece
of text whose origin is unknown, is a frequent concern in literature, political,
and historical sciences. Statistical analysis of textual corpora can often
contribute to solving these problems. A series of appropriate coefficients
has been proposed to describe distributions of vocabulary (cf. the pioneering
work of Yule 1944). Various indices aim at describing the richness and
the diversity of the vocabulary: The type-token ratio, the Simpson index,
the Yule characteristic. A general survey on stylometry is given by Holmes
(1985). A classical reference is the presentation, by Mosteller and Wallace
(1964) of a model for author-assignment of the 'Federalist Papers'. The
majority of methods uses mixed indices which are constructed according
to the length of words, the length of sentences, the frequencies of function
words, the diversity of vocabulary or the frequency distributions of words.
Multivariate exploratory analysis of textual data has notably contributed
to these approaches by systematic application of correspondence analysis
and classification techniques (for more details, and for examples of application
of these techniques, cf. Benzécri et al. 1981).
1.2 Statistical models based on content
On the other hand, there are domains which are mainly interested in the
content of textual corpora. Examples of these areas are documentary research,
automatic codification, and analysis of the responses to open questions.
Note that in these approaches too, the choice of a certain kind of form
may play a role, but only to complement (for example from a socio-linguistic
point of view) the analysis of the content.
Many different techniques have been developed in order to analyze the
content of a text. A major line of research involving statistical techniques
relates to Automatic Information Retrieval (Salton 1988), currently applied
to documentary databases. Although the concerns of Automatic Information
Retrieval and of the methods of textual analysis developed below are fundamentally
different, they share an array of statistical tools, among which, for example,
the techniques devoted to the automatic description of large sparse matrices.
A documentary data base may contain thousands of documents, and has to
satisfy in addition pragmatic demands (i.e., a high accuracy, low costs,
and well-defined user constraints). Within such a framework, it is possible
to use several tools to analyze the content: morpho-syntactic analyzers
which are the first step in understanding the text, automatic dictionaries,
and semantic networks in order to lemmatize and eliminate ambiguities in
the text.
Many of these methods, even the most efficient ones, use techniques
which are close to descriptive multivariate analysis of qualitative data
(Lebart et al. 1984). For example, Furnas et al. (1988) propose a technique
called 'Latent Semantic Analysis', which is close to a discrimination model
based on the first axes obtained through a 'singular value decompositions'.
Other authors focus on the relation between descriptive models and the
importance of visual representations of these models in the most synthetical
way possible (Fowler et al., 1991).
2. Open questions and closed questions
In sample surveys conducted in the field of marketing or for establishing
government statistics, open questions are seldom used, because analyzing
the responses is both difficult and costly. However in some cases the questions
have to be left in the open form, either for technical reasons or because
of the nature of the information sought after. Schuman and Presser (1981)
have a discussion of the comparisons between open and closed questions.
Open responses are particularly suited to statistical processing,
since the corresponding corpus is homogeneous (the topic is determined
by the open question), and rich in redundancies: free responses represent
hundreds or thousands of answers to a single question, and thus word repetitions
are far greater than in an ordinary text.
Three typical situations occur rather frequently for which an
open question is appropriate:
To economize on interview time (one open question can replace
long lists of items).
To probe responses to closed questions: the classical add-on
question is 'Why?' Explanations concerning a response that has already
been given must necessarily be provided in a spontaneous fashion. A battery
of items would suggest new ideas that could only mar the authenticity or
the sincerity of the explanation. The open question 'Why?' is the
only way to determine whether several groups of respondents have understood
the closed question in the same way. It is particularly important in multinational
surveys, because it furnishes insights as to possible semantic divergences
of the questions according to the language used.
To obtain a response that must be spontaneous (ex: what
is the main idea of this commercial? ).
The traditional techniques for processing open responses consist
in building a coding frame from a sample of responses and then coding the
whole set of responses, effectively replacing the open question by one
or several closed questions. Among the drawbacks of this (costly) pragmatic
procedure are: the subjectivity of the counts, loss of information in the
form, distortion of text's contents.
3. Which statistical units?
From the beginnings of textual analysis the choice of statistical units
has always been a problem. Statistics purports to study relationships that
may exist among frequencies computed on large sets of numerical data. Statisticians
have always tended to base counts on units that are readily accessible
to the computer. But in the tradition of the study of language, which has
been dominated by a purely linguistic point of view since F. de Saussure,
precedence has been given to a system assigning different values to each
unit within that system. This tradition is loath to consider as data entities
that were not created from an exclusively linguistic point of view.
3.1 Graphical forms
There are several ways of dividing up the units within the textual chain
in order to perform the counts that are used by data analysis algorithms.
The chosen basic unit is the graphical form defined as
a series of non-delimiting characters (blanks, periods, commas...). A single
word can generate several graphical forms, depending on its case or its
gender in the text; a single graphical form can also refer to several words
(e.g. bore refers to several nouns, and also to several verbs).
Such ambiguity is not a severe limitation, since the process will not treat
the forms separately.
3.2 Segments, quasi-segments
In statistics new variables are often constructed by combining nominal
variables that represent either the simultaneous occurrence of pairs of
categories or interaction effects. With textual data, we define larger
units composed of several consecutive graphical forms. The units that are
mostly used in practice are composite statistical forms called repeated
segments or more briefly, segments. These are sequences of simple
forms that appear with a frequency greater than a given threshold. Their
presence enhances the information provided by forms and helps to eliminate
ambiguities from their interpretation by introducing the context of these
forms in a natural way (Salem 1984). Special computational algorithms are
able to uncover such segments.
3.3 Lemmatization
A possible intermediate processing step (lemmatization) consists in consolidating
the vocabulary (i.e. declaring as equivalent all the graphical forms corresponding
to a same word) or cleaning out from the dictionary the auxiliary words
(articles, conjunctions, etc..). Experience has shown that this step complements
the use of graphical forms, but cannot be substituted to it. Different
graphical forms of one word can be linked to a particular context and a
particular content, and certain auxiliary words may characterize attitudes
or opinions in a typical fashion.
3.4 Coding text into numbers
The phase of coding consists of assigning each new graphical form to a
rank order number that is subsequently referred to in each occurrence of
this form. These numbers are recorded in a dictionary of forms, or vocabulary,
which is unique for each analysis. The dictionary is subsequently used
after the computations and for printouts to reconstitute the wording of
the forms that have been subjected to statistical calculations (see table
1 below).
Data analysts are accustomed to dealing with rectangular arrays
of nominal, ordinal, or numerical variables. Let us consider the case of
the set of responses to an open question. The usual techniques of multivariate
descriptive analysis of qualitative variables (simple and multiple correspondence
analysis, classification algorithms) provide visualizations of similarities
between
profiles of frequencies of graphical forms, that is with
vectors whose components are the frequencies of each of the forms occurring
in portions of text. These profiles contain a wealth of information.
More specifically, these techniques confine themselves to revealing
the differences between profiles of graphical forms and of segments.
Whereas the interpretation of a profile can be difficult (i.e. why does
a category of respondents use some words with a certain frequency?), the
interpretation of
differences is easier. Without speculating on
the meaning of the profiles, it is quite possible to observe that, for
instance, two groups of respondents have similar profiles, and that they
are very different from another group.
Frequency thresholds, used in the selection of forms and segments, make
it possible to implement several different levels of filtering on basic
data.
3.5 An example
The example that follows serves to illustrate the main steps of the statistical
processing.
The open question is the following:'What is the single most important
thing in the life for you ? It was followed by the probe: 'What
other things are very important to you ?'.
This question was inserted in the questionnaire of a cross-national
surveys conducted in five countries (Japan, France, Germany, United Kingdom,
USA) and the end of the eighties (Hayashi et al. 1992). Our illustrative
exemple is limited to the British sample (sample size: 1043). The context
of this cross-national survey about general social attitudes is
also described in Sasaki and Susuzi (1989).
In the same questionnaire, a number of closed questions were also
asked (among them, the socio-demographic characteristics of respondents,
playing a major role in the discussions that follow). We will focus in
this example on a partition of the sample in nine categories, obtained
through crossing the variable age (three categories) with the educational
level (three categories).
The reader will find several examples of responses to the open
question below, in table 4, which produces a selection of some characteristic
original responses.
Table 1. Forms Appearing at Least Sixteen Times (Alphabetic Order)
in the 1043 responses to the open question
Form Frequency Form Frequency Form Frequency
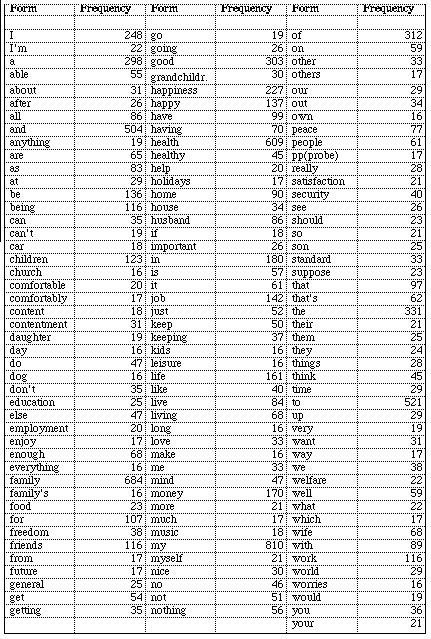
Table 1 shows the 136 forms that appear at least sixteen times in a
sample of 1043 responses to the question mentioned above. We notice the
presence of graphical forms such as can't, don't, that's, due to
the fact that the quote has not been considered as a separator in this
example.
The alphabetical ordering of the forms would make it possible to observe
the forms that are related to a single dictionary word (be, is, are,
being). Note the strong presence of auxiliary (or function) words (a,
and, for, that, the). As was stated earlier, the consolidation
and cleaning out are not essential in an approach that emphasizes differences.
If the auxiliary words are distributed in random fashion throughout
the various groups of individuals, they do not do much to perturb the results
of the exploratory statistical analysis (such as correspondence analysis,
see below). If on the contrary they are not random, then they are a possibly
interesting part of the analysis. In analogous fashion, if two graphical
forms refer to the same word, or behave identically, they can just as well
be replaced by this word. If they behave differently, the reason is that
they refer to different contexts of use of the word, which deserves to
be noted.
Table 2 shows the various segments observed for the responses
we are using as an example, sorted according to alphabetical order of the
first graphical form from which they are composed, and selected by using
frequency thresholds: segments of length two (two consecutive graphical
forms) are very numerous whereas they often add little from a semantic
point of view. They must appear at least 50 times in order to be included
in the inventory, whereas those of length three or more must appear at
least six times.
4. Construction and description of lexical and segmental
tables
The numeric coding of free responses can be completely transparent to the
user since the input data of the usual softwares are the raw responses
in their textual form. The result of this coding can summarized in a table
T. The table T has k rows (number of respondents, k = 1043 in our
example) and has as many columns as there are graphical forms (or segments)
used by the whole set of individuals, that is v columns (here, v = 136,
or v = 81, if we work with the segments). At the intersection of row i
and column j of table T is the number of times t(i, j) graphical form j
was used by individual i in his or her response. It is therefore an 'individuals
by forms' contingency table.
Table 2. Partial Inventory of Segments. (Global threshold: 6,
Treshold for '2-Segments': 50, Treshold for '3-Segments': 6)
Number Frequency Lenght Text of the Segment
--------------------------------------- (I)
1 10 3 I like to
--------------------------------------- (a)
2 54 2 a good
3 8 3 a good life
4 7 3 a nice home
--------------------------------------- (able)
5 52 2 able to
6 7 3 able to get
7 9 3 able to live
--------------------------------------- (as)
8 11 3 as long as
--------------------------------------- (be)
9 26 3 be able to
10 9 3 be happy to
--------------------------------------- (being)
11 23 3 being able to
--------------------------------------- (can't)
12 10 4 can't think of anything
13 8 5 can't think of anything else
--------------------------------------- (enough)
14 34 3 enough money to
15 16 4 enough money to live
16 9 5 enough money to live on
--------------------------------------- (family)
17 60 2 family health
18 73 2 family my
19 15 3 family and friends
20 11 3 family good health
21 7 3 family health happiness
22 13 3 family my health
23 10 3 family my job
24 9 3 family my work
--------------------------------------- (good)
25 176 2 good health
26 8 3 good health and
27 17 3 good health family
28 9 3 good health for
29 14 3 good health happiness
30 15 3 good health my
31 10 4 good standard of living
--------------------------------------- (happy)
32 13 3 happy family life
--------------------------------------- (have)
33 10 3 have a good
--------------------------------------- (having)
34 13 3 having enough money
35 8 4 having enough money to
In most applications, single responses are too poor and sparse to be
used in direct statistical processing: It is then necessary to work with
responses that have been grouped together on the basis of nominal variables
measured on the same individuals. Aggregating the k rows of T into m categories
of respondents leads to a contingency table C.
The table C will serve to compare the lexical (or segmental) profiles
of various segments of the population. These comparisons of profiles only
make sense from a statistical point of view if the forms appear with a
certain frequency: forms that only appear once (hapax) or rarely occurring
forms are removed from the phase of frequency comparisons. A suitable
threshold of frequency has the effect of reducing the size of the vocabulary
v.
In our example, for 1 043 responses, there are 13 669 occurrences, with
1 413 distinct forms. There are only 136 forms that appear at least sixteen
times (table 1). But these 136 forms correspond to 10 404 occurrences.
As a consequence of the strongly dissymmetric shape of the frequency distribution
of forms (Zipf 1935), 13 per cent of the distinct forms correspond to 76
per cent of the text.
Several tools are used to assist in interpreting aggregated
lexical tables: correspondence analysis, lists of characteristic forms,
and lists of modal responses (see section 5).
4.1 Correspondence analysis of lexical tables
Correspondence analysis techniques (Gutman 1941; Hayashi 1956, Benzécri
1973) are used to obtain descriptions of contingency tables (note that
in the contingency table C defined previously the 'individuals' are occurrences
of forms or segments, as opposed to respondents). Thanks to these techniques
it is possible to visualize the associations between elements (forms or
segments) and between groups of respondents or categories. Thus a visualization
of the proximities between words and categories can help understand the
responses of each of these categories.
Fig. 1 is a graphical display of the positioning of the forms shown
in table 1. It is issued from the correspondence analysis of the table
C
cross-tabulating the 136 forms (appearing at least sixteen times)
with
the nine categories of respondents obtained through the crossing
of the two variables: age (three categories) and educational
level (three categories).
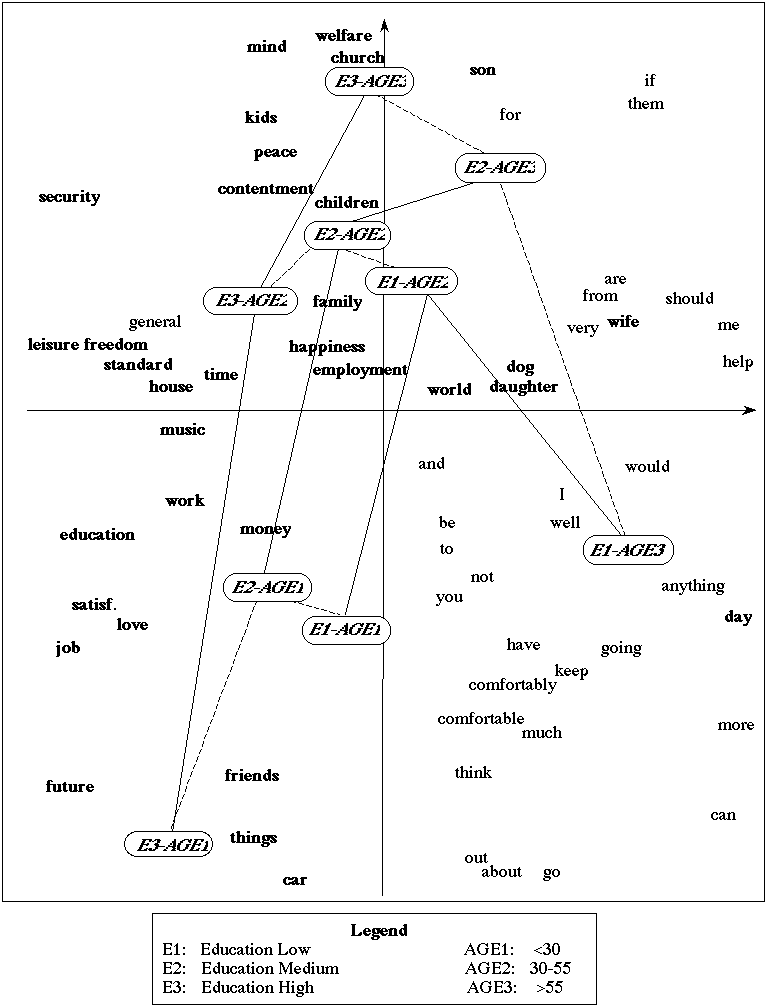
Fig. 1. Visualization of the Associations between Graphical Forms and
between Categories of Respondents through Correspondence Analysis. (Open-ended
Question: 'What is the single most important thing in the life for you?
'). Nouns (or forms used most frequently as nouns) are printed in bold
faced letters
On fig. 1, categories belonging to the same level of education
are joined by a bold line, whereas the categories belonging to a same class
of age are joined by a dashed line.
The superimposition of the displays of form-points and category-points
provides a help in the interpretations of proximities: the proximity between
two form-points can be explained in looking at the location of all the
category-points. The transition relationships (see Lebart et al. 1984;
Greenacre 1984) allow us to interpret the position of one form-point with
respect to all category-points (and vice-versa).
It can be seen on fig. 1 that the most educated categories are
positioned on the left hand side of the figure. They make use of
the words
security, leisure, freedom peace, mind, also appearing
on the left side of the graph.
The older categories are positioned on the upper right side of the graph.
If w except the group 'E1-AGE3' (Education: low, age>55), the educational
level increases from the right part to the left part, and the age increases
from the bottom to the top of the graph.
Fig. 1 also gives an example of the role of external information. Forms
belonging to a specific grammatical category, the nouns, are bold-faced.
It is clear that the nouns are not randomly scattered in this plane: they
are concentrated on the left hand side, characteristic of educated categories
(see, for instance, Somers 1966). This socio-linguistic result can be enhanced
through further modulations of the original display: the adjective, verbs,
pronouns could as well be identified. It can be seen that the verbs and
the personal pronouns are more frequent in the responses of old persons
with a low educational level. We can also enrich the graphical display
by identifying the forms according to some general semantic categories.
It appears for example that all the forms relating to the concept of family
(wife, husband, children, kids, son, daughter) characterize older
respondent, whatever their educational level.
4.2 Direct analysis of individual responses
If the responses are not grouped together, but appear to contain enough
material to be processed separately, a direct correspondence analysis of
the lexical table T which is a cross-tabulation of the graphical forms
and the responses can be conducted. Such an analysis produces a rather
coarse typology of responses, as well as a typology of words or of graphical
forms.
These typologies can be enriched by the characteristics of the respondents
as supplementary variables. This direct processing of the responses can
be followed by partially automated post-coding.
Note that the proximity between two graphical forms (i.e. between
two columns of table T) will be greater if the forms occur within the same
response (not only in the same text obtained through a grouping of responses).
Therefore, the direct analysis gives a better representationr of syntagmatic
proximities than the aalisis of the aggregate tables.
5. Characteristic units and characteristic responses
It is useful to complement the spatial representations provided by correspondence
analysis with a few parameters of a more probabilistic nature: the
specificities or characteristic forms.
5.1 The characteristic units
The characteristic units or specificities (Lafon 1980) are elements (forms
or segments) that are abnormally frequent or abnormally rare in the responses
of a group of individuals. Some softwares produce an exhaustive list of
characteristic forms for each grouping of individuals (table 3).
Probability levels (last column of table 3) are used to select these
characteristic forms. These probability levels measure the significance
of the differences between the relative frequency of a form within a group
(or a category) with its global relative frequency computed on the whole
set of responses or individuals. They are computed under the hypothesis
of a random distribution of the form under consideration in the categories.
The smaller are the probability levels, the more characteristic are the
corresponding forms.
The characteristic forms of table 3 assess some of the graphical
proximities given in fig. 1. The information is more precise, and easier
to read. However, the global overview of fig. 1 is missing. In this sense,
the two methods are complementary.
5.2 Selection of modal responses
The selection of characteristic responses (modal responses) makes it possible,
for each category under consideration, to extract from the large number
of responses collected certain single responses whose vocabulary use is
particularly typical of the category.
Table 3. Characteristic forms for six categories of respondents
Graphical Percentage Frequency Proba-
Form Within Global Within Global bility
Category 1: Age: -30 * Education: low
1 keep 2.27 .48 4. 50. .010
2 not 2.27 .49 4. 51. .011
3 standard 1.70 .32 3. 33. .018
Category 2: Age: 30-55 * Education: low
1 family 8.02 6.57 177. 684. .001
2 work 1.63 1.11 36. 116. .008
3 kids .36 .15 8. 16. .010
4 happy 1.81 1.32 40. 137. .017
5 children 1.63 1.18 36. 123. .021
Category 3: Age: +55 * Education: low
1 grandchildren .71 .29 19. 30. .000
2 I 3.46 2.38 92. 248. .000
3 as 1.43 .80 38. 83. .000
4 they .49 .23 13. 24. .003
5 can .64 .34 17. 35. .003
6 help .41 .19 11. 20. .005
7 your .41 .20 11. 21. .008
------------------------------------------------------------------------------
Category 7: Age: -30 * Education: high
1 friends 2.87 1.11 17. 116. .000
2 do 1.35 .45 8. 47. .005
3 want 1.01 .30 6. 31. .007
4 being 2.19 1.11 13. 116. .015
5 job 2.53 1.36 15. 142. .015
6 having 1.52 .67 9. 70. .017
7 things .84 .27 5. 28. .020
Category 8: Age: 30-55 * Education: high
1 the 5.74 3.18 36. 331. .000
2 of 5.10 3.00 32. 312. .002
3 job 2.71 1.36 17. 142. .005
4 church .64 .15 4. 16. .013
5 music .64 .17 4. 18. .020
Category 9: Age: +55 * Education: high
1 mind 2.55 .45 5. 47. .002
2 welfare 1.53 .21 3. 22. .008
3 peace 2.55 .74 5. 77. .015
The general principle is as follows: a response is a row of the
table T defined previously, or a vector with v components. If this response
is made up of ß different forms, only ß components out of v
are different from zero.A grouping of responses (for example, the responses
of young educated people) is a set of row-vectors, and the mean lexical
profile of this grouping is obtained by calculating the mean of the row-vectors
of this set. Therefore it is possible to compute distances between single
responses and a categorical grouping of responses. These distances must
express the difference between the profile of a response and the mean profile
of the group to which the response belongs. The distance between these
profiles of frequencies is chosen here to be the Chi-squared distance because
of its distributional properties.
Within each category of respondent, these distances can be ordered by
increasing size and thus the most representative responses can be selected
with respect to the lexical profile, those responses having the smallest
distances.
Another way of computing modal responses consists of associating
with each response the average probability level of the characteristic
forms it contains; if this average value is small, the response only contains
forms that are extremely characteristic of the category. Instead of using
the probabilities, it is customary to use the test-values (see e.g. Lebart
and Salem 1994), which provide an equivalent information, but easier to
use an interpret. Briefly, the test-value associated with a probability
level p is a standardized normal variable t corresponding to this level:
for example, a test value of t = 1.96 will correspond to probability level
p = 0.05. Empirically, the criterion of the average test-value to select
modal responses appears to be better than the criterion of the average
probability level.
Table 4 presents a series of modal responses for four extreme categories.
The three best responses are given for each category of respondents. It
is necessary to print several responses in order to span the main theme
dealt with in a specific category. Some modal responses are sometimes very
short or terse: they could be very typical of certain groups of individuals,
without nevertheless representing the contents of the responses of these
groups.
The words observed in fig. 1 and table 3 are now reinserted in
their original context. This blind selection of responses is clearly an
important contribution to a content analysis of the set of responses.
Table 4. Selection of the Three Most Characteristic Responses
(According to the Criterion of the Average Test-value) for Four Categories
of Respondents
Statistical Characteristic Raw Responses
Criterion
Age: -30 * Education: low
.851 - 1 family, employment
.742 - 2 family, work, money, have a good life
.702 - 3 keep a job, keep in clothing, transport, make sure family is
allright
Age: +55 * Education: low
1.506 - 1 good health, family, like to keep working for as long as I
can
1.229 - 2 health, as long as we are healthy, enough to live on comfortably,
enough to eat
.926 - 3 not being miserable, always like to help people if I can, looking
after my health
Age: -30 * Education: high
1.331 - 1 friends, friends, my homelife
1.109 - 2 being content, having enough money to do what you want to
do, within reason, having good friends, having a fulfilling job to do,having
some idea of what you want to do and the freedom to choose, protection
of the environment
1.046 - 3 to have good friends around, having a good job, living in
a good area, having lots of freedom to do the things you want to do
Age: +55 * Education: high
.966 - 1 togetherness, peace of mind, good health, religion.
.644 - 2 not to die, hygiene, peace of mind, don't like people
living envious of, each other
.631 - 3 peace of mind, good health, happiness, enough money to keep
a standard of living
Conclusions
The visualization of proximities between forms and categories, through
correspondence analysis of the aggregated lexical and segmental table (possibly
along with a similar mapping of the proximities between segments and categories),
gives an overview of the similarities between categories of respondents,
and a description of the associations between forms. The displays can be
enriched by the identification of forms according to their grammatical
and semantic categories.
The characteristic forms (or segments) highlight the most discriminant
elements (forms or segments) for each category of respondents.
The listings of modal responses summarize each of the main themes for
each category or for each part of text.
These three statistical tools provide the researcher with a new
material, built on objective basis, likely to help him or her to perform
a content analysis and/or a socio-linguistic analysis of the collected
responses.
We have confined ourselves in analyzing the British data extracted
from a much larger cross-national survey in which the same open question
is asked in three other languages.
In a subsequent step of the statistical processing of this international
survey, we compare the patterns (such as the configurations of category-points
in fig. 1) obtained in the different involved countries. A similar international
comparison has already been performed in the framework of another cross-national
survey (see Akuto 1992; Lebart 1995; Lebart and Salem. 1994). The possibility
to compare attitudes based on textual corpora in different languages opens
promising future research directions.
References
Akuto H. (1992) (ed.), International Comparison of Dietary Cultures,
Nihon Keizai Shimbun (Tokyo).
Benzécri J.-P. et al. (1973), L'Analyse des Données,
Vol. I, L'Analyse des Correspondances, Dunod (Paris).
Benzécri J.-P.et al (1981), Linguistique et Lexicologie,
Pratique de l'Analyse des Données, Tome 3), Dunod (Paris).
Fowler R. H., Fowler W. A. L., and Wilson B. A. (1991) - Integrating
query, thesaurus, and documents through a common visual representation,
Proceedings of the 14th Int. ACM Conf. on Research and Dev. in Information
Retrieval, Bookstein A. and al., Ed, ACM Press, (New York), 142-51.
Furnas G. W., Deerwester S., Dumais S. T., Landauer T. K., Harshman
R. A., Streeter L. A., and Lochbaum K. E. (1988), 'Information retrieval
using a singular value decomposition model of latent semantic structure',
Proceedings of the 14th Int. ACM Conf. on Research and Dev. in Information
Retrieval, 465-80.
Greenacre M.(1984), Theory and Applications of Correspondence
Analysis, Academic Press (London).
Guttman L. (1941), 'The Quantification of a Class of Attributes'.In
'The prediction of personal adjusment' (P.Horst ed.) SSCR (New York).
Hayashi C., Suzuki T., and Sasaki M.(1992), Data Analysis for
Social Comparative Research : International Perspective. North-Holland
(Amsterdam).
Hayashi C.'Theory and Examples of Quantification'. (1956) (II)
Proc. of the Institute of Stat. Math., 4 (2) 19-30 .
Holmes D. I. (1985), 'The Analysis of Literary Style' - A Review. J.
R. Statist.Soc., 148, Part 4, 328-41.
Lafon P. (1980), 'Sur la variabilité de la fréquence
des formes dans un corpus', Mots, 1, 127-65.
Lebart L. (1995), 'Assessing and Comparing Patterns in Multivariate
Analysis', In : Data Science an its Application, Escoufier et al. eds,
Academic Press (Tokyo), 193-204.
Lebart L.and Salem A.(1994), Statistique Textuelle, Dunod (Paris).
Lebart L., Morineau A., and Warwick (1984), Multivariate Descriptive
Statistical Analysis, J. Wiley (New York).
Mosteller F. and Wallace D. (1964), Inference and Disputed Authorship
: The Federalists. Addison-Wesley (Reading).
Salem A. (1984), 'La Typologie des Segments Répétés
dans un Corpus, Fondée sur l'Analyse d'un Tableau Croisant Mots
et textes', Les Cahiers d'Analyse des Données, Vol IX, 4, 489-500.
Salton G. (1988), Automatic Text Processing : the Transformation, Analysis
and Retrieval of Information by Computer Addison-Wesley.
Sasaki M. and Suzuki T. (1989), - 'New directions in the study
of general social attitudes : trends and cross-national perspectives',
Behaviormetrika, 26, 9-30.
Schuman H.and Presser F.(1981), Questions and Answers in Attitude
Surveys, Academic Press (New York).
Somers H. H. (1966), - 'Statistical methods in literary analysis',
The Computer and Literary Style, (J. Leed, Eds), Kent State University
Press (Kent).
Yule G.U.(1944), The Statistical Study of Literary Vocabulary,
Cambridge University Press, Reprinted in 1968 by Archon Books (Hamden).
Zipf G. K. (1935), - The Psychobiology of Language, an Introduction
to Dynamic Philology, Houghton-Mifflin (Boston).
Ludovic Lebart
Centre National de la Recherce Scientifique
E.N.S.T., 46 rue Barrault, F - 75013 Paris, France
email: lebart@eco.enst.fr
Phone: 33 1 45 81 75 59
Fax: 33 1 45 65 95 15.
Ludovic Lebart is 'Head of Research' at 'Centre National de la Recherche
Scientifique', Paris, France.
|








